
沒人會嫌自己太富有或太瘦,這是溫莎公爵夫人的名言。在嘗試配合深度學習應用程式與運算資源時,即會獲得類似的結論:處理能力永不嫌多。
現在,可以透過訓練複雜的神經網路應對,以解決金融、安全、醫學研究、資源探勘、自動駕駛車、國防等領域的棘手問題,而不是使用傳統電腦進行程式設計,以採取明確的步驟。即使這一門學問仍相對年輕,但是結果卻令人驚訝。
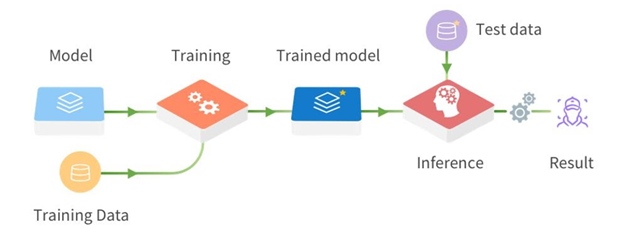
將深度學習模型變成電腦化智慧需要的訓練過程,極度耗費資源。必要作業的基本構件是 GPU。儘管它們已經很強大,且在不斷強化,但是,我先前提到的各種應用具有永無止盡的需求。
為了獲得需要的處理能力,必須平行使用 GPU,這就是問題所在。想要啟用更多 GPU,最簡單的方式是直接將它們加入系統中。但是,此縱向擴充方法具有一些實際的限制。在合理的實體、電力和功耗限制下,僅能將一定數量的強大猛獸放入單一系統中。如果需要更多(也確實需要更多),則必須橫向擴充。
這意味者在一個叢集中提供多個節點。為了發揮效用,節點必須共用 GPU。問題解決了,對吧?有可能,但是此方法會帶來一些新的挑戰。基本挑戰為直接將一大群運算節點組合成大型叢集,並使它們合作無間,不是一件容易的事。事實上,如果處理不當,則效能可能會隨著 GPU 的數量增加而變差,且成本可能會變得不具吸引力。
NVIDIA 與 One Convergence 合作,解決了與有效率地擴充內部部署或裸機雲端深度學習系統有關的問題。NVIDIA 端對端乙太網路解決方案已超越最嚴苛的標準,使競爭對手望塵莫及。例如,可以明顯看到 TensorFlow 在 NVIDIA 100 GbE 網路上,相較於 10 GbE 網路的效能優勢,且兩者都是利用 RDMA(圖 2)。
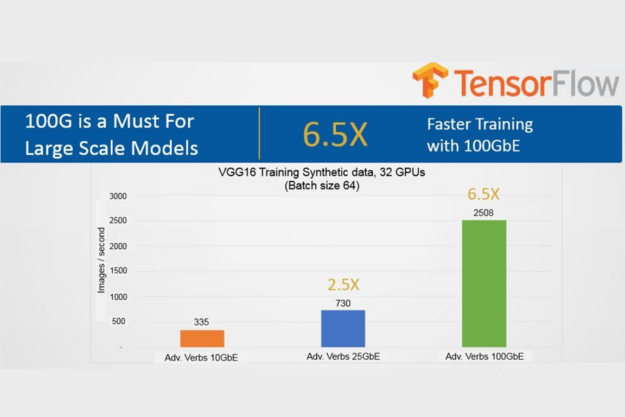
RDMA over Converged Ethernet(RoCE)是一種讓 RDMA 可以在乙太網路上進行高效率資料傳輸的標準協定。其允許透過硬體 RDMA 引擎建置和優異的效能進行傳輸卸載。雖然分散式 TensorFlow 充分利用了 RDMA 消除處理瓶頸(即使是大規模影像也不例外),但是 NVIDIA 100GbE 網路仍可從 32 個 NVIDIA P100 GPU 提供預期的效能和出色的擴充性。但在 25 GbE 和 100 GbE 方面,顯然地仍在使用 10 GbE 的人,無法體驗他們預期的投資報酬。
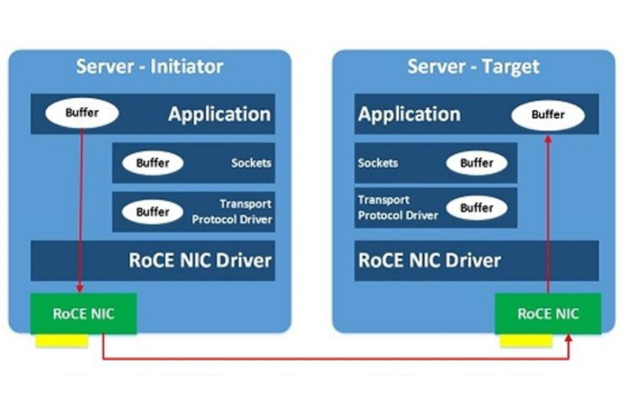
除了效能優勢外,在 NVIDIA 25、50 或 100 GbE 上執行 AI 工作負載的經濟效益也很可觀。NVIDIA Spectrum 交換器和 NVIDIA ConnectX SmartNIC 提供了無可比擬的效能,且價格更是無可比擬,可以帶來極高的 ROI。NVIDIA 端對端乙太網路解決方案具有彈性的連接埠數量和纜線選項,在 1U 機架空間最多可以容納 64 個全備援 10/25/50/100 GbE 連接埠,適合希望將資料價值最大化的先進資料中心。
系統的效能和成本是基本要求,但是,具吸引力的內部部署深度學習平台必須能更進一步:
- 提供共用 GPU 的機制,讓使用者或應用程式不會壟斷或缺乏資源。
- 確保盡可能充分利用 GPU。
- 將識別各節點上的資源,以及使它們立即可用的過程自動化,而無須大量的手動介入或調整。
- 使整體系統易於使用,因為在任何人群中,專家永遠是少數。
- 將系統建立在同類型中最佳的開放平台上,以提升易用性,並在推出更好的框架和演算法時,迅速進行整合。
對於可以將運算需求轉移至公用雲端的組織而言,已經克服了許多挑戰。對於因法規、競爭、安全性、頻寬或成本,而無法採取此途徑的公司而言,則沒有理想的解決方案。
為了達成先前所述的目標,One Convergence 建立了稱為 DKube 的全堆疊深度學習即服務應用程式,為內部部署和裸機雲端使用者解決了這些挑戰。
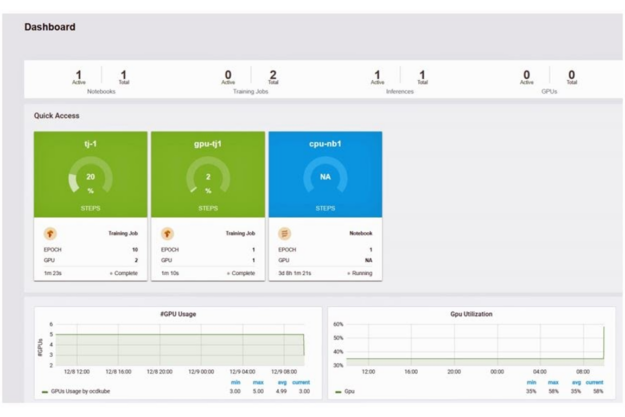
DKube 提供了各種有價值的整合式功能:
- 網路硬體抽象化:將由運算節點、GPU 和儲存體組成的基礎網路化硬體抽象化,並以完全分散、可組合的方式進行存取和管理。妥善處理拓撲複雜性、裝置詳細資訊和利用率,使在內部部署雲端作業,變得與公用雲端一樣簡單(在某些方面更簡單)。新增節點至叢集,即可橫向擴充系統、自動辨識及立即使用節點上的資源。
- 高效率共用:讓應用程式使用者有效率地共用資源,尤其是昂貴的 GPU 資源。GPU 為隨需分配,且可在工作未主動使用時使用。
- 開放平台:以同類最佳開放平台為基礎,提供資料科學家熟悉的元件。DKube 是以容器化標準 Kubernetes 為基礎,並能與 Kubeflow 相容,以支援 Jupyter、TensorFlow、PyTorch,未來將可提供更多支援。它將元件整合至一個統一系統中,引導工作流程,並確保各部分以穩健、可預測的方式進行合作。
- 易用性:其提供開箱即用、UI 驅動的深度學習套件,以使用於模型實驗、訓練和部署。深度學習工作流程與硬體平台協調,排除通常與內部部署有關的運作難題。您可以專注於眼前的難題,而無須擔心管道。僅需要將應用程式安裝在內部部署叢集上,並使用模型,即可在四小時內完成。
結論
採用 NVIDIA 高速網路介面卡的 One Convergence DKube 系統,可以為內部部署平台或裸機深度學習雲端啟用深度學習即服務。若需要更多資訊,請參閱以下資源: