針對深度神經網路進行監督式訓練,已成為建立人工智慧應用程式的常用方法。若想要為應用程式實現準確的人工智慧,通常需要非常大的資料集,尤其是從零開始建立的情況下。收集和準備大型資料集以及標示所有的影像,通常既昂貴又耗時,且需要該領域的專業知識。
NVIDIA 在 NVIDIA 遷移學習工具套件(TAO Toolkit)2.0 之後推出極度準確、特製,且經過預先訓練的模型,以實現更快速且準確的人工智慧訓練。您可以使用這些自訂模型做為起點,以較小的資料集進行訓練,大幅縮短訓練時間。如果物件類別符合您的需求,且資料集的準確性充分時,便可使用這些特製的人工智慧模型,還可以輕鬆調整類似領域或使用案例。
遷移學習工具套件是以 Python 為基礎,使用轉移學習和預先訓練模型,建立高度最佳化和準確之人工智慧應用程式的人工智慧工具套件。遷移學習工具套件讓任何人都能輕鬆使用人工智慧:資料科學家、研究人員、新系統開發人員,以及剛接觸人工智慧的軟體工程師。除建立準確的人工智慧模型外,遷移學習工具套件也能最佳化推論模型,以達到最高的部署傳輸量。
本文章將會先引導您至 NVIDIA NGC 下載遷移學習工具套件 Docker 容器和人工智慧模型,再使用您的資料集進行訓練與驗證,接著使用 NVIDIA DeepStream SDK 和 NVIDIA TensorRT 匯出經過訓練的模型,並部署至邊緣端,以完成工作流程。此外,也可以將這些模型匯出,並轉換成 TensorRT 引擎進行部署。我們會逐一說明 4 個偵測模型和 2 個分類模型。
除專用模型外,TLT 2.0 也可以支援在 YOLOv3、FasterRCNN、SSD/DSSD、RetinaNet 等熱門的物件偵測架構上,以及 ResNet、DarkNet、MobileNet 等熱門的分類網路上進行訓練。
專用模型
專用人工智慧模型主要是針對智慧城市、停車管理、智慧建築中的應用而建立。它們接受了數百萬張影像的訓練。
NGC 上提供未修剪和已修剪版本的模型。將未修剪模型與遷移學習工具套件搭配使用,以透過您的資料集重新訓練。另一方面,已修剪模型則能立即部署,您可以直接部署在邊緣裝置上。此外,已修剪模型也包含 INT8 精度的校正表。已修剪 INT8 模型可以提供最高的推論傳輸量。
以下表 1 所示為在此資料集上測量的網路架構和準確率。
| 模型 | 網路架構 | 類別數量 | 準確率 | 使用案例 |
| DashCamNet | DetectNet_v2-ResNet18 | 4 | 80% | 從移動物件,例如汽車或機器人中識別物件 |
| FaceDetect-IR | DetectNet_v2-ResNet18 | 1 | 96% | 在黑暗環境中偵測靠近攝影機的臉孔 |
| PeopleNet | DetectNet_v2-ResNet34 | 3 | 84% | 計算人數、產生熱圖、社交距離 |
| TrafficCamNet | DetectNet_v2-ResNet18 | 4 | 83.5% | 偵測和追蹤汽車 |
| VehicleMakeNet | ResNet18 | 20 | 91% | 分類車型 |
| VehicleTypeNet | ResNet18 | 6 | 96% | 在停車場或收費站中為汽車分類 |
TrafficCamNet
TrafficCamNet 是以 NVIDIA detectnet_v2 架構為基礎,使用 ResNet18 做為骨幹特徵擷取器的四類別物件偵測網路。它是在 544×960 RGB 影像上接受訓練,可以偵測汽車、人、道路標誌和二輪車輛。
資料集包含來自美國城市交通路口的真實影像(位於大約 20 英尺的制高點)。訓練此模型的目的,是為了克服汽車停等紅燈或遇到停車標誌時分隔整排汽車的問題。此模型適用於需要計算路上之汽車數量,並瞭解交通流量的智慧城市應用。
PeopleNet
PeopleNet 是以 NVIDIA detectnet_v2 架構為基礎,使用 ResNet34 或 ResNet18 做為骨幹特徵擷取器的三類別物件偵測網路。它是在 544×960 RGB 影像上接受訓練,可以偵測人、包包和臉孔。其內部標示了數百萬張室內與室外場景的影像,以適應機場、購物中心、零售店等各種使用案例。
此資料集包含來自各個制高點的影像。PeopleNet 可使用於必須在擁擠環境中準確計算人數,以獲得保全或概略性商業見解的智慧場所或建築應用。
DashCamNet
DashCamNet 是以 NVIDIA detectnet_v2 架構為基礎,使用 ResNet18 做為骨幹特徵擷取器的四類別物件偵測網路。它是在 544×960 RGB 影像上接受訓練,可以偵測汽車、行人、交通標誌和二輪車輛。
此網路的訓練資料,包含從位於大約 4-5 英尺制高點之不同行車記錄器內部收集、標註和整理的真實影像。有別於其他模型,此範例中的攝影機為持續移動。此模型之使用案例是從移動的物件,例如汽車或機器人中識別物件。
FaceDetect-IR
FaceDetect_IR 是以 NVIDIA detectnet_v2 架構為基礎,使用 ResNet18 做為骨幹特徵擷取器的單類別人臉偵測網路。此模型是在 384x240x3 IR 紅外線影像上接受訓練,並以合成雜訊為輔助。
此模型是為了人臉靠近攝影機的使用案例而訓練,例如視訊會議期間的筆記型電腦攝影機,或置於車內以觀察駕駛員是否分心的攝影機。在使用紅外線照明器時,即使可見光條件對一般彩色攝影機而言太暗,此模型也可以繼續運作。
VehicleMakeNet
VehicleMakeNet 是以 ResNet18 為基礎的分類網路,目的是針對大小為 224 x 224 的汽車影像進行分類。此模型可以識別 20 種熱門的汽車品牌。
VehicleMakeNet 通常與 DashCamNet 或 TrafficCamNet 串聯,用於智慧城市應用。例如,DashCamNet 或 TrafficCamNet 可以做為偵測目標物件的主要偵測器,而VehicleMakeNet可在偵測到每一輛汽車時,做為確定汽車品牌的次要分類器。智慧停車場或加油站等業者可以使用車輛品牌見解,瞭解客戶。
VehicleTypeNet
VehicleTypeNet 是以 ResNet18 為基礎的分類網路,目的是將大小為 224 x 224 的裁切後車輛影像分成六類:轎跑車、大型車輛、轎車、SUV、貨車、廂型車。此模型的典型使用案例為智慧城市應用,例如智慧停車場或收費站,可以根據車輛的大小收費。
訓練 PeopleNet 模型
如果您沒有 NVIDIA NGC 帳戶,請先建立帳戶。首先提取遷移學習工具套件容器:
請使用以下命令,查看可用模型的清單:
請使用以下命令,下載需要的模型,例如 PeopleNet:
$model_path

完整的工作流程包含以下步驟:
- 準備資料
- 配置規格檔案
- 訓練
- 修剪
- 匯出模型
準備資料
遷移學習工具套件(TLT)物件偵測器以 KITTI 檔案格式接收資料。通常,有許多影像檔案和關聯的標籤檔案為影像中之物件提供標籤,以及定界框四個角的對應座標。此配置必須存取這些檔案的記憶體。您需要更佳的配置,以加快處理速度。
請使用 TFrecords 更有效地管理及更快速地迭代資料集。將資料序列化特別有助於透過網路快速讀取資料。使用以下目錄結構將原始資料格式化:
|– images |– 000000.jpg |– 000001.jpg |– xxxxxx.jpg |– labels |– 000000.txt |– 000001.txt |– xxxxxx.txt請建立轉換組態檔,將資料集轉換成 TFrecords。訓練需要一個轉換檔案,而模型評估需要另一個轉換檔。
以下程式碼範例為訓練資料集轉換組態檔:
root_directory_path: “/path/to/trainval_root” image_dir_name: “images” label_dir_name: “labels” image_extension: “.jpg” partition_mode: “random” num_partitions: 2 val_split: 14 num_shards: 10 }使用 kitti_config,將資料集隨機分成兩個分割區:訓練和驗證。這是藉由 partition_mode 和 num_partitions keys 值設定。val_split 選項指定用於驗證的資料百分比。
同樣地,想要將測試集轉換成 TFRecords時,轉換檔案應如以下程式碼範例所示:
tlt-dataset-convert -d $conversion_spec_file_test -o $tfrecord_path_test
雖然已有 val_split 值,仍可使用規格檔案中的 validation_data_source 評估整體測試集,將會在下一節進行討論。
root_directory_path: “/path/to/test_root” image_dir_name: “images” label_dir_name: “labels” image_extension: “.jpg” partition_mode: “random” num_partitions: 2 val_split: 14 num_shards: 10 }image_directory_path: “/path/to/test_root”
現在,將兩個資料集轉換成 TFrecords:
tlt-dataset-convert -d $conversion_spec_file_test -o $tfrecord_path_test
配置規格檔案
必須使用規格檔案,編譯訓練和評估模型需要的所有超參數。如前所述,PeopleNet 是以專有的 DetectNet_v2 架構為基礎。DetectNet_v2 的範例組態檔包含下列主要模組:
- dataset_config
- model_config
- training_config
- augmentation_config
- postprocessing_config
- evaluation_config
- box_rasterizer_config
- cost_function_config
Dataset config
PeopleNet 規格檔案的 dataset_config 模組格式,如下所示:
data_sources: {
tfrecords_path: “/path/to/trainval_tfrecords/*” image_directory_path: “/path/to/trainval_root”}
image_extension: “jpg”
target_class_mapping {
key: “person” value: “person”}
target_class_mapping {
key: “face” value: “face”}
target_class_mapping {
key: “bag” value: “bag”}
validation_fold: 0
# For evaluation on test set
# validation_data_source: {
#
tfrecords_path: “/path/to/test_tfrecords/*”#
image_directory_path: “/path/to/test_root”# }
請使用 validation_fold 指定驗證資料。在測試資料方面,可以使用 validation_data_source。
模型配置
可以使用 model_config 模組,配置模型結構和相關超參數。視選擇的架構而定,架構或骨幹的超參數可能不同。
PeopleNet 使用 ResNet34。透過凍結卷積層,凍結層中的權重不會在損失更新期間發生變化。此特別有助於轉移學習,您可以重複使用預先訓練權重提供的功能,以及縮短訓練時間。
model_config {
pretrained_model_file: “/path/to/pretrained/model” num_layers: 34 freeze_blocks: 0 arch: “resnet” use_batch_norm: true objective_set { bbox { scale: 35.0 offset: 0.5 } cov { } } training_precision { backend_floatx: FLOAT32 }}
訓練配置
顧名思義,訓練配置模組是用於指定批次大小、學習率、正則化器、最佳化器等常見的超參數。
從低正則化權重開始是較好的做法。逐漸微調以縮小訓練與驗證準確性之間的差距。
batch_size_per_gpu: 24
num_epochs: 120
learning_rate {
soft_start_annealing_schedule { min_learning_rate: 5e-06 max_learning_rate: 0.0005 soft_start: 0.1 annealing: 0.7 }}
regularizer {
type: L1 weight: 3e-09}
optimizer {
adam { epsilon: 9.9e-09 increment: 0.005 decrement: 1.0}
checkpoint_interval: 10
}
擴增配置
擴增模組可在訓練期間,提供一些基本的快速資料預處理和擴增。PeopleNet 訓練管道是採用包含水平翻轉、基本色彩和轉譯擴增的 544×960 RGB 影像做為輸入。
preprocessing { output_image_width: 960 output_image_height: 544 crop_right: 960 crop_bottom: 544 min_bbox_width: 1.0 min_bbox_height: 1.0 } spatial_augmentation { hflip_probability: 0.5 zoom_min: 1.0 zoom_max: 1.0 translate_max_x: 8.0 translate_max_y: 8.0 } color_augmentation { hue_rotation_max: 25.0 saturation_shift_max: 0.20000000298 contrast_scale_max: 0.10000000149 contrast_center: 0.5 }}
後處理配置
後處理器模組是從原始偵測輸出產生可渲染的定界框。此流程是使用覆蓋張量中之信賴度值,將物件閾值化,並使用各類別之分群演算法獨立將候選定界框分群,以保留有效的偵測。在 DetectNet_v2 中,是使用 density-based spatial clustering of applications with noise(DBSCAN)。
dbscan_eps(ε)值越大,聚集在一起的框越多。
target_class_config{ key: “person” value: { clustering_config { coverage_threshold: 0.005 dbscan_eps: 0.265 dbscan_min_samples: 0.05 minimum_bounding_box_height: 4 } } } target_class_config{ key: “bag” value: { clustering_config { coverage_threshold: 0.005 dbscan_eps: 0.15 dbscan_min_samples: 0.05 minimum_bounding_box_height: 4 } } } target_class_config{ key: “face” value: { clustering_config { coverage_threshold: 0.005 dbscan_eps: 0.15 dbscan_min_samples: 0.05 minimum_bounding_box_height: 4 } } }}
欲深入瞭解如何設定 cost_function_config 和 box rasterizer_config ,以及不同的超參數,請參閱轉移學習工具套件智慧影像分析入門指南。
訓練
在完成資料準備及配置規格檔案之後,即可開始進行訓練。使用以下指令:
如果使用任何專用模型做為預先訓練權重時,請務必將 $KEY 設為 tlt_encode。
tlt-train 命令在實驗目錄中產生經過 KEY 加密的模型和訓練紀錄。它可以支援多 GPU 訓練,因此可以平行使用多個 GPU 訓練模型。使用多個 GPU 進行訓練,可以讓網路在更短的時間內吸收大量資料及訓練模型。您可以在紀錄或 monitor.json 檔案中查看訓練進度。
在完成初始訓練之後,下一步是評估模型的準確性。若想要評估剛才訓練或重新訓練的 PeopleNet 模型時,請使用 tlt-evaluate。
規格檔案中的 evaluation_config 模組,專用於為各類別配置各種進行評估的閾值。請記住更新 dataset_config 中的 validation_data_source,以指向測試集。
validation_period_during_training: 10 first_validation_epoch: 120 minimum_detection_ground_truth_overlap { key: “bag” value: 0.5 } minimum_detection_ground_truth_overlap { key: “face” value: 0.5 } minimum_detection_ground_truth_overlap { key: “person” value: 0.5 } evaluation_box_config { key: “bag” value { minimum_height: 40 maximum_height: 9999 minimum_width: 4 maximum_width: 9999 } } evaluation_box_config { key: “face” value { minimum_height: 2 maximum_height: 9999 minimum_width: 2 maximum_width: 9999 } } evaluation_box_config { key: “person” value { minimum_height: 40 maximum_height: 9999 minimum_width: 4 maximum_width: 9999 } }}
在設定 evaluation_config 和 dataset_config 值之後,即可評估模型。
所有偵測框架都是使用平均的精度均值(mean average precision,mAP)做為共同指標。平均精度(AP)計算模式可以是 SAMPLE 或 INTEGRATE。
- SAMPLE 做為 VOC 2009 或先前版本的 VOC 指標使用時,AP 是被定義為 11 個等距召回率之集合的精度均值。
- INTEGRATE 做為 VOC 2010 或以後之版本使用時,AP 是精度和召回率的曲線下面積(area under curve,AUC)直接估計值。請使用 INTEGRATE,因為它是更佳的模型評估指標。
測試集的 tlt_evaluate 輸出,如下所示:
class mAP
=========
person 94.19
bag 75.93
face 94.59
修剪
使用修剪,可以將參數數量減少一個數量級,以使模型變得更精簡,而不會影響模型本身的整體準確性。此技巧可以使推論變得更快速,進而提高影像畫格的推論傳輸量。
修剪分成兩個步驟:修剪模型以及重新訓練模型。最初在修剪模型時,會失去一些準確性。但是,您可以使用資料集重新訓練模型,以再次獲得準確性。
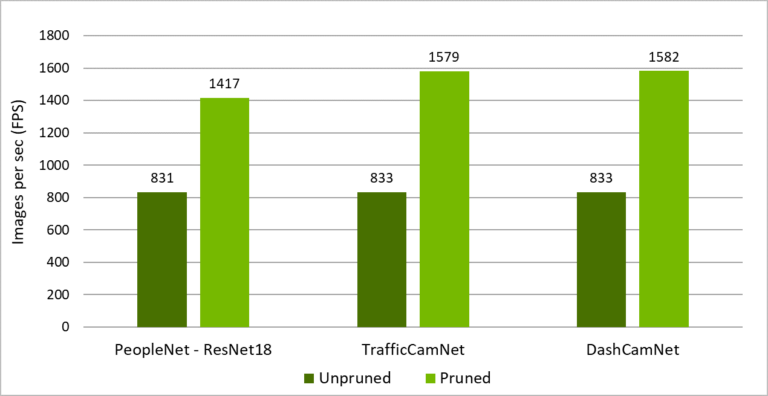
圖 3 所示為 PeopleNet、TrafficCamNet 和 DashCamNet 的推論傳輸量,包括未修剪和已修剪模型。使用資料集進行修剪,可以將傳輸量提高 2 至 3 倍。
修剪主要是取決於網路和資料集的架構。通常,資料集越大,可以修剪的幅度越大,同時可維持相當的準確性。在修剪後重新訓練時,較小的資料集可能會過度擬合。
修剪是使用 tlt-prune 命令中的選項 -pth,透過修剪閾值進行控制。修剪閾值越高,修剪的幅度越大,越可能會降低模型的整體準確性。應使用此超參數進行實驗,找出修剪與模型準確性之間的平衡點。
若想要修剪 PeopleNet 模型時,請使用 tlt-prune 命令:
從 tlt-prune 的輸出,即可知原始模型的修剪幅度:
在此範例中,可以修剪大約 88%。修剪後之模型大小為原始模型的八分之一。
在修剪之後,必須重新訓練模型,以再次獲得準確性,因為在修剪過程中可能會移除一些有用的連接。若想要微調修剪後的模型,請務必將規格檔案中的 pretrained_model_file 參數設為已修剪模型路徑,然後執行 tlt-train。
在完成微調之後,可以使用 tlt-evaluate ,評估修剪後的模型。以下為範例結果:
class mAP
=========
person 95.74
bag 79.17
face 96.76
現在的模型大小是原有模型的十分之一,同時可維持相當的準確性。當您對模型有信心時,下一步是匯出,以進行部署。
匯出模型
最後一步是匯出經過訓練的模型,以進行部署。部署格式為 .etlt 或加密遷移學習工具套件。使用金鑰為匯出的模型進行加密,並在部署期間使用該金鑰為模型進行解密。
若想要使用 INT8 精度執行推論,則可在模型匯出步驟中產生 INT8 校正表。在 DeepStream SDK 中可以直接使用加密遷移學習工具套件 。
若想要以 INT8 匯出 PeopleNet 模型時,請使用以下命令:
-e $spec_file -k $KEY –cal_image_dir $calibration_image_dir –data_type int8
–batch_size N –batches 10 –cal_cache_file $calibration_table
–cal_data_file $calibration_data_cache
使用 DeepStream SDK 進行模型部署
DeepStream SDK 是串流分析工具套件,可以建構理解視訊和影像的人工智慧應用程式。DeepStream SDK 可以協助建構最佳化的工作流程,以串流視訊資料做為輸入,並使用人工智慧輸出見解。它提供了經過遷移學習工具套件(TLT)訓練模型的整合。
首先下載與安裝 DeepStream 5.0 開發人員預覽版。在 /samples 目錄中找出組態檔,執行 DeepStream 應用程式:
請使用 DeepStream SDK 內建的端對端可配置應用程式 deepstream-app,執行人工智慧模型。在此應用程式中,可以配置輸入來源、輸出接收器和人工智慧模型。此應用程式可以直接使用具有加密金鑰的 .etlt 模型。
您也可以提供 INT8 校正表,以使用 INT8 精度執行推論。請使用 NVIDIA 高效能推論執行階段 TensorRT,以進行推論。為了使用 TensorRT 進行推論,DeepStream 會先將具有加密金鑰的 .etlt 檔案轉換成 TensorRT 引擎檔案。
在產生引擎檔案之後,將會啟動工作流程。初次產生引擎檔案可能需要幾分鐘或更長時間,視平台而定。此外您也可以直接提供 TensorRT 引擎檔案給 DeepStream SDK。若想要將加密 .etlt 檔案轉換成 TensorRT 引擎,請使用 tlt-converter。如果在搭載 NVIDIA GPU 的 x86 上執行 DeepStream,則可以從遷移學習工具套件容器使用 tlt-converter。如果在 NVIDIA Jetson 上執行時,可以另外下載以 ARM64 為基礎的 tlt-converter。
通常需要多個配置檔,才能執行 deepstream-app。其中之一是為整個工作流程設定參數的頂層配置檔,其他則是用於推論的配置檔。為了確保使用性和簡易性,每一個推論引擎都需要一個唯一配置檔。如果串聯多個推論,則必須具有多個配置檔。此範例是使用以下檔案:
- deepstream_app_source1_peoplenet.txt
- config_infer_primary_peoplenet.txt
- labels_peoplenet.txt
模型名稱和加密金鑰是在 config_infer_primary_peoplenet.txt 檔案中指定。變更下列主要參數:
tlt-encoded-model=
tlt-model-key=
labelfile-path=
int8-calib-file=
input-dims=
num-detected-classes=<# of classes>
現在,執行應用程式:
應開啟範例影片的快顯視窗,在行人和人臉周圍呈現出定界框。
您也可以變更每一個類別的偵測閾值,以改善偵測或完全取消想要偵測的物件。欲深入瞭解這些參數,請參閱 NVIDIA DeepStream SDK 快速入門指南和 NVIDIA DeepStream 外掛程式手冊。
結論
本文章介紹了六種高準確率模型,教導您使用經過手動標示,以提供基準真相(ground truth)的大型資料集訓練。這些模型可以做為預先訓練模型使用,以進行進一步的轉移學習,也可以直接在您的產品中使用。NGC 提供未修剪模型和較小的已修剪模型。
我們是以 PeopleNet 為範例,引導您完成一些簡單的步驟,包括訓練、評估、修剪、重新訓練和匯出模型。DeepStream SDK 工作流程可以直接使用產生的模型,推論應用程式。
它可以在搭載 T4 或其他 Tesla GPU 的伺服器,以及 Jetson 邊緣裝置上運作,例如 Nano 或 Xavier 系列裝置。您也可以產生 INT8 校正檔案,以使用 INT8 精度執行推論。修剪加上 INT8 精度,可以在邊緣裝置上提供最高的推論效能。
若需要更多資訊,請參閱以下資源:
-
- 轉移學習工具套件和預先訓練模型
- DeepStream SDK
- 文章
- 在遷移學習工具套件(TAO Toolkit)開發人員論壇或 DeepStream 開發人員論壇上提出問題或意見
- 採用遷移學習工具套件(TLT)和 DeepStream 的 Jetson 開發人員社群專案
- 由 NVIDIA 深度學習學院(DLI)認證講師手把手帶領的實作課程:運用於智慧影片分析的深度學習技術