
NVIDIA 的 AI 平台在最新的 MLPerf 產業基準測試中提高了人工智慧訓練和高效能運算的標準。
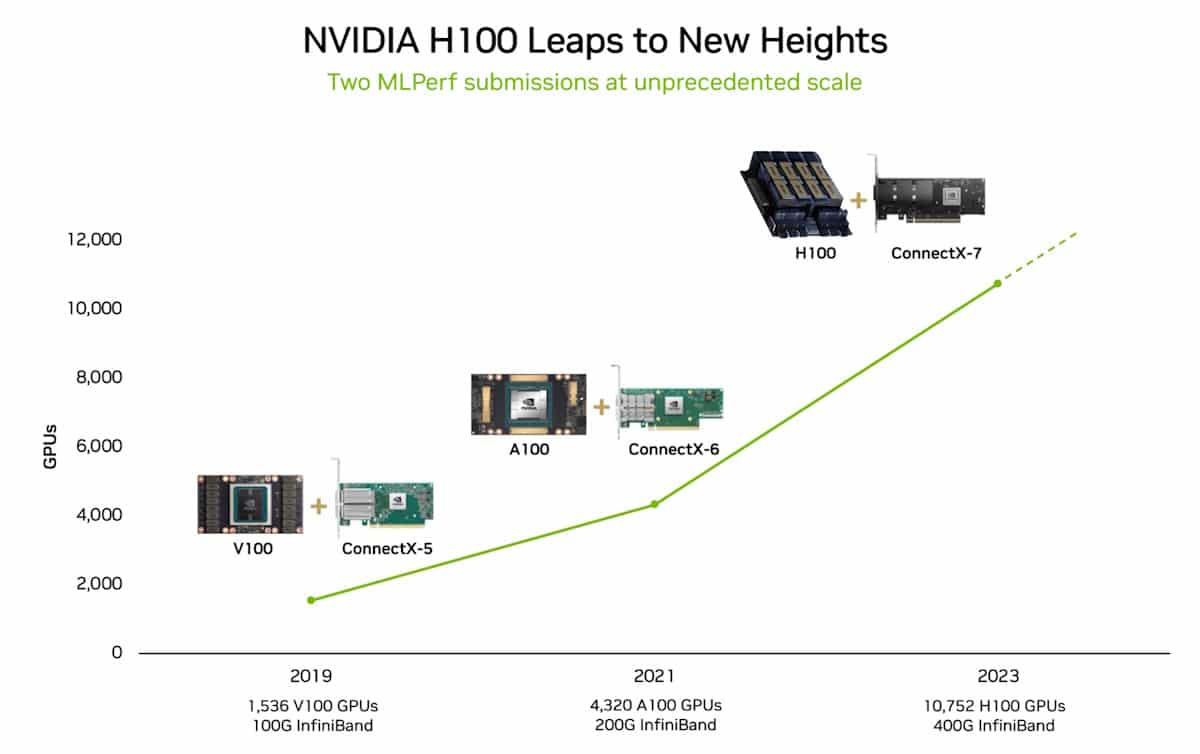
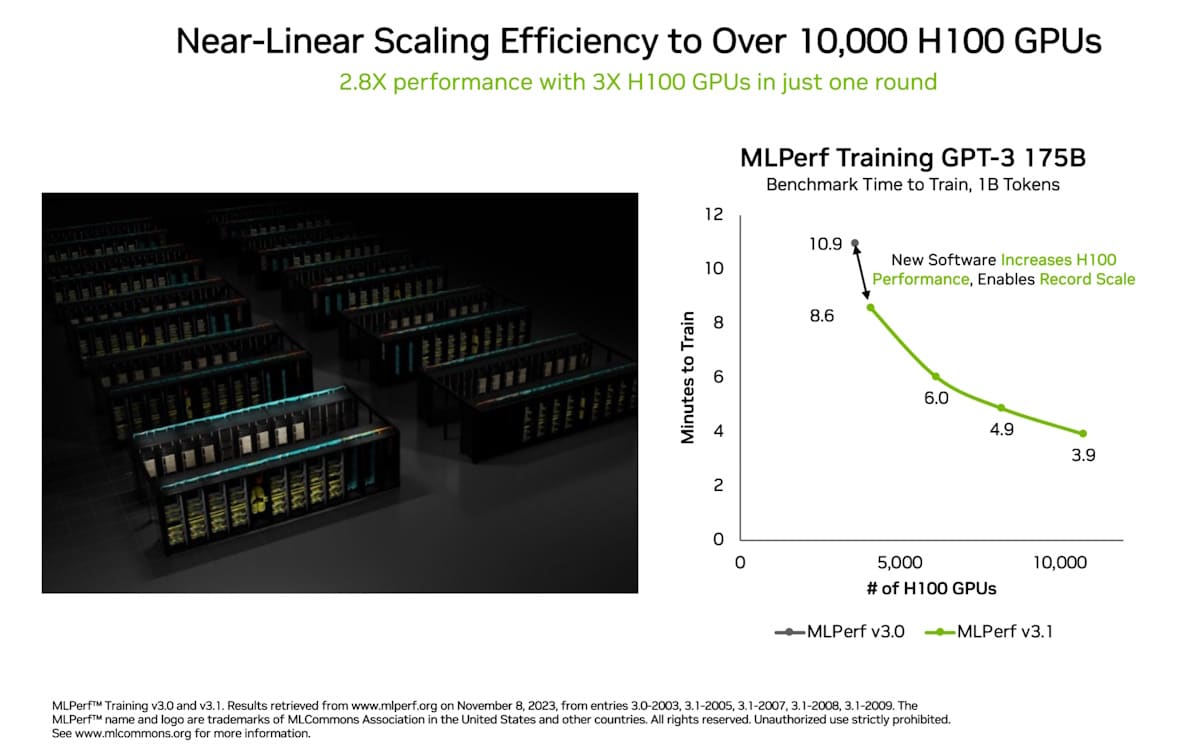
在眾多新紀錄和里程碑中,生成式人工智慧領域的一項紀錄特別突出:由多達 10,752 個 NVIDIA H100 Tensor Core GPU 和 NVIDIA Quantum-2 InfiniBand 網路技術驅動的 NVIDIA Eos 人工智慧超級電腦,僅在 3.9 分鐘內完成了基於 GPT-3 模型、擁有 1750 億個參數的訓練基準,與 NVIDIA 於此測試在不到六個月前甫推出時所創下的10.9分鐘紀錄相比,本次成績提高了近 3 倍。
該基準測試使用了流行的 ChatGPT 服務背後完整 GPT-3 資料集的一部分。透過推斷,Eos 現在只需八天即可完成訓練,比過往使用 512 個 A100 GPU 的最先進系統快上 73 倍。
加快訓練時間可以降低成本、節省能源並加速上市時間。雖然是一項艱鉅的任務,但透過 NVIDIA NeMo(一種用於自訂大型語言的框架)等工具,大型語言模型得以廣泛應用,進而使每個企業都能採用它們。
在這一輪的新生成式人工智慧測試中,1,024 個 NVIDIA Hopper 架構的 GPU 在 2.5 分鐘內完成了基於穩定擴散文本到圖像模型的訓練基準,為這一新工作負載建立了高標準。
透過採用這兩個測試,MLPerf 強化了自身在測量人工智慧效能方面的領導地位,因為生成式人工智慧是當今最具變革性的技術。
系統擴展劇增
最新結果的部分原因是使用了有史以來應用於 MLPerf 基準測試數量最多的加速器。10,752 個 H100 GPU 遠遠超過了 6 月 AI 訓練的規模,當時 NVIDIA 使用了 3,584 個 Hopper GPU。
GPU 數量擴展了 3 倍,效能擴展了 2.8 倍,還有部分歸功於軟體優化使效率高達 93%。
高效率地擴展是生成式人工智慧的關鍵需求,因為大型語言模型每年都在以數量級的速度成長。最新結果顯示出 NVIDIA 有能力應對全球最大資料中心也必須克服、且前所未有的挑戰。
這項成就歸功於 Eos 和 Microsoft Azure 在最新一輪中使用具備加速器、系統和軟體創新的全端平台。
Eos 和 Azure 在各自提交的檔案中均使用了 10,752 個 H100 GPU。它們的效能相差不到 2%,展現了 NVIDIA 人工智慧在資料中心和公有雲部署的高效率。

NVIDIA 依靠 Eos 來完成一系列關鍵工作。它有助於推進像是 NVIDIA DLSS(用於最先進電腦圖形的人工智慧驅動軟體)等計劃,以及像是 ChipNeMo(幫助設計下一代 GPU 的生成式人工智慧工具)等 NVIDIA 研究項目。
跨工作負載的進步
除了在生成式人工智慧方面取得進展外,NVIDIA 在這一輪中還創下了多項新紀錄。
例如,H100 GPU 在訓練推薦模型方面比先前一輪的速度快了 1.6 倍,這些模型廣泛用於幫助使用者在網上找到他們正在尋找的內容。在電腦視覺模型 RetinaNet 上的效能提高了 1.8 倍。
這些提升來自軟體進步和硬體規模擴大的結合。
NVIDI A再次成為唯一一家完成所有 MLPerf 測試的公司。H100 GPU 在九項基準測試中都表現出最快的效能和最大的擴展能力。

對於訓練大量大型語言模型或使用 NeMo 等框架,以符合其業務的特定需求進行客製化的使用者而言,加速意味著更快的上市時間、更低的成本和節省能源。
共有 11 家系統製造商在本輪提交的成果中使用了 NVIDIA 人工智慧平台,包括華碩、戴爾科技集團、富士通、技嘉科技、聯想、雲達科技和美超微。
NVIDIA 合作夥伴之所以參與 MLPerf,是因為他們知道這對客戶評估人工智慧平台和供應商來說,是一個很有價值的重要工具。
高效能運算標竿提升
在 MLPerf HPC(高效能運算)領域,這是一個專門用於超級電腦上、並以 AI 輔助模擬的基準測試,H100 GPU 在上一輪高效能運算測試中的效能是 NVIDIA A100 Tensor Core GPU 的兩倍。這些結果顯示自 2019 年首次舉行 MLPerf 高效能運算測試以來,效能提升了多達 16 倍。
該基準測試包括一項訓練 OpenFold 的新測試,OpenFold 是一個從氨基酸序列預測蛋白質 3D 結構的模型。OpenFold 能夠在幾分鐘內完成對醫療保健至關重要的工作,而這些工作以前都需要研究人員花費數周或數月才能完成。
了解蛋白質的結構是快速找到有效藥物的關鍵,因為大多數藥物皆作用於蛋白質,而蛋白質是幫助控制許多生物過程的細胞機制。
在 MLPerf HPC 測試中,H100 GPU 在 7.5 分鐘內訓練了 OpenFold。這個 OpenFold 測試是整個 AlphaFold 訓練過程的代表性部分,兩年前 AlphaFold 訓練過程使用 128 個加速器,耗時 11 天。
OpenFold 模型的一個版本和 NVIDIA 用於訓練的軟體不久後將在 NVIDIA BioNeMo 中提供,NVIDIA BioNeMo 是一個用於藥物發現的生成式人工智慧平台。
在這一輪測試中,數個合作夥伴使用了 NVIDIA 的人工智慧平台提交測試成果。這些合作夥伴包括戴爾科技集團、克萊門森大學(Clemson University)的超級電腦中心、德州大學奧斯汀分校的德州高級運算中心,以及獲得慧與科技(Hewlett Packard Enterprise)協助的勞倫斯伯克利國家實驗室(Lawrence Berkeley National Laboratory)。
獲得廣泛支持的基準測試
自 2018 年 5 月推出以來,MLPerf 基準測試得到了業界和學術界的廣泛支持。支持 MLPerf 基準測試的機構包括亞馬遜、Arm、百度、Google、哈佛大學、慧與科技、英特爾、聯想、Meta、微軟、NVIDIA、史丹佛大學和多倫多大學。
MLPerf 基準測試透明而客觀,因此使用者皆可依據測試結果,做出最為明智的購買決定。
NVIDIA 使用的所有軟體都可以從 MLPerf 資源庫中取得,因此所有開發人員都可以獲得相同的世界級成果。NVIDIA 不斷將軟體最佳化結果放入 NGC(NVIDIA 的 GPU 加速軟體目錄)上的容器中。