
NVIDIA Merlin 是一個從資料預處理到模型訓練與推論,皆可在 NVIDIA GPU 上加速,以實現推薦系統之端對端開發的應用程式框架和生態系統。我們在上一篇文章中發表 Merlin,並持續更新公開測試版。
本文將詳細介紹公開測試版 NVIDIA Merlin HugeCTR(Huge Click Through Rate,高點擊率)增加的新功能。新功能包括屬於 MLPerf 訓練和推論基準測試之一部分的深度學習推薦模型(Deep Learning Recommendation Model,DLRM)。DLRM 已成為 HugeCTR 模型儲存庫的一部分,可支援多 GPU 和多節點訓練。Merlin 開放測試版已將 DLRM 納入最新版本中,以重申 NVIDIA 對於加快研究人員、資料科學家以及機器學習工程師之工作流程,並將大規模深度學習推薦系統普及化的承諾。
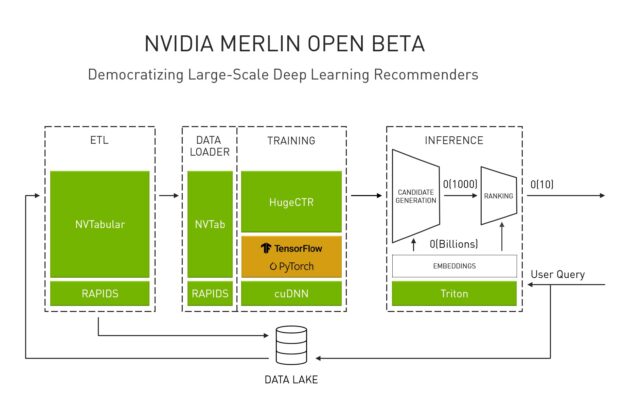
Merlin HugeCTR
繼上一次更新之後,Merlin HugeCTR 已增加多種功能,為希望加快和擴展工作流程的研究人員、資料科學家以及機器學習工程師,簡化最佳化和互通性。我們賦予 DLRM 訓練經高度最佳化的訓練工作流程,且與 NVIDIA MLPerf 創記錄提交中使用的工作流程相同。HugeCTR 已可同時支援專為高效能彈性資料中心而設計的 NVIDIA Ampere 架構。在不同的 DGX 平台上,將寬深(Wide & Deep)模型與 HugeCTR 搭配使用,可以提升效能。我們增加了兩種新的資料集格式,並導入與 NVTabular 的互通性,同時開發其他功能以加強使用性。
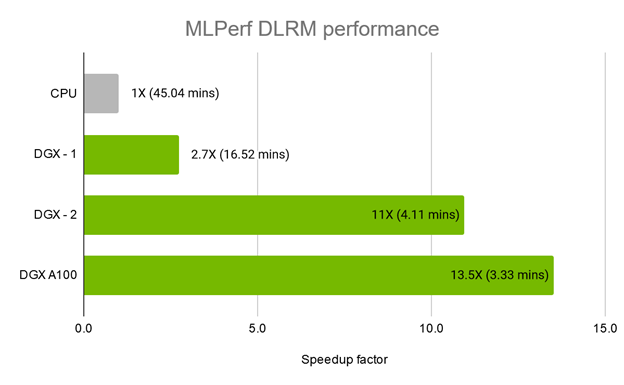
現在,HugeCTR 提供 DLRM 做為 HugeCTR 模型儲存庫的一部分,並與其他最先進的模型並列,例如 DeepFM、深度交叉網路(Deep & Cross Network,DCN)以及 W&D 學習。經證實,HugeCTR 搭配 NVIDIA DGX A100 系統是市面上最快的 DLRM 訓練解決方案。在 MLPerf v0.7 訓練基準測試中使用的 Criteo Terabyte Click Logs 資料集上,僅使用 3.33 分鐘即完成訓練,如圖 2 所示。
重現 MLPerf DLRM 訓練範例
若要重現 HugeCTR 的 MLPerf DLRM 訓練效能,請遵循 NVIDIA/HugeCTR DLRM範例,進行下述步驟。
下載 Criteo Terabyte Click Logs 資料集。將資料集解壓縮為 day_0、day_1、…、day_23。
依據 README.md 中的指示建構 HugeCTR。
重新處理資料集。此操作會產生兩個二進位輸入檔案:train.bin (671.2 GB) 和 test.bin (14.3 GB)。
# Usage: ./dlrm_raw input_dir output_dir –train {days for training} –test {days for testing}
cp ../../build/bin/dlrm_raw ./
./dlrm_raw ./ ./ \
–train 0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22 \
–test 23
使用提供的四個 JSON 配置檔之一,執行 HugeCTR 訓練:
此外,我們提供 Jupyter notebook 教學,示範如何在電影鏡頭 20m 資料集上訓練 DLRM 模型,然後使用電影嵌入,回答電影相似性查詢。此範例之目的是協助您熟悉從資料預處理,到訓練與推論的 HugeCTR 工作流程。
DLRM:新層
為了在 HugeCTR 中支援 DLRM,我們增加了以下同樣有助於其他自訂模型的新層:
- 互動層:為了顯式擷取特徵之間的二階互動而設計的層。HugeCTR 為此層支援 FP32 和 FP16 資料類型,同時針對 FP16 進行高度的最佳化。在混合精度模式下,所有操作都已融入單一 CUDA 核心中,以進行正向和反向傳遞。
- 融合全連接層:為了進一步提高記憶體頻寬利用率,HugeCTR 在混合精度模式下提供了一個新層,在單一核心內計算偏差加法和 ReLU 激發函數。此層是適用於各種模型的通用層。
- NVSwitch 感知嵌入層:最初,嵌入層的正向傳遞是由三個階段組成:嵌入查詢核心、多對多 GPU 間通訊,以及資料重排。為了在 DGX-2、DGX A100 等伺服器上利用 NVSwitch 的完整 GPU 連線能力,我們將上述三個步驟融合成一個 CUDA 核心。我們使用相同的方法進行嵌入反向傳遞。藉由將讀取和寫入流量減半,以大幅提升效能。最佳化嵌入層在 JSON 配置檔中的名稱為 LocalizedSlotSparseEmbeddingOneHot。
欲深入瞭解如何針對模型使用這些新層,請參閱 DLRM 模型配置檔。
Ampere 帶來的效能提升
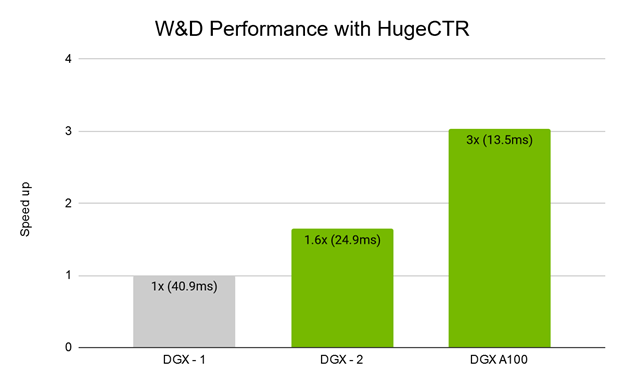
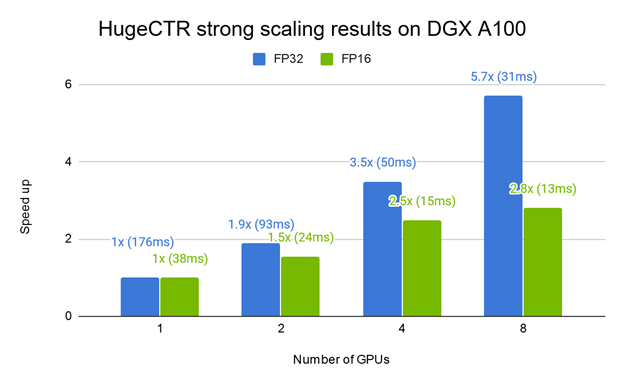
圖 3 顯示在不同 DGX 平台上使用 HugeCTR 進行的 W&D 模型訓練效能。相較於搭載 8 個 V100 GPU 的 DGX-1,搭載 16 個 V100 GPU 和 NVSwitch 的 DGX-2 呈現出良好的加速效果。DGX A100 搭載八個最新發表的 NVIDIA A100 GPU,比 DGX-1 快 3 倍,比 DGX-2 快 1.8 倍。圖 4 顯示在 DGX-A100 上訓練 W&D 的強大擴充結果。
兩種新的資料格式
Merlin HugeCTR 在資料載入階段,支援兩種新的資料集格式。其中之一是簡化獨熱資料讀取的「原始」格式。我們提供的 DLRM 範例,是將此格式與針對 Criteo 1TB 資料集的 GPU 加速預處理工具搭配使用。
另一種格式是 Parquet,可以讓 HugeCTR 使用經過 NVTabular 預處理的資料。Parquet 是 Apache Hadoop 生態系統的欄位導向資料格式,免費且已開放原始碼。為了示範如何將此格式與 HugeCTR 搭配使用,我們在 DeepFM、DCN 和 W&D 範例中加入新的配置檔。我們同時在這些範例中,提供使用 NVTabular 的新資料預處理指令碼。
完整的 FP16 工作流程
HugeCTR 將 FP16 類型支援,從僅限全連接層延伸至其他層,包括互動、嵌入和損失運算。讓 HugeCTR 可在 Volta、Turing 和 Ampere 架構中充分利用 Tensor 核心,同時有效節省記憶體頻寬和記憶體容量。若要開啟混合精度模式,請在 JSON 配置檔中指定 mixed_precision 選項。
加快工作流程的其他功能
為了您的方便,我們為 HugeCTR 增加了多種新功能:
- GEMM 演算法搜尋:HugeCTR 可針對各個全連接層執行詳盡的演算法搜尋,找出特定輸入形狀和系統的最佳演算法。您可以使用 JSON 將其關閉。
- 學習率排程:除設定基本學習率外,您也可以設定暖身期以及使用學習率衰減。DLRM 範例示範了如何為最佳化工具進行指定。
- 以 AUC 做為新的評估指標:HugeCTR 一直支援 AverageLoss 做為唯一的評估指標。現在,我們增加了 AUC 的 GPU 加速版本,做為支援的指標之一。您也可以設定閾值,在 AUC 值達到該值時停止訓練。
- 權重初始化:每一個可訓練層都可以變更權重初始化方法。例如,在全連接層方面,可能需要使用 XavierUniform 和 Zeros 分別將權重及偏差初始化。目前,我們支援四種初始化方法:Uniform、XavierNormal、XavierUniform 以及 Zeros。
- 使用 RAPIDS cuML 基元:HugeCTR 是採用針對機器學習演算法進行高度最佳化的 cuML 基元,因此可以利用它們的高效能。
- Docker 支援:建議依據快速入門指南上的指示,將 HugeCTR 與 Docker 容器搭配使用。
若需要更多資訊,請參閱版本說明。
試用 Merlin Training
Merlin Training 的最新版本可為資料科學家、機器學習工程師和研究人員提供更多支援,以開發大型深度學習推薦系統。此重大功能更新包括加強對 DLRM 的支援,該模型讓您可以更有效率地處理生產規模資料。DLRM 支援也包括針對 HugeCTR 建置的多 GPU 訓練,可進一步加快工作流程。相較於 CPU 訓練,HugeCTR 搭配 NVIDIA A100 可以大幅加快速度:HugeCTR 搭配 NVIDIA DGX A100 系統僅需要 3.33 分鐘,而在 16 個次世代 Xeon CPU 叢集上需要 45 分鐘。若想要實現 10 倍的傳輸量提升,請立即試用 Merlin Training。
所有 NVIDIA Merlin 元件都是以開放原始碼專案的形式提供。但是,使用 Merlin NGC 容器,是更方便利用這些元件的方式。容器讓您可以在獨立環境中,封裝軟體應用程式、函式庫、相依性、執行階段編譯器。因此,應用程式環境不僅可移植、一致、可重現,且不限基礎主機系統軟體配置。Merlin 元件在 NGC 上,是以容器集合的形式提供,包括 HugeCTR。
欲深入瞭解 Merlin ETL,請參閱 Announcing the NVIDIA NVTabular Open Beta with Multi-GPU Support and New Data Loaders。