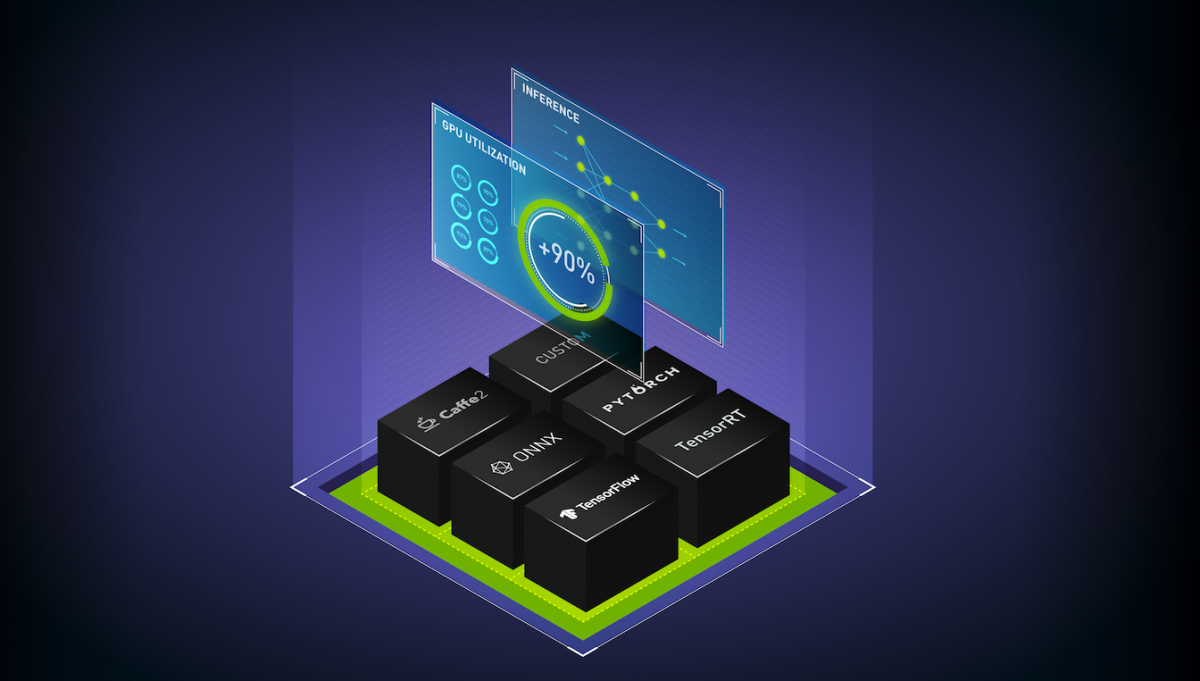
AI、機器學習以及深度學習,是解決產品推薦、客戶互動、財務風險評估、製造瑕疵偵測等各種運算問題的有效工具。在實際場域中使用 AI 模型,又稱為推論服務,是將 AI 整合至應用程式中最複雜的部分。NVIDIA Triton 推論伺服器可負責推論服務的所有流程,讓您能專注於開發應用程式。
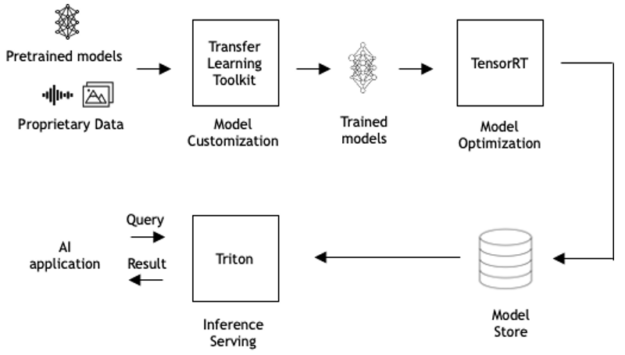
高效率推論服務
每一個 AI 應用都需要推論服務,但事實上推論服務十分複雜,原因如下:
- 單一應用程式可能使用來自不同 AI 框架的多個模型,以及各種預處理和後處理步驟。推論服務必須能支援多個框架後端。
- 需求有多種類型:
- 即時(線上)– 推論服務會受到延遲限制。
- 批次(離線)– 推論服務可提供高傳輸量。
- 串流 – 推論服務必須保留查詢順序。
- 模型可以在公有雲、資料中心或企業邊緣端的 GPU 和 CPU 基礎架構上執行。
- 模型必須以最佳的方式擴充,以滿足應用程式的需求。
- 必須監控模型狀態及解決問題,以防止停機。
- 必須將多個 KPI 最佳化:硬體利用率、模型推出時間和 TCO。
推論服務解決方案可以處理其中一些複雜事項,但是缺少許多進行高效率推論服務的最佳化方式。
Triton 推論伺服器
Triton 是一款高效率推論伺服軟體,讓您能專注於開發應用程式。此軟體是屬於開放原始碼軟體,可以使用所有的主要框架後端進行推論:TensorFlow、PyTorch、TensorRT、ONNX Runtime,甚至以 C++ 和 Python 編寫的自訂後端。它可以在三個方面,將推論最佳化。
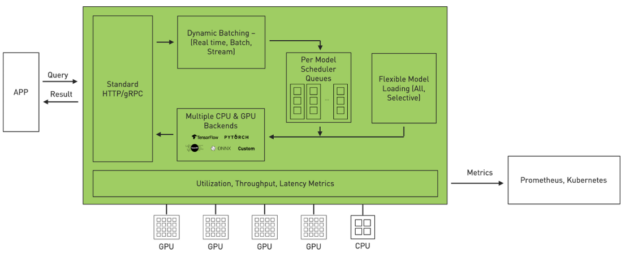
- 利用率:Triton 可以在 GPU 或 CPU 上部署模型。它可以使用動態批次處理和並行模型執行等功能,將 GPU/CPU 利用率最大化。
- 擴充性:Triton 是透過以微服務為基礎的推論,提供資料中心和雲端規模。它可以部署容器化微服務,在 GPU 和 CPU 上提供預處理或後處理以及深度學習模型。每一個 Triton 執行個體都可以在類似 Kubernetes 的環境中獨立擴充,以達到最佳效能。使用 NGC 的單一 Helm 指令,可以將 Triton 部署在 Kubernetes 中。
- 應用程式體驗:Triton 具有可以讓應用程式進行通訊的標準 HTTP/REST 和 gRPC 端點。Triton 可支援即時、批次和串流推論查詢,以提供最佳的應用程式體驗。在實際使用時,無須中斷應用程式即可於 Triton 中更新模型。Triton 提供高傳輸量推論,同時使用動態批次處理和並行模型執行,以符合嚴格的低延遲考量。
發表 Triton 2.3
我們很高興能發表 Triton 推論伺服器 2.3 版。此版本導入了重要功能,進一步簡化擴充式推論服務:
- Kubernetes 無伺服器推論
- 支援框架後端的最新版本:TensorRT 7.1、TensorFlow 2.2、PyTorch 1.6、ONNX Runtime 1.4
- Python 自訂後端
- 支援 NVIDIA A100 和 MIG
- 解耦推論服務
- Triton Model Analyzer
- 整合 Microsoft Azure Machine Learning
- 整合 NVIDIA DeepStream
Kubernetes 無伺服器推論
Triton 是第一款採用 KFServing 最新社群標準 gRPC 和 HTTP/REST 資料平面 v2 協定的推論服務軟體。KFServing 是 Kubernetes 上,以標準為基礎的無伺服器推論。
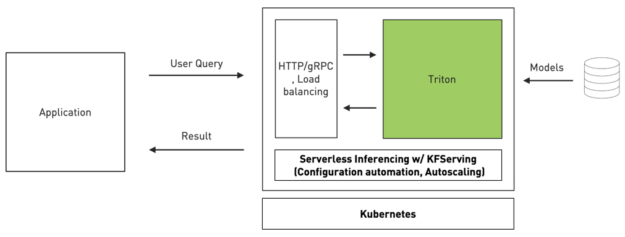
透過配置自動化和自動擴充,可簡化 Kubernetes 中的推論服務部署。並以透明化方式處理負載尖峰,因此即使要求大幅增加數量,也會持續流暢地執行服務。現在,組織可以透過此類新的整合,在 Kubernetes 環境中使用 Triton 輕鬆地部署高效能推論。
以下程式碼範例是示範如何使用 Triton 部署 BERT 模型。InferenceService 是 KFServing 導入的自訂資源,您可以在其中將類型指定為 triton 的預測器。 如您所見,使用 KFServing 和 Triton ,僅需要大約 30 行,即能在 Kubernetes 中建置可擴充的推論服務。
kind: “InferenceService”
metadata:
name: “bert-large”spec:
default: transformer: custom: container: name: kfserving-container image: gcr.io/kubeflow-ci/kfserving/bert-transformer:latest resources: limits: cpu: “1” memory: 1Gi command: – “python” – “-m” – “bert_transformer” env: – name: STORAGE_URI value: “gs://kfserving-samples/models/triton/bert-transformer” predictor: triton: resources: limits: cpu: “1” memory: 16Gi nvidia.com/gpu: 1 storageUri: “gs://nv-enterprise/trtis_models/”利用 KFServing,可以透過定義轉換器,輕鬆地在部署中加入權杖化等預處理步驟以及後處理。 若需要更多資訊,請參閱 GitHub 上的 samples/triton/bert example。
Python 自訂後端
除可支援 C 和 C++ 應用程式的現有自訂後端環境外,Triton 亦可增加新的 Python 自訂後端。Python 自訂後端的功能十分強大,因為它可以在 Triton 內部執行任何的任意 Python 程式碼。使用 Python 程式碼的常見情境是針對神經網路進行預處理和後處理,以修改張量結構,例如旋轉或裁切影像,或為推薦器工作負載進行特徵工程。使用 Triton 中現有的模型整合功能,在深度學習框架後端進行神經網路推論之前和之後,可以執行 Python 程式碼。
支援 A100 和 MIG
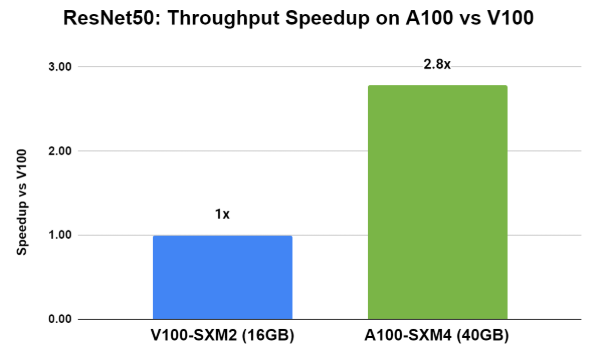
NVIDIA A100 帶來的突破性技術,例如第三代 Tensor 核心,可以多執行個體 GPU (MIG) 在執行各種工作負載時提升所有精度運算,以及可以將單一 A100 分成多達七個 GPU 執行個體,以最佳化 GPU 利用率,並讓更多使用者存取。在 A100 上使用 Triton 進行推論的效能高於 V100(圖 4)。在使用 ResNet50 PyTorch 模型的情況下,A100 搭配 Triton 的傳輸量和延遲,比 V100 快將近 3 倍。
您也可以使用 Triton,透過效能和故障隔離,在個別 MIG 執行個體上執行推論。
解耦推論服務
語音辨識、語音合成等新興使用案例需要採用此功能,在這些使用案例中,推論結果不是取決於完成完整的推論要求。在此類解耦模式下運作的模型,可以逐一要求決定為該要求產生多少回應。例如,在語音辨識中,用戶端可以在任何時間,以不同的速率和不同的樣本數量,將音訊樣本傳送至推論伺服器。解耦模式可以讓 Triton 在收到足夠,但是非所有輸入後啟動模型。在 2.3 版中,此功能僅適用於 C/C++ 自訂後端。
Riva 對話式 AI 平台利用解耦推論服務功能已開放公測。若需要更多資訊和早期試用,請在 NVIDIA Riva 註冊。
Triton Model Analyzer
Tridon 推論伺服器 2.3 版的關鍵功能為 Triton Model Analyzer,可用於分析模型效能和記憶體佔用空間的特性.以實現高效率服務。它是由兩個工具所組成:
- Triton perf_client 工具已改名為 perf_analyzer。其有助於針對各種批次大小和推論同時請求數量,分析模型之傳輸量和延遲的特性。
- 新的記憶體分析器功能,有助於針對各種批次大小和推論同時請求數量,分析模型之記憶體佔用空間的特性。
此處為 perf_analyzer 的輸出範例,有助於確定模型的最佳批次和同時請求數量,以顯示出批次大小、延遲百分比、傳輸量以及並行詳細資訊。
Batch size: 1 Measurement window: 5000 msec Latency limit: 0 msec Concurrency limit: 4 concurrent requests Stabilizing using average latencyRequest concurrency: 1 Client: Request count: 804 Throughput: 160.8 infer/sec Avg latency: 6207 usec (standard deviation 267 usec) p50 latency: 6212 usec…
Request concurrency: 4
Client: Request count: 1042 Throughput: 208.4 infer/sec Avg latency: 19185 usec (standard deviation 105 usec) p50 latency: 19168 usec p90 latency: 19218 usec p95 latency: 19265 usec p99 latency: 19583 usec Avg HTTP time: 19156 usec (send/recv 79 usec + response wait 19077 usec) Server: Request count: 1250 Avg request latency: 18099 usec (overhead 9 usec + queue 13314 usec + compute 4776 usec)
Inferences/Second vs. Client Average Batch Latency
Concurrency: 1, 160.8 infer/sec, latency 6207 usec
Concurrency: 2, 209.2 infer/sec, latency 9548 usec
Concurrency: 3, 207.8 infer/sec, latency 14423 usec
Concurrency: 4, 208.4 infer/sec, latency 19185 usec
Triton 記憶體分析器具備許多優點,例如以最佳方式將模型分配至 GPU,以避免在執行中發生記憶體不足的錯誤,並可最佳化模型的記憶體使用以改善效能,以及為模型分配合適的 GPU 資源。如圖 6 顯示來自於記憶體分析器,有助於確定需要載入至 GPU 記憶體,以進行推論服務之模型執行個體數量的範例輸出。

整合 Microsoft Azure Machine Learning
客戶可以在 Microsoft Azure Machine Learning 上使用 Triton,以獲得高效能推論,並在推論過程中,以更具成本效益的方式利用 GPU。Triton 的優點包括動態批次處理、在 GPU 上並行工作、支援 CPU,以及包含 ONNX Runtime 的多個框架後端。Azure Machine Learning 提供中央登錄和 MLOps 功能,可以自動為已部署模型及其他機器學習資產提供版本追蹤和稽核軌跡。請參閱文件,以瞭解如何在 Azure Machine Learning 中使用 Triton。
整合 NVIDIA DeepStream
NVIDIA DeepStream SDK 是使用於以 AI 為基礎之多感測器處理、視訊和影像理解的完整串流分析工具套件。您可以使用 DeepStream 5.0 與 Triton 的原生整合,從 TensorRT 之外的多個深度學習框架部署模型,針對 NVIDIA T4 和 Jetson 平台進行快速原型設計。若需要更多資訊,請參閱使用 NVIDIA DeepStream 5.0 建構智慧影像分析應用程式。
客戶使用案例
此處為客戶使用 Triton 的方式。
微軟(Microsoft)
Microsoft 使用 AI 為 Microsoft Word 線上使用者提供文法建議。他們希望能以最先進的準確性和速度,使用符合成本效益之方式部署運算複雜的深度學習模型。即時文法建議需要在 200 毫秒以下的嚴格延遲效率。
他們透過 Triton 和 ONNX Runtime,在 Azure Machine Learning 和 NVIDIA V100 GPU 上使用即時推論。Triton 可以利用動態批次處理、並行執行以及 ONNX Runtime 整合,提供高傳輸量(在一個 V100 上每秒 450 次推論)和低延遲 (200 毫秒)。他們可以在 Azure Machine Learning Compute V100 GPU 上,將成本降低三分之一。若需要更多資訊,請參閱微軟在 Word Online 版本內採用 NVIDIA 的人工智慧技術來提出文法建議。
美國運通(American Express)
American Express 服務擁有 1.44 億張卡,每年產生超過 80 億筆交易。他們希望能建構和部署即時(不到 2 毫秒)的詐騙偵測系統,使用機器學習和深度學習提高準確性。
他們使用 Triton 部署經過 TensorRT 最佳化的 GRU 模型,使用配備 T4 的伺服器分析數千萬筆日常交易。經強化的即時詐騙偵測系統可在 2 毫秒的低延遲範圍內運作,相較於無法滿足延遲需求的 CPU,改善達 50 倍。
Naver
Naver 是南韓頂尖的搜尋引擎和網際網路服務公司。他們將深度學習使用於即時影像分類、搜尋建議及其他用途中。使用多個框架(TensorFlow、PyTorch、Caffe 和 TensorRT)會減緩即時導入新 AI 模型的速度。此外,其管理成本高昂。
他們採用 Triton,因為其可支援多個框架,以及在 GPU 和 CPU 上進行即時、批次和串流推論。Triton 為他們提供單一推論平台,可以更快速地從多個框架推出新的深度學習模型,並能降低 Naver 的營運成本。
矽品(SPIL)
SPIL 是全球最大的外包半導體組裝和測試公司。他們提供晶圓凸塊服務,每天在單一生產線上檢測大約 30,000 張晶圓影像是否有瑕疵。目前,他們的自動光學檢測(AOI)平台會產生 70% 的假陽性,而需要進行第二次篩選。
SPIL 是使用深度學習模型(U-Net、DenseNet 和 Autoencoder),以 NVIDIA T4 GPU、TensorRT 和 Triton 進行第二層篩選。現在他們可以 100% 偵測出所有組裝線晶圓的瑕疵,且假陽性不到 10%。Triton 的動態模型載入和解除載入可以協助他們擴充至 100 種不同的模型,且無須變更伺服基礎架構。
Tracxpoint
Tracxpoint 是一家零售技術公司,創造出搭載深度學習的實體購物車,稱為 AiC。購物者可以使用 AiC,將產品放入購物車中,就能即時獲得個人化產品報價、輕鬆逛超市,並以數位方式付款。
Tracxpoint 在 NVIDIA T4 Tensor 核心 GPU 上利用經過 TensorFlow 和 TensorRT 最佳化的模型,使用 Triton 進行即時推論。AiC 可以在一秒內,辨識 100,000 種產品。模型每天都會重新接受訓練,且 Tracxpoint 可以在 Triton 中無縫更新模型,且不會干擾使用者。
結論
Triton 簡化了生產中的大規模 AI 和深度學習模型部署。其可支援所有的主要框架、並行執行多個模型,以提高傳輸量和利用率,以及支援 GPU 和 CPU,並與 Kubernetes 整合,以進行擴充式推論。
請從 NGC 下載 Triton 推論伺服器 2.3 版,並從 triton-inference-server/server GitHub 儲存庫取得原始碼。