
在出現以 transformer 架構為基礎的新型深度學習方法後,自然語言處理(natural language processing,NLP)技術的效能和功能亦經歷了巨大變化。最先進的 NLP 模型已逐漸成為現代搜尋引擎、語音助理、聊天機器人等技術的核心。現代 NLP 模型可以合成擬人文字,並以自然語言回答提出的問題。如同 DeepMind 研究科學家 Sebastian Ruder 所說,NLP 的 ImageNet 時刻已經來臨。
儘管在主流使用案例中,NLP 應用已在增長,但是仍未獲得醫療、臨床應用和科學研究領域廣泛採用。部分原因為在 Wikipedia 和來自文獻的文字上訓練的早期模型,在臨床和科學語言方面的表現不如預期。BioMegatron 等新的 NLP 模型已透過 NVIDIA 在大型臨床和科學語料庫上進行訓練,並在常見的生物醫學 NLP 任務中達到出色的效能,例如命名實體辨識(named entity recognition,NER)、關係擷取(relation extraction,RE)和問題回答(question answering,QA)。
BioMegatron 可以從生物醫學文字中擷取關鍵概念和關係,並建立可推動研究和探索的知識圖譜。它亦可在臨床語音和文字中識別臨床術語,並對映至標準化本體,以輔助臨床紀錄和研究。BioMegatron 模型是在由八個 DGX-2 組成的 AI 叢集上,經過大約 400 小時(大約兩週)的預先訓練。 此 AI 叢集稱為 DGX SuperPOD,提供了處理大型 AI 運算任務之快速的 I/O 架構,以及足夠的電腦能力,以在發表新的科學文獻時訓練模型。事實證明,使用專業詞彙在更多臨床和生物醫學文字上,以更長的時間地訓練更大的語言模型,可以提高模型的準確性。
適用於製藥、生物科技和研究的 NLP
對製藥公司而言,NLP 具有將文字探勘自動化以創造極大價值的潛力。它可以促使製藥公司揭露隱藏在大量非結構化資料中的寶貴資訊。非結構化資料的範例,包括科學期刊文章、醫師筆記和醫學成像報告。在過去,是以手動方式分析和解讀非結構化資料。現在,最先進的 NLP 技術可以從龐大的文字資料語料庫中,透過本體對映建立大型的知識圖譜。之後,可以從強大的語意搜尋工具開始,將這些知識圖譜使用在多個下游任務中。
目前已有製藥公司使用 NLP 進行目標識別和優先排序、老藥新用、解讀透過體學實驗鑑定的基因和蛋白質,以及針對新目標探勘專利全文的範例。NLP 亦可用於擷取與治療型態有關的資訊,以確定換藥或停藥。NLP 可以擷取和正規化數值資料,例如實驗室值和劑量資訊,以及患者相關資訊,例如病史、問題清單、人口統計資料、社會因素、生活型態。
適合臨床醫師和醫院的 NLP
對臨床醫師而言,輸入患者就診紀錄是既費力又耗時的工作。通常在數小時後完成時已經感到疲倦,且可能已經忘記整個對話。
NLP 可以整合至自動語音辨識(automatic speech recognition,ASR)系統,進而能在個別語音或對話中辨識關鍵臨床用語。之後,將辨識出的臨床用語,對映至標準化醫學本體中的概念。將會記錄虛擬或面對面的患者/臨床醫師互動,並直接輸入至醫學圖譜中,做為即時醫學轉錄。所有資訊都會記錄,讓臨床醫師和患者都可以放心。臨床醫師可以空出時間診療更多患者,或以更多的時間陪伴患者。醫療語音辨識系統亦可在就診期間,協助針對患者病歷的特定部分進行語音查詢。「這是遠距醫療及其他紀錄工具的關鍵賦能技術。」NVIDIA 醫療 AI 全球負責人 Mona Flores 表示:「讓醫師可以專注於患者,而不是做筆記。」
臨床 NLP AI 模型也有助於電腦輔助編碼、自動化登錄報告、探勘資料以及改進臨床紀錄。將能減輕醫師和醫院的紀錄負擔,讓他們有更多的時間可以專注於患者。圖 1 顯示使用 BioMegatron 擷取臨床實體,並對映至本體的範例,摘錄自 Fast and Accurate Clinical Named Entity Recognition and Concept Mapping from Conversations 論文。

BioMegatron 概述
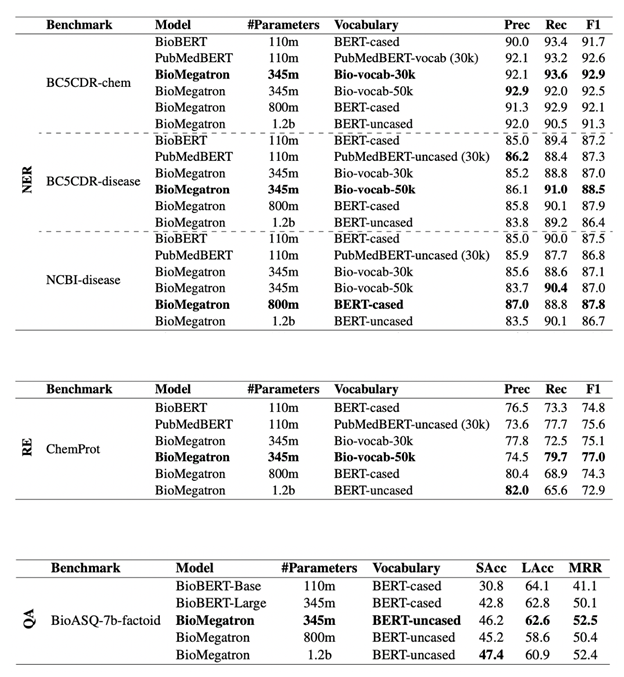
BioMegatron 是由 NVIDIA 開發,最先進的語言模型,適用於生物醫學和臨床 NLP。近期研究證明,較大的語言模型可以大幅促進 NLP 應用,例如 QA、對話系統、摘要和完成文章。BioMegatron 是目前生物醫學以 transformer 為基礎之最大的語言模型。它最大可達 BERT 的 3.5 倍,具有 3.45 億、8 億及 12 億個參數變體。它是在來自 PubMed 的 61 億個單字上訓練,而PubMed 是與生物醫學主題有關之摘要及全文期刊文章的典藏庫。
BioMegatron 是以 NVIDIA NLP 模型 Megatron-LM 為基礎,可以交換模型架構(類似 GPT-2 架構)中的層正規化和殘差連接位置。將可在縱向擴充時持續改進模型。
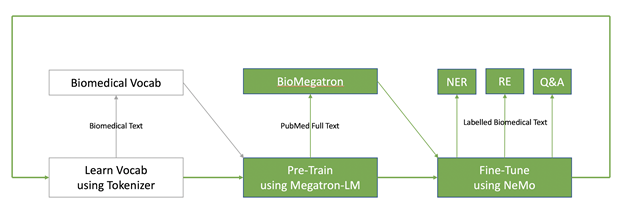
現代的 NLP 模型是遵循在預先訓練之後進行微調的兩步驟範式。以無監督方式,在大型文字語料庫(PubMed)上完成預先訓練,以產生科學語言模型(BioMegatron)。之後,針對 NER、RE、QA 等各種下游 NLP 應用,調整此語言模型。對於領域專用語言模型而言,額外的第一步是選擇良好的詞彙,以訓練語言模型。根據我們建構 BioMegatron 的經驗,詞彙選擇會大幅影響下游 NLP 模型的效能。
預先訓練過程是運算最密集的步驟,其涉及大量的超參數調整。可能會隨著模型變大,而開始發生記憶體限制的問題。模型平行訓練可以在多個 GPU 之間分割模型參數,以克服此問題。
Megatron-LM 模型是以既簡單,且有效率的模型平行方法訓練 transformer 模型,相較於快速的單 GPU 基準,在 512 個 GPU 上可以達到 76% 的擴充效率。若需要更多資訊,請參閱 Megatron-LM 軟體訓練配方,或下載 NVIDIA Clara NLP NGC 中的 BioMegatron,並立即開始使用。NVIDIA Clara NLP NGC 是支援醫療和生命科學領域 NLP 的模型和資源集合。
使用對話式 AI 開放原始碼工具套件 NeMo 進行微調。BioMegatron可以在針對 NER、RE、QA 等各種常見的 NLP 任務進行微調時,利用 NeMo 產生最優異的效能。此論文已獲得 2020 Conference on Empirical Methods in Natural Language Processing(EMNLP 2020)接受,現在已可在 arXiv 上取得,BioMegatron:Larger Biomedical Domain Language Model。
改進 BioMegatron
BioMegatron 是在公開的生物醫學和科學文字上訓練。如果擁有龐大的臨床或生物醫學文字語料庫(例如製藥業和醫院),則可進一步訓練 BioMegatron,在特定資料上獲得更好的效能。
在瞬息萬變的生物醫學和科學研究領域中,不斷發現新的術語、藥物名稱和詞彙,並導入科學文獻。因此,必須持續訓練語言模型,才能確保最佳的準確性。免費開始使用 BioMegatron,在您的生物醫學資料上進行測試,或使用您的資料進行進一步的預先訓練。下載 BioMegatron 模型和支援工具。