
編者按:本文為「解碼 AI 」系列文章,以簡單易懂的方式解密 AI,並向 RTX 電腦的使用者展示新的軟硬體、工具與加速功能。
大型語言模型可快速理解、摘要及生成文字內容,正催生幾項人工智慧最令人雀躍的發展。
這些功能支援各種使用案例,包括生產力工具、數位小幫手,以及電玩遊戲的非玩家角色等。但是這種解決方案無法一體適用,開發人員為了符合應用方案需求,往往必須微調 LLM。
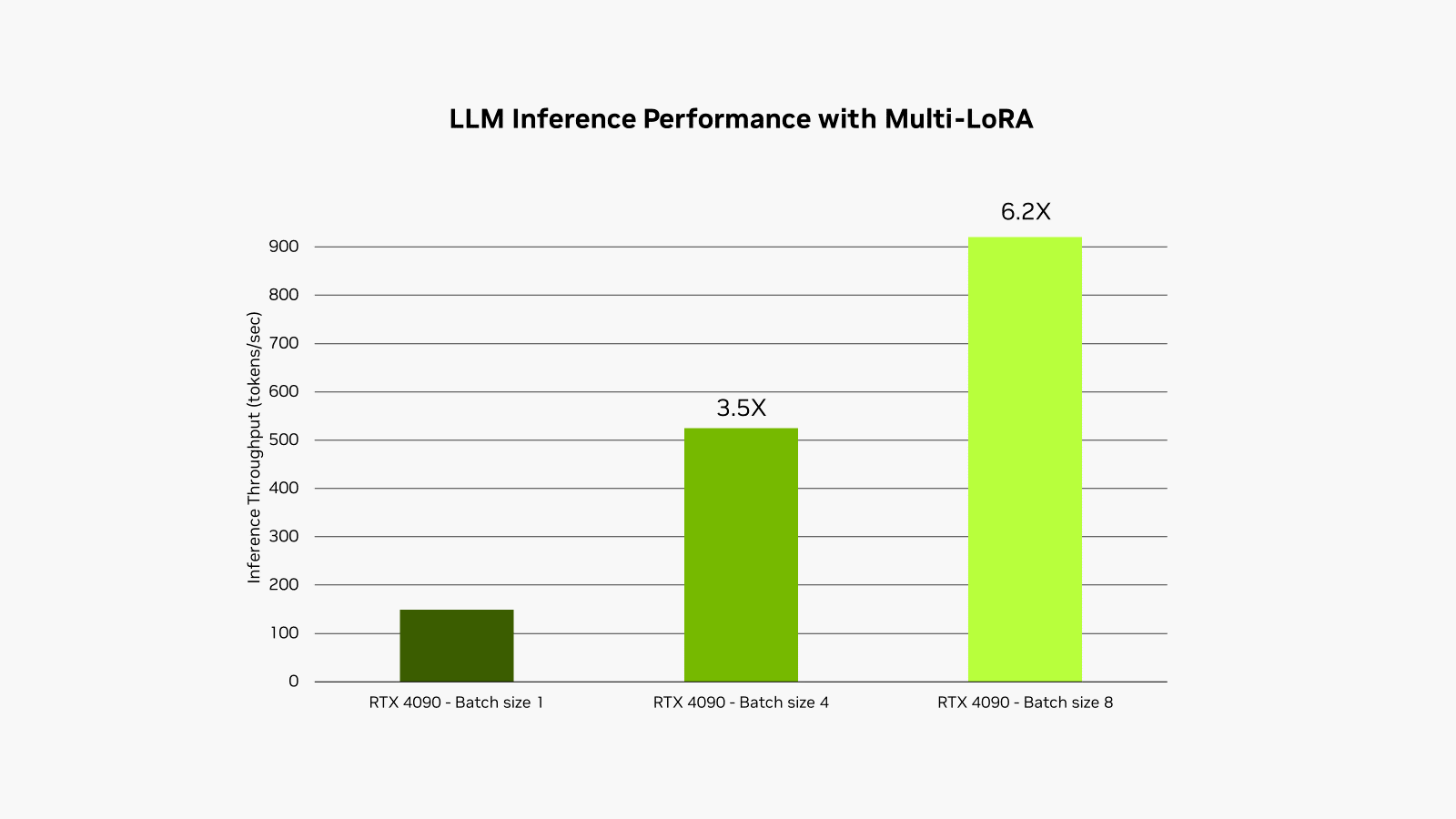
NVIDIA RTX AI Toolkit 透過稱為低秩適應 (LoRA) 的技術,在 RTX AI 電腦和工作站輕鬆微調及部署人工智慧模型。今天推出的全新更新,支援在 NVIDIA TensorRT-LLM 人工智慧加速庫同時使用多個 LoRA Adapter,模型經微調的效能提升高達 6 倍。
經過微調,效能提升
LLM 必須經過精心自訂,才能實現更高的效能,滿足使用者日益增長的需求。
這些基礎模型經過大量資料訓練,但往往缺乏開發人員特定使用案例所需的上下文。舉例而言,通用 LLM 雖然可生成電玩遊戲對話,但風格可能不夠細膩,無法活靈活現表現出擁有不可告人過去,而且顯然蔑視當權者的林地精靈。
若要進一步量身打造輸出內容,開發人員可以利用應用程式使用案例的相關資訊微調模型。
以為了利用 LLM 生成遊戲內對話開發應用程式為例。首先,微調過程使用預先訓練模型的權重,例如角色可能遊戲對話的相關資訊。為了讓對話風格逼真,開發人員可利用較小的樣本資料集調整模型,例如以更詭異或惡毒的語氣撰寫的對話。
在某些情況下,開發人員可能希望同時執行所有這些不同的微調流程。例如,他們可能希望為不同的內容頻道,生成以不同語氣撰寫的行銷文案。同時,他們或許想為文件整理摘要、提出風格上的建議,以及為文字轉影像生成器起草電玩遊戲場景描述和影像提示。
同時執行多個模型並不實際,因為這些模型不可能同時載入 GPU 記憶體。即使可以,推論時間也會受記憶體頻寬影響,也就是將資料從記憶體讀取至 GPU 的速度。
Lo(RA) 令人驚嘆
使用微調技術,例如低秩適應 (LoRA),是解決這些問題的熱門方式。簡而言之,就是將它視為包含微調過程自訂的修補程式檔案。
自訂的 LoRA Adapter 經過訓練,推論期間可與基礎模型順利整合,而且額外負荷微乎其微。開發人員可將 Adapter 附加至單一模型,為多個使用案例提供服務。這樣一來,記憶體佔用空間便能儘量減少,同時還能為每個特定使用案例提供需要的額外細節。
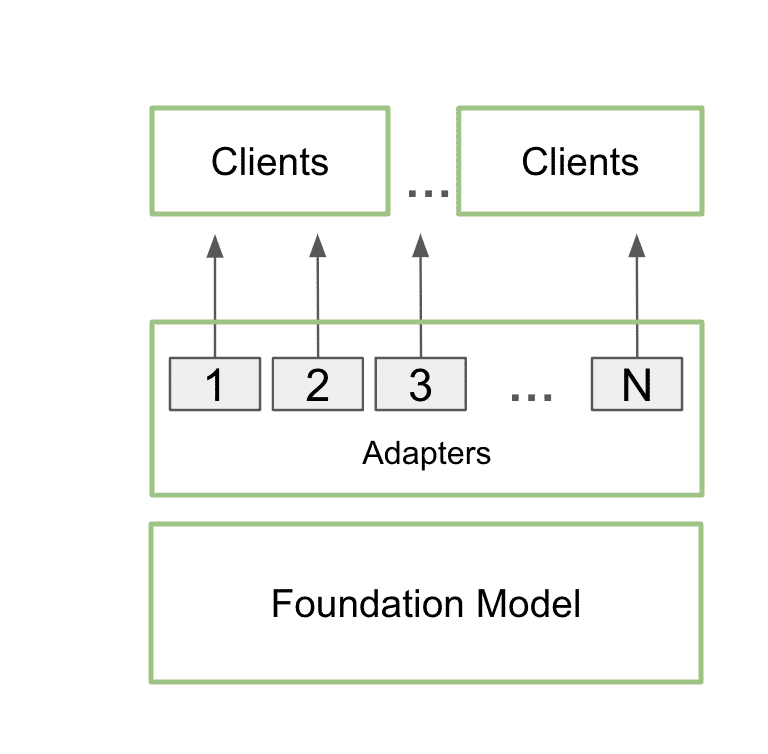
實際上,這意味著一個應用程式只能在記憶體保留一個基礎模型,以及使用多個 LoRA Adapter 進行的多項自訂。
這個過程稱為多 LoRA 服務。對模型進行多次呼叫時,GPU 可並行處理所有呼叫,充分利用 Tensor 核心,並將記憶體和頻寬的需求降至最低,讓開發人員可在工作流程高效使用人工智慧模型。採用多 LoRA Adapter 微調的模型速度提升高達 6 倍。
先前說明的遊戲內對話應用程式案例中,可利用多 LoRA 服務將應用程式的範圍擴大,由單一提示同時產生故事元素和插圖。
使用者輸入一個基本的故事構思,LLM 就能讓概念變得更具體豐富,將構思發揚光大,提供細節豐富的基礎。隨後應用程式便可使用相同的模型,透過兩個不同的 LoRA Adapter 強化,潤飾故事並生成相應的影像。一個 LoRA Adapter 生成 Stable Diffusion 提示,利用本機部署的 Stable Diffusion XL 模型產生視覺效果。同時,另一個 LoRA Adapter 經過微調後,可打造出結構嚴謹且引人入勝的故事。
在這種情況下,兩個推論過程都會使用相同的模型,確保處理過程所需的空間不會大幅增加。第二個過程涉及文字和影像生成,採用批處理推論執行,在 NVIDIA GPU 的處理過程極為快速高效。因此,使用者可快速迭代不同版本的故事,輕鬆潤飾故事和插圖。
近期的技術部落格將更詳細介紹這個過程。
LLM 正在成為現代人工智慧最重要的元件之一。隨着採用率和整合程度越來越高,對具有特定應用程式自訂功能的強大且快速的 LLM 的需求只會增加。RTX AI Toolkit 今天新增的多 LoRA 支援,為開發人員提供了加速這些功能的強大嶄新途徑。