
本文章是 RAPIDS 生態系統介紹系列的第一篇。此系列探討了 RAPIDS 的各個層面,讓使用者可以解決 ETL(Extract、Transform、Load,擷取、轉換、載入)問題、建構機器學習和深度學習模型、探索各種圖表、處理地理空間、訊號,以及系統紀錄資料,或透過 BlazingSQL 使用 SQL 語言處理資料。
RAPIDS 框架是在 2018 年底推出,之後在普及性以及功能豐富性方面皆已獲得大幅成長。資料科學家和工程師以 pandas API 為藍本,透過變更少許的程式碼,即可快速利用 GPU 龐大的平行運算潛力。
本文將簡要介紹 RAPIDS 生態系統,並展示 RAPIDS cuDF(以 GPU 為基礎,對應於 pandas DataFrame)最常用的功能。我們也會在之後的文章中介紹一些更新,以及更先進的 RAPIDS 功能:接近即時資料串流、應用 BERT 模型從系統紀錄中擷取特徵,或擴充至由數百個 GPU 機器組成的叢集等等。
cuDF 是 RAPIDS 的資料科學構件。它是 ETL 主力,可以建立資料工作流程,以處理資料和衍生新的特徵。RAPIDS 為生態系統的一部分,其所有的其他部分都是以 cuDF 為基礎,使 cuDF DataFrame 成為共同的構件。如同 RAPIDS 的任何其他部分,cuDF 是使用 CUDA 後端驅動所有的 GPU 運算。但是,透過簡單及熟悉的 Python 介面,讓使用者無須直接與該層互動。
為了協助您熟悉使用 cuDF,我們提供了便利的備忘單,請從此處下載:cuDF 備忘單,以及互動式 notebook,包含 cuDF 備忘單的所有目前功能。
透過熟悉的介面進行 GPU 處理
RAPIDS 的核心,是以為熱門資料科學工具提供熟悉的使用者體驗為前提,讓所有人都可以輕鬆取用 NVIDIA GPU 的功能。無論是執行 ETL、建構機器學習模型或處理圖表,如果瞭解 pandas、NumPy、scikit-learn 或 NetworkX,即能輕鬆自在地使用 RAPIDS。
從 CPU 切換至 GPU 資料科學堆疊,從未如此簡單:僅需要匯入 cuDF 以取代 pandas,即可利用 NVIDIA GPU 的強大能力,將工作負載加快 10 至 100 倍(低階),使用熟悉的工具同時也享有更高的生產力。如以下範例程式碼所示,任何 pandas 使用者都會對 cuDF API 感到熟悉。
import pandas as pd
import cudf
df_cpu = pd.read_csv('/data/sample.csv')
df_gpu = cudf.read_csv('/data/sample.csv')從偏好的資料來源載入資料
自 2018 年 10 月發布第一版 RAPIDS 以來,cuDF 的讀寫能力已明顯提高。資料可以在本機電腦上、儲存在內部部署叢集中或位於雲端。cuDF 使用 fsspec 函式庫,將大部分與檔案系統有關的任務抽象化,讓您能專注於最重要的事:建立特徵和建構模型。
由於使用了 fsspec,可以從本機或在雲端檔案系統讀取資料,且僅需要提供憑證給後者即可。以下範例是從兩個不同的位置讀取同一個檔案:
import cudf
df_local = cudf.read_csv('/data/sample.csv')
df_remote = cudf.read_csv(
's3://<bucket>/sample.csv'
, storage_options = {'anon': True})cuDF 支援多種檔案格式:以文字為基礎的格式(例如 CSV/TSV 或 JSON)、以欄位導向的格式(例如 Parquet 或 ORC),或以列為導向的格式(例如 Avro)。在檔案系統支援方面,cuDF 可以從本機檔案系統,以及 AWS S3、Google GS 或 Azure Blob/Data Lake 等雲端供應商、內部或外部部署 Hadoop 檔案系統讀取檔案,且可以直接從 HTTP 或 (S)FTP 網頁伺服器、Dropbox、Google 雲端硬碟,或 Jupyter 檔案系統讀取檔案。
輕鬆建立與儲存 DataFrames
讀取檔案不是建立 cuDF DataFrame 的唯一方式。事實上,至少有四種方式:
從值清單中,可以建立單欄 DataFrame:
cudf.DataFrame([1,2,3,4], columns=['foo'])若想要建立多欄 DataFrame 時,可以傳遞字典:
cudf.DataFrame({
'foo': [1,2,3,4]
, 'bar': ['a','b','c',None]
})建立空的 DataFrame,並分配至欄位:
df_sample = cudf.DataFrame()
df_sample['foo'] = [1,2,3,4]
df_sample['bar'] = ['a','b','c',None]傳遞元組清單:
cudf.DataFrame([
(1, 'a')
, (2, 'b')
, (3, 'c')
, (4, None)
], columns=['ints', 'strings'])您也可以在記憶體表示之間進行轉換:
- 從表示為 DeviceNDArray 的內部 GPU 矩陣
- 透過在深度學習框架與 Apache Arrow 格式(以更方便的方式,操作來自各種程式設計語言的記憶體物件)之間共用張量的 DLPack 記憶體物件
- 在 pandas DataFrames 與 Series 之間進行轉換
此外,cuDF 支援將儲存在 DataFrame 中的資料,儲存為多種格式和檔案系統。事實上,cuDF 能使用其可讀取的所有格式儲存資料。
這些能力使其可以快速啟動與運作,無論任務為何或資料位於何處。
擷取、轉換和彙總資料
清理、特徵化和熟悉資料集是基本的資料科學任務,且是所有資料科學家都抱怨的任務。我們花費 80% 的時間進行此事。為何需要這麼多時間?原因之一是我們詢問資料集的問題,需要很長的時間才能回答。任何曾經嘗試在 CPU 上讀取和處理 2GB 資料集的人,都知道是什麼意思。此外,由於我們是人類,且會犯錯,因此,重新執行工作流程可能會佔據我們一整天的時間。其將會導致生產力損失,且可能會導致咖啡成癮,如下圖所示。
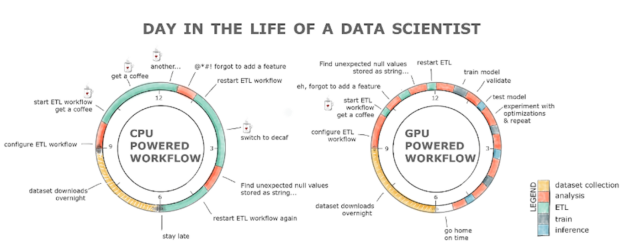
採用 GPU 驅動工作流程的 RAPIDS,可以克服所有的障礙。ETL 階段通常加快了 8 至 20 倍,僅需要數秒即可載入 2GB 資料集,而在 CPU 上則需要數分鐘的時間,且清理和轉換資料也加快了多個數量級!這一切都是透過熟悉的介面和最少的程式碼變更而完成。
在 GPU 上處理字串和日期
在不超過 3 年前,幾乎不可能在 GPU 上處理字串和日期,且已超出 CUDA 等低階程式設計語言的範圍。畢竟,GPU 是設計用來處理圖形,即操作由整數和浮點數組成的大型陣列和矩陣,而不是字串或日期。
RAPIDS 不僅可以將字串讀取至 GPU 記憶體,且能擷取、處理和操作特徵。由於使用了 cuDF,如果熟悉 Regex,現在已可輕而易舉地在 GPU 上,從文件中擷取實用資訊。例如,若想要尋找及擷取文件中所有與 [a-z]*flow 樣式匹配的單字(例如 dataflow、workflow 或 flow),則必須:
df['string'].str.findall('([a-z]*flow)')由於使用了 RAPIDS,從日期擷取實用特徵或查詢特定時段的資料,也變得更容易、更快速。
dt_to = dt.datetime.strptime("2020-10-03", "%Y-%m-%d")
df.query('dttm <= @dt_to')總言之,RAPIDS 已徹底改變了資料處理及資料科學家的其他任務,不僅可在本機 GPU 上,亦可在資料中心進行大規模處理。在過去需要數小時或數天時間處理的查詢,現在僅需要數分鐘即可完成,進而提高了生產力及降低了整體成本。
請造訪 app.blazingsql.com 查看和親自試用,並下載 cuDF 備忘單!
更多加速資料科學工作流程與分析的實作課程,請造訪 NVIDIA 深度學習機構(DLI)瞭解更多。