
此篇文章屬於「解碼 AI 」系列,該系列文章會以簡單易懂的方式解碼 AI,同時展示適用於 RTX PC 和工作站使用者的全新硬體、軟體、工具和加速功能。
獲得 NVIDIA RTX 及 GeForce RTX 技術支援的 AI PC時代已經到來,伴隨而生的是一種評估利用 AI 加速技術處理任務效能的新方法,以及一種在桌上型電腦和筆記型電腦之間進行選擇時可能不容易明白的新語言。
PC 遊戲玩家知道每秒畫格數(FPS)和類似的統計數據,不過在衡量 AI 效能之際倒是需要新的指標。
以 TOPS 為基準
第一個基準是 TOPS,即每秒兆次運算。在這裡,「兆」這個字很重要,生成式 AI 任務背後肯定要處理極為龐大的工作。將 TOPS 視為原始效能指標,類似於引擎的額定馬力,TOPS 的值越大越好。
舉例來說,對比微軟最近發布的 Copilot+ PC 系列,其中的神經處理單元(NPU)每秒可執行 40 兆次以上的運算。在處理一些比較輕度的 AI 輔助任務時,例如詢問本地聊天機器人昨天的筆記放在哪裡,40 TOPS 的運算表現已經十分足夠。
不過許多生成式 AI 任務有著更高的要求。NVIDIA RTX 和 GeForce RTX GPU 可在執行所有生成式 AI 任務時提供無與倫比的效能 – GeForce RTX 4090 GPU 的運算效能達到 1,300 TOPS 以上。這正是處理建立 AI 輔助數位內容(DCC)、PC 遊戲中的 AI超級解析度、從文字或視訊生成影像、查詢本地大型語言模型(LLM)等任務時所需的強大運算能力。
投入Token開始運算
TOPS 只是故事的開始。模型生成的 token 數量正是衡量 LLM 效能的標準。
LLM 會輸出 Token,Token可以是句子裡的一個字,甚至可以是標點符號或空格等較小的片段。可以用「每秒產生的 Token 數量」來衡量處理 AI 加速任務的效能。
Batch Size(批次大小),也就是在一次推論過程中同時處理的輸入數量,是另一個重要因素。LLM 將成為許多現代 AI 系統的核心之故,處理多個輸入(例如來自單一應用程式或跨多個應用程式的輸入)的能力將成為區分這些 LLM 高下的重要因素。更大的Batch Size雖然有助於提高同時處理輸入內容的表現,卻也需要用到更多記憶體,尤其是在搭配更大的模型使用時。
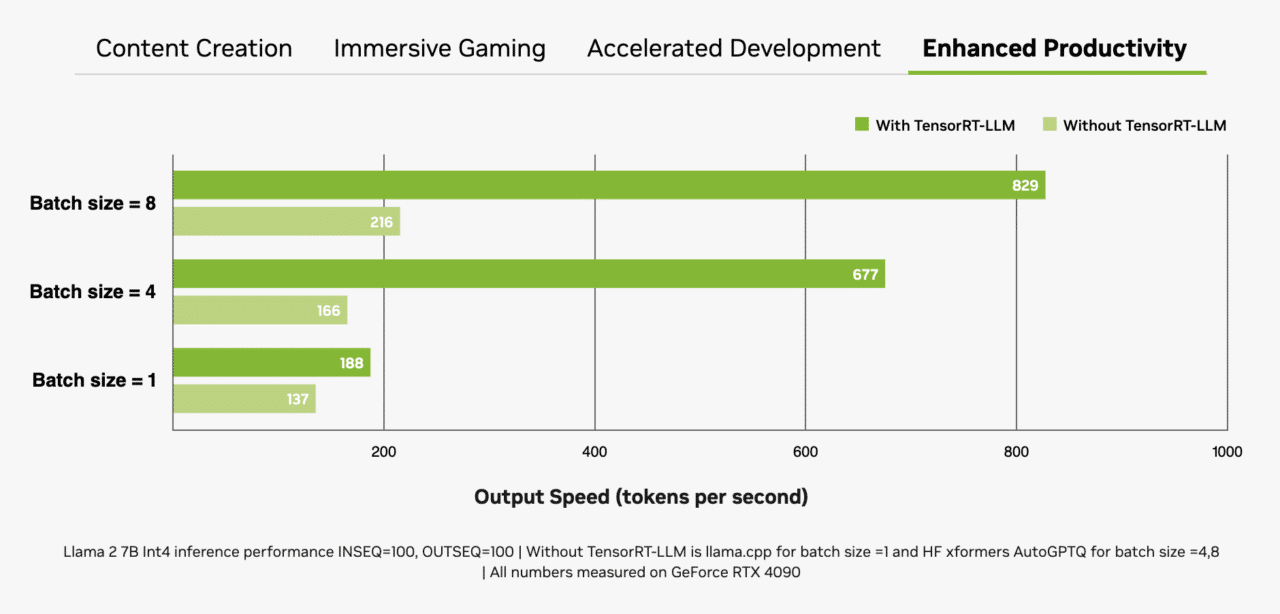
RTX GPU有著大量專用視訊隨機存取記憶體(VRAM)、Tensor 核心和 TensorRT-LLM 軟體,非常適合用於搭配 LLM。
GeForce RTX GPU 提供高達 24GB 的高速 VRAM,NVIDIA RTX GPU 則是提供高達 48GB 的VRAM,可以處理更大的模型與有著更大的Batch Size。RTX GPU 還利用專用的 AI 加速器 Tensor 核心,可顯著加快處理深度學習和生成式 AI 模型所需的運算密集型操作。應用程式使用 NVIDIA TensorRT 軟體開發套件(SDK)時,能夠輕鬆達到最高效能表現,而這款工具套件可以在由 RTX GPU 驅動、超過一億台 的Windows PC 和工作站上,提供有著最高效能的生成式 AI。
記憶體、專用 AI 加速器和最佳化軟體的組合,大幅提升了 RTX GPU 的輸送量,尤其是當Batch Size的數量增加時。
文字轉影像的速度比過去更快
衡量生成影像的速度是另一種評估效能的方法。最直接的方法之一便是使用熱門的影像 AI 模型 Stable Diffusion,使用者可以透過它輕鬆將文字描述變成複雜的視覺表示內容。
Stable Diffusion 用戶可以根據文字提示快速產生及完善影像,做出所需要的輸出效果。使用 RTX GPU 生成這些結果的速度,比在 CPU 或 NPU 上處理 AI 模型還要快。
要是將 TensorRT 擴充項目用於熱門的 Automatic1111 介面,效能還會更出色。RTX 使用者使用 SDXL Base 檢查點根據提示生成影像的速度提高了兩倍,大幅簡化了 Stable Diffusion 工作流程。
另一款同樣熱門的 Stable Diffusion 使用者介面 ComfyUI,上週加入了 TensorRT 加速功能。RTX 使用者現在根據提示生成影像的速度可以提高 60%,使用 Stable Video Diffuson 搭配 TensorRT 將這些影像轉成視訊的速度甚至可提高 70%。
TensorRT 加速技術可以在新的 UL Procyon AI 影像生成基準測試中進行測試,與速度最快的非 TensorRT 執行相比,該基準測試在 GeForce RTX 4080 SUPER GPU 上的速度提高了 50%。
TensorRT 加速技術即將用於 Stability AI 備受期待的全新文字轉影像模型 Stable Diffusion 3,加入後效能將可提高 50%。新款 TensorRT-Model Optimizer 還能進一步提高效能。與非 TensorRT 執行相比,速度提高了 70%,記憶體耗用量減少了 50%。
然而,真正的考驗是在原始提示(Prompt)上進行反覆運算的實際應用案例,使用者在 RTX GPU 上調整提示內容以生成更完善影像的速度明顯更快,每次反覆運算只需幾秒鐘,而在 Macbook Pro M3 Max 上則需要幾分鐘的時間。使用者還能同時獲得速度和安全性,在搭載 RTX 技術的 PC 或工作站以本機端的方式運行時,一切內容都將保持隱私性。
已經公布結果與開源
開源 Jan.ai 模型背後的 AI 研究人員和工程師團隊,日前將 TensorRT-LLM 納入到他們的本機端聊天機器人應用程式中,然後自行測試了這些經過完善後的項目。
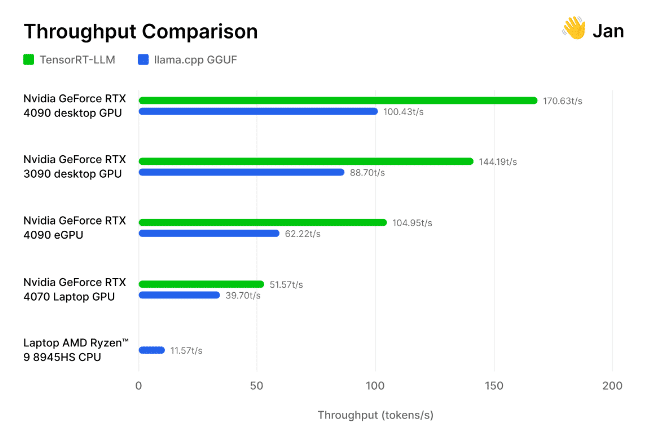
研究人員在社群經常使用的各種 GPU 和 CPU 上,針對開源 llama.cpp 推論引擎測試了 TensorRT-LLM 的執行情況。他們發現 TensorRT「在相同硬體上的速度比llama.cpp快30-70%」,而且在連續處理運行時的效率更高。該團隊還提供了自己的方法,邀請其他人自行測量生成式 AI 的效能。
從遊戲到生成式 AI,速度才是王道。TOPS、每秒生成的影像數、每秒生成的 Token 數量和 Batch Size 都是決定效能優勢的考量因素。
生成式 AI 將改變遊戲、視訊會議和各種互動體驗。訂閱《解碼AI》電子報,掌握最新動態與未來發展趨勢。