
編者按:本文為「解碼 AI 」系列文章,以深入淺出的方式解密 AI,並向 RTX 電腦的使用者展示新的軟硬體、工具與加速功能。
無論是遊戲與內容創作應用程式,或是軟體開發及生產力工具,有越來越多的應用程式都運用了AI技術,以提升使用者體驗與效率。
這種效率提升技術也延伸至我們的日常事務中,例如網頁瀏覽功能。主打高度隱私的 Brave 瀏覽器,最近推出名為 Leo AI 的智慧 AI 助理功能,除了可提供搜尋結果之外,還能幫使用者摘要內容、回答問題等。
Brave 瀏覽器及其他AI驅動的工具背後所運用的技術,結合了硬體、函式庫與生態系統軟體,並針對AI的獨特需求進行了最佳化。
軟體的重要性為何
NVIDIA GPU 驅動全世界的AI,無論是在資料中心或在本機電腦上執行。NVIDIA GPU內建的 Tensor 核心經專門設計,可透過大規模的平行複雜運算來加速 Leo AI 等AI應用程式——亦即可同時快速處理AI所需的大量運算,而非一次只能處理一項運算。
然而,只有當應用程式能有效使用硬體時,強大的硬體才能充分發揮實力。為了能提供最快速、反應最靈敏的AI體驗,在 GPU 上執行的軟體同樣至關重要。
第一層是AI推論函式庫,它的作用就像是翻譯機,負責接受一般常見的AI任務要求,並將其轉換成可供硬體執行的特定指令。目前主流的推論函式庫包括:NVIDIA TensorRT、Microsoft 的 DirectML,以及 Brave 瀏覽器與 Leo AI 所使用的 llama.cpp。
Llama.cpp 是一個開放原始碼的函式庫與框架。可透過 CUDA(由 NVIDIA 開發的軟體應用程式設計介面,可讓開發人員能夠針對 GeForce RTX 與 NVIDIA RTX GPU 進行最佳化)為數百種模型提供 Tensor 核心加速,包括如 Gemma、Llama 3、Mistral 及 Phi 等熱門的大型語言模型 (LLM)。
除了推論函式庫之外,應用程式通常都會使用本機推論伺服器來簡化整合。推論伺服器可執行下載及配置特定AI模型等作業,如此一來,應用程式就不需要處理這些工作。
Ollama 為奠基於 llama.cpp 而開發的開放原始碼專案,可提供對函式庫功能的存取,並可支援提供本機AI功能的應用程式生態系統。在整個技術堆疊中,NVIDIA 致力於對 Ollama 等工具進行最佳化,使 NVIDIA 硬體在 RTX 平台上能提供速度更快、反應更靈敏的AI體驗。

NVIDIA 對於最佳化的追求涵蓋了整個技術堆疊——無論是硬體與系統軟體,或是推論函式庫及各項工具,旨在使應用程式能夠在 RTX 平台上提供速度更快、反應更靈敏的AI體驗。
本機 vs. 雲端
Brave 瀏覽器與 Leo AI 可於雲端執行,也可以透過 Ollama 在電腦以本機方式執行。
使用本機模型處理推論有很多好處。由於不需要將提示內容傳送給外部伺服器處理,因此能提供高度隱私且隨時可用的使用體驗。此外,在本機執行還能免除雲端存取費用。相較於大多數的託管服務,有了 Ollama,使用者將能利用更廣泛多樣的開源模型,而大多數的託管服務通常只能支援同款 AI 模型的一、兩種變化。
不僅如此,使用者還可與各種不同的專門化模型互動(例如:雙語模型、精簡模型、程式碼生成模型等)。
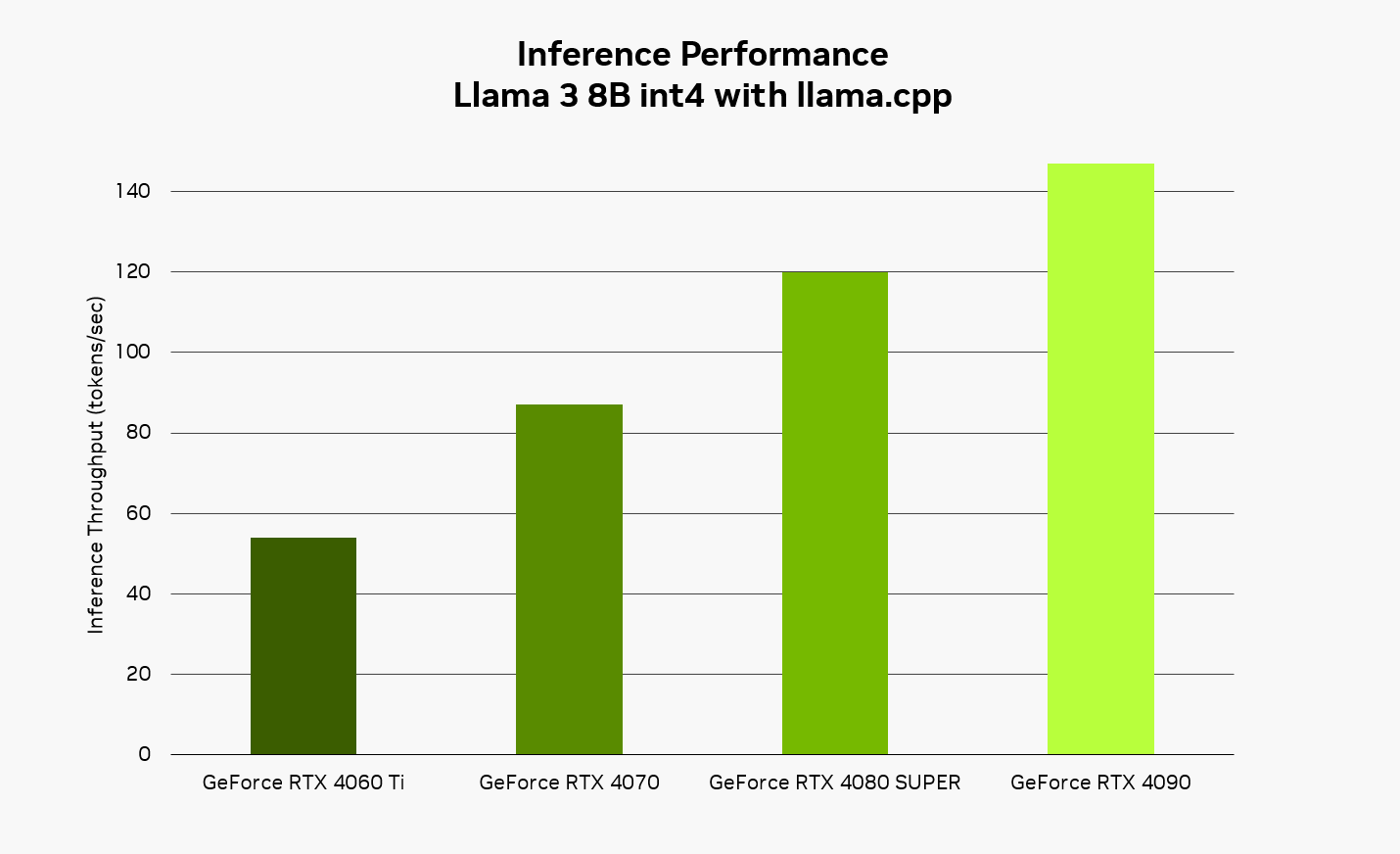
RTX 平台以本機方式執行AI時,可提供快速且反應靈敏的使用體驗。將 Llama 3 8B 模型搭配 llama.cpp 函式庫來使用,使用者預期可獲得每秒高達 149 個 Token 的反應速度,亦即每秒約 110 個英文單字。因此,使用結合了 Leo AI AI應用程式與 Ollama 軟體工具的 Brave 瀏覽器,無論是提問、內容摘要或其他要求,都能獲得更出色的回應速度。
開始使用結合 Leo AI 與 Ollama 兩大利器的 Brave 瀏覽器
Ollama 的安裝非常簡單,只要從該專案的網站下載安裝程式,然後在背景中執行即可。使用者可以透過命令提示字元來下載並安裝各種不同的可支援模型,然後使用命令列來與本機模型互動。
如需有關如何透過 Ollama 新增本機 LLM 支援的簡單說明,請參閱該公司的部落格文章。在設定為指向 Ollama 之後,Leo AI 就會使用本機託管的 LLM 來處理提示與詢問。此外,使用者還可以隨時在雲端與本機模型之間切換。
開發人員可造訪 NVIDIA 開發人員部落格,瞭解有關如何使用 Ollama 與 llama.cpp 的更多資訊。