
人工產生人類語音,又稱為語音合成,是讓研究人員一直感到著迷的領域,包括 Axel Springer SE 的 AI 團隊。長期以來,人們一直在設法創造出可以達到人類水準的文字轉語音(text-to-speech,TTS)系統。該領域在 2006 年推出 Google WaveNet 而移轉至深度學習之後,幾乎已達成此目標。
目前 TTS 已在研究界獲得大量的動能。此技術已經變得很容易取得,例如透過 Mozilla、NVIDIA 或 Espnet 等各種開放原始碼專案,以及許多公用資料集,例如 LJ Speech 或 M-AILABS。神經語音合成是研究人員極有興趣的深度學習領域,因為它具有自然語言處理(natural language processing,NLP)和電腦視覺的特性。它同時涵蓋許多令人期待的研究領域,例如 GAN、自迴歸流、師生網路,以及具有先進注意力機制的 seq2seq 模型。
雖然該領域仍由科技巨頭主導,但是不斷成長的市場尚未窮盡。可能的應用包括聊天機器人、新聞媒體音訊內容自動化等等。新聞媒體使用 TTS 應用的明顯範例是新聞文章的朗讀功能,讓人們可以在通勤時收聽新聞。事實上,某些報紙已可提供此功能,但是主要是使用外部 TTS 服務以支援其應用。
歐洲最大的數位出版商 Axel Springer 決定進一步建立本身的內部技術,並創造自訂品牌語音,而非仰賴第三方供應商提供。在這一篇文章中,我們將簡要介紹現代神經語音合成的機制。我們同時會分享一些與創造此 TTS 技術有關的見解,此技術稱為 ForwardTacotron,是著重於穩健、快速之語音合成的 TTS 解決方案。事實上我們甚至已開放了原始碼,您可以在 GitHub 上尋找 ForwardTacotron 專案。
以下是可以使用 ForwardTacotron 模型實現的兩個範例:
範例 1:這是一段由合成語音朗讀的段落。
The artificial production of human speech, also known as speech synthesis, has always been a fascinating field for researchers, including our AI team at Axel Springer SE. For a long time, people have worked on creating text-to-speech (TTS) systems that reach human level. And since its transitioning to deep learning with the introduction of Google’s WaveNet in 2006, it has almost reached this goal.
您也可以控制語音速度。
範例 2:繞口令範例。
Peter Piper picked a peck of pickled peppers.
A peck of pickled peppers Peter Piper picked.
If Peter Piper picked a peck of pickled peppers,
Where’s the peck of pickled peppers Peter Piper picked?
若需要更多範本,請參閱 ForwardTacotron 專案頁面。
現代 TTS:自迴歸端對端模型
在 2006 年,Google WaveNet 是第一個用於 TTS 的神經網路,並將語音合成提升至新的水準。事實上,Google Cloud API 仍在使用此技術。WaveNet 的構想是以具有多個層及各種擴張率的自迴歸卷積網路,預測聲音訊號。自迴歸係指在每一次預測時,模型都會將上一次預測納入考量(圖 1),因此必須循序展開推論,而會拖慢速度。

替代方法:Tacotron
為了提供更易於使用的替代方法,Google 同時推出了端對端 TTS 系統 Tacotron,僅需要極少的預處理,即可在原始文字和音訊對資料上進行訓練。問題已減少至根據文字預測聲譜圖(通常轉換成音素),之後即可使用聲碼器演算法(例如 Griffin-Lim)或神經模型(例如 WaveRNN)轉換成聲音訊號。
藉由在聲音訊號上進行短期傅利葉轉換,即可從聲音訊號產生聲譜圖。在語音處理方面,通常是依據梅爾頻率基準,將聲譜圖正規化,以發出與人耳等距的等距聲音,之後稱為梅爾聲譜圖或梅爾。圖 2 顯示男性語音的梅爾範例。
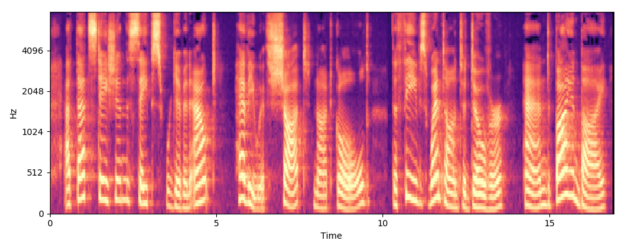
出現說話者之聲音和聲韻特有的明確形態,使梅爾頻譜圖成為良好的深度學習特徵表示法。根據文字預測,這些梅爾是典型的 seq2seq 問題,具有一些有趣的特殊性:
- 第一,輸入文字比目標序列短。
- 第二,文字與梅爾音框明顯對齊。
- 第三,目標序列具有高維度,通常深度為 80。
然而,解決此類 seq2seq 問題的首選模型,為典型的注意力編碼器-解碼器網路,且是 Tacotron 的骨幹。
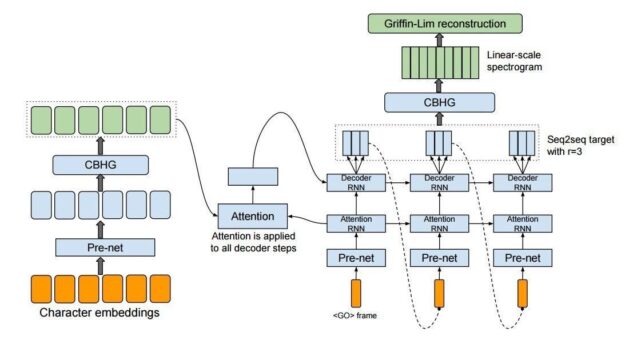
簡言之,Tacotron 透過卷積堆疊加上循環網路,針對文字(或音素)序列進行編碼,然後透過大型注意力 LSTM ,以自迴歸方式針對梅爾音框進行解碼。圖 3 顯示確切的架構,在原論文 Tacotron: Towards End-to-End Speech Synthesis 中有詳細說明。
邁向非自迴歸 TTS
雖然自迴歸模型在音質方面適用於語音合成,但是語音的循序推論超過 10 萬 個步驟,而導致速度緩慢。因此,研究人員致力於開發非自迴歸前饋模型,以加快推論速度。在採用以知識蒸餾、流基礎型產生和 GAN 為基礎的非自迴歸方法之後,聲碼器的速度已大幅提升。
在擁有了快速、現代化的非自迴歸聲碼器後,梅爾預測成為語音合成的瓶頸。以注意力為基礎之梅爾預測模型的另一個問題是缺乏可控性。換言之,產生之語音的語音速度和聲韻是取決於自迴歸產生。
為了解決這些問題,Microsoft 的研究人員提出了第一個非自迴歸梅爾預測模型,稱為 FastSpeech。研究人員的新穎構想是估計每一個音素應預測多少個梅爾音框,以解決音素和聲譜圖的對齊問題。這是由另外的持續時間預測器模組處理,而該模組是在真實音素持續時間進行訓練。這些持續時間可從已訓練之自迴歸模型的注意力對齊中擷取。在推論時,FastSpeech 模型是使用經過訓練的持續時間預測器擴展每一個音素,以便在所有層的單一正向傳遞中產生完整的梅爾聲譜圖。
若需要更多資訊,請參閱 FastSpeech: Fast, Robust and Controllable Text to Speech。
ForwardTacotron
最初的 FastSpeech 模型是由 12 個自注意力轉換器層組成,可能會消耗大量的記憶體。針對自注意力而言,空間複雜性與序列長度的平方成正比。為了消除此複雜性,我們使用沒有自迴歸注意力部分的循環 Tacotron 架構,重新實踐主要構想,以便在單一正向傳遞中預測梅爾(圖 4)。我們將模型稱為 ForwardTacotron,因為它將 FastSpeech 論文的構想與 Tacotron 架構結合。
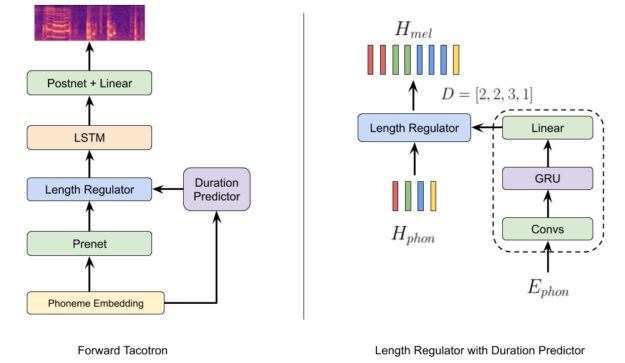
關鍵模組是從 FastSpeech 借用的長度調節器,根據預測的持續時間擴展音素嵌入。相較於 FastSpeech,我們決定將持續時間預測器模組與模型的其餘部分分開,因為可以提高梅爾的品質。由於缺乏注意力,記憶體需求會隨著序列長度線性而增加,即有可能透過模型一次預測完整的文章。預測既穩健且快速。例如,在 NVIDIA GeForce RTX 2080 上產生序列僅需要 0.04 秒。
另一個與 FastSpeech 不同的主要差異,是 ForwardTacotron 不仰賴知識蒸餾。表示它是在原始梅爾目標上訓練,而不是在擷取持續時間的注意力模型預測上訓練。我們僅將 Tacotron 做為持續時間擷取器使用,即使訓練步驟相對較少也很有效。
建置和訓練
為了縮短開發時間,我們的 ForwardTacotron 建置是以 Fatchord 的 Tacotron 儲存庫為基礎,同時包括 WaveRNN 聲碼器,可以從聲譜圖產生高保真音訊。即能大幅加快我們的開發過程。
我們也在 NVIDIA Quadro RTX 8000 上使用 LJSpeech 資料集,訓練 ForwardTacotron。我們利用 18 個小時和 19 萬個步驟產生良好的模型。您可以在 ForwardTacotron GitHub 儲存庫上找到模型權重。我們同時提供了包含預先訓練模型的 Colab Notebook 讓您玩一玩。當然,您也可以使用 ForwardTacotron,在您的資料上進行訓練。我們提供了未涵蓋在 Fatchord 建置中之詳細的模型訓練說明,以及一些訓練建議,包括適當的監控。
未來研究方向
Axel Springer AI 在積極地進行研究,以進一步改善非自迴歸語音合成。具體構想包括應用 GAN 產生更真實的梅爾,以及尋找更簡單的方法擷取音素持續時間,例如使用語音轉文字模型。
因為 ForwardTacotron 的推論速度很快,而使自迴歸 WaveRNN 聲碼器成為語音合成的瓶頸。因此,我們正在從 WaveRNN 切換至非自迴歸聲碼器,例如 MelGAN。最近,這些神經聲碼器已獲得大幅改善,並已達到可媲美自迴歸聲碼器的音質,同時加快了多個數量級。其他變體包括 parallel WaveNet、parallel WaveGAN 和 WaveGlow。
最後,開發不需要臨時擷取注意力對齊的非自迴歸正向模型,是一個有趣的研究方向。初步研究看起來很有趣,例如 AlignTTS 使用動態程式設計,尋找注意力對齊。