
MLPerf 作為獨立第三方基準測試,仍然是 AI 效能的權威衡量標準。自 MLPerf 成立以來,NVIDIA 的 AI 平台在訓練和推論兩方面一直保持領先地位,包括今天發布的 MLPerf Inference 3.0 基準測試。
NVIDIA 創辦人暨執行長黃仁勳表示:「三年前當我們推出 A100 的時候,人工智慧領域主要是以電腦視覺為主導。生成式人工智慧已經來臨。這正是為什麼我們打造了 Hopper,針對擁有 Transformer 引擎的GPT進行了優化。今天的 MLPerf 3.0 突顯出,Hopper 的性能是 A100 的 4 倍。下一世代生成式人工智慧需要新的人工智慧基礎架構來訓練大型語言模型,並同時具備極高的能效。客戶正在大規模擴展 Hopper,透過 NVIDIA NVLink 和 InfiniBand 來互通連接數萬個 Hopper GPU 構建人工智慧基礎架構。產業正努力發展安全可靠的生成式人工智慧,Hopper 能夠協助實現這項重要的工作。」
最新 MLPerf 基準測試顯示,NVIDIA 將人工智慧推論從雲端到邊緣的性能和效率提升到新境界。
具體來說,在最新一輪的 MLPerf 測試中,運行於 DGX H100系統中的 NVIDIA H100 Tensor Core GPU 在每個人工智慧推論測試中均實現了最高性能。人工智慧推論是在生產過程中運行神經網絡的工作。歸因於軟體的優化,此 GPU 的效能較去年 9 月份首次亮相時提升了54%。
在醫療保健領域,H100 GPU 自 9 月以來在醫療成像的 MLPerf 基準 3D-UNet (醫學圖像分割)上實現了 31% 的效能增長。
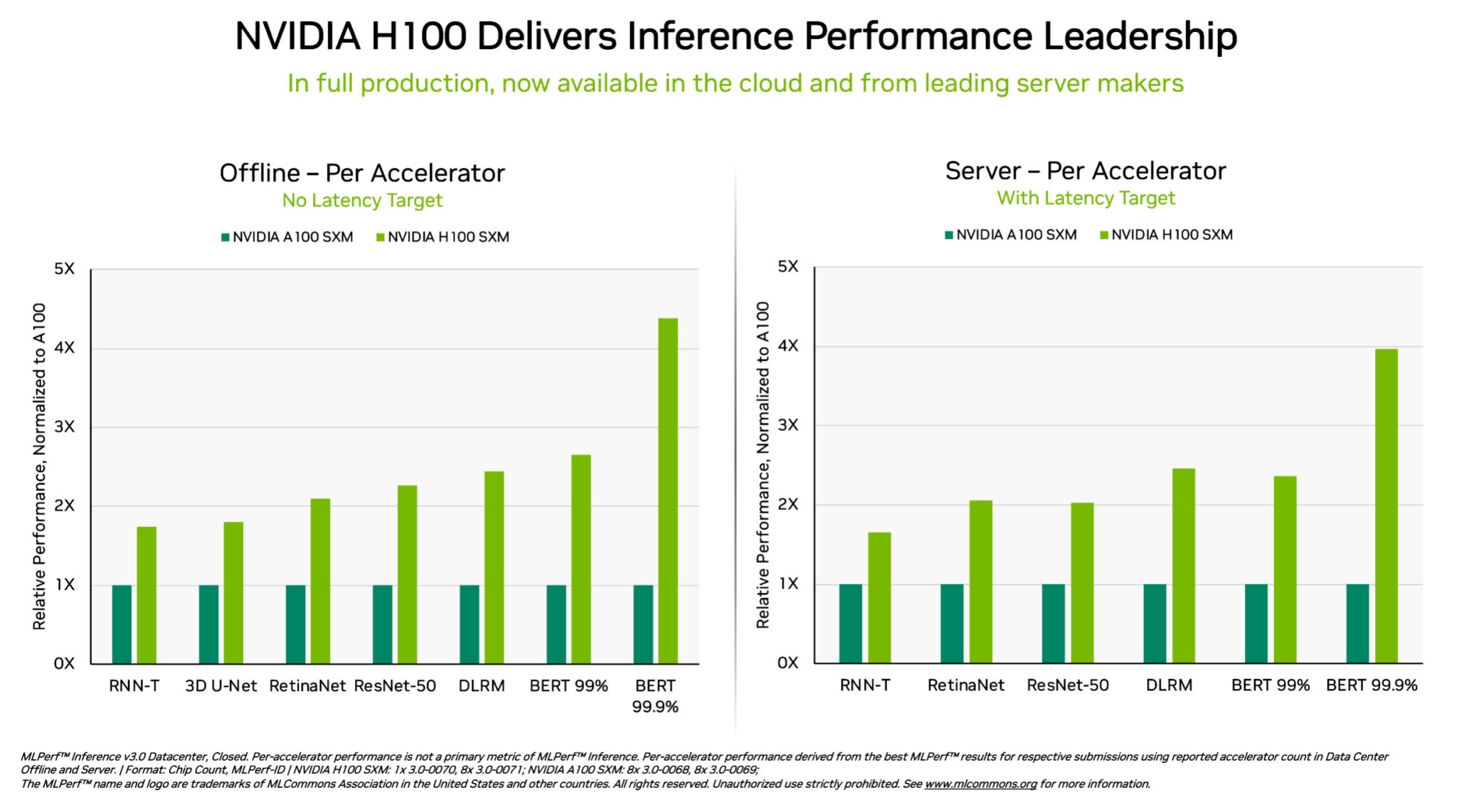
憑藉其 Transformer 引擎,基於 Hopper 架構的 H100 GPU 在 BERT 方面表現優異,BERT 是基於 Transformer 的大型語言模型,是現今生成式人工智慧獲得廣泛應用的關鍵基礎。
生成式人工智慧能讓使用者能夠快速創建文本、圖像、3D 模型等等,這種能力從新創企業到雲服務提供商都在快速採用,以開創新的商業模式並加速現有商業模式的發展。目前數億人正在使用像 ChatGPT 這樣的生成式人工智慧工具(也是一種 Transformer 模型),期望獲得即時回應。
在這個人工智慧的 iPhone 時代,推論的效能至關重要。深度學習現在幾乎被應用到各個領域,從工廠到線上推薦系統,對推理效能有著永無止境的需求。
L4 GPU 速度出眾
NVIDIA L4 Tensor Core GPU 在 MLPerf 測試中首次亮相,其速度是上一代 T4 GPU 的 3 倍以上。 這些加速器採用低調外形封裝,其設計旨在為幾乎所有伺服器提供高吞吐量和低延遲。
L4 GPU 運行所有 MLPerf 工作負載。 由於他們支援關鍵的 FP8 格式,他們在效能要求極高的 BERT 模型上的結果尤其令人驚嘆。
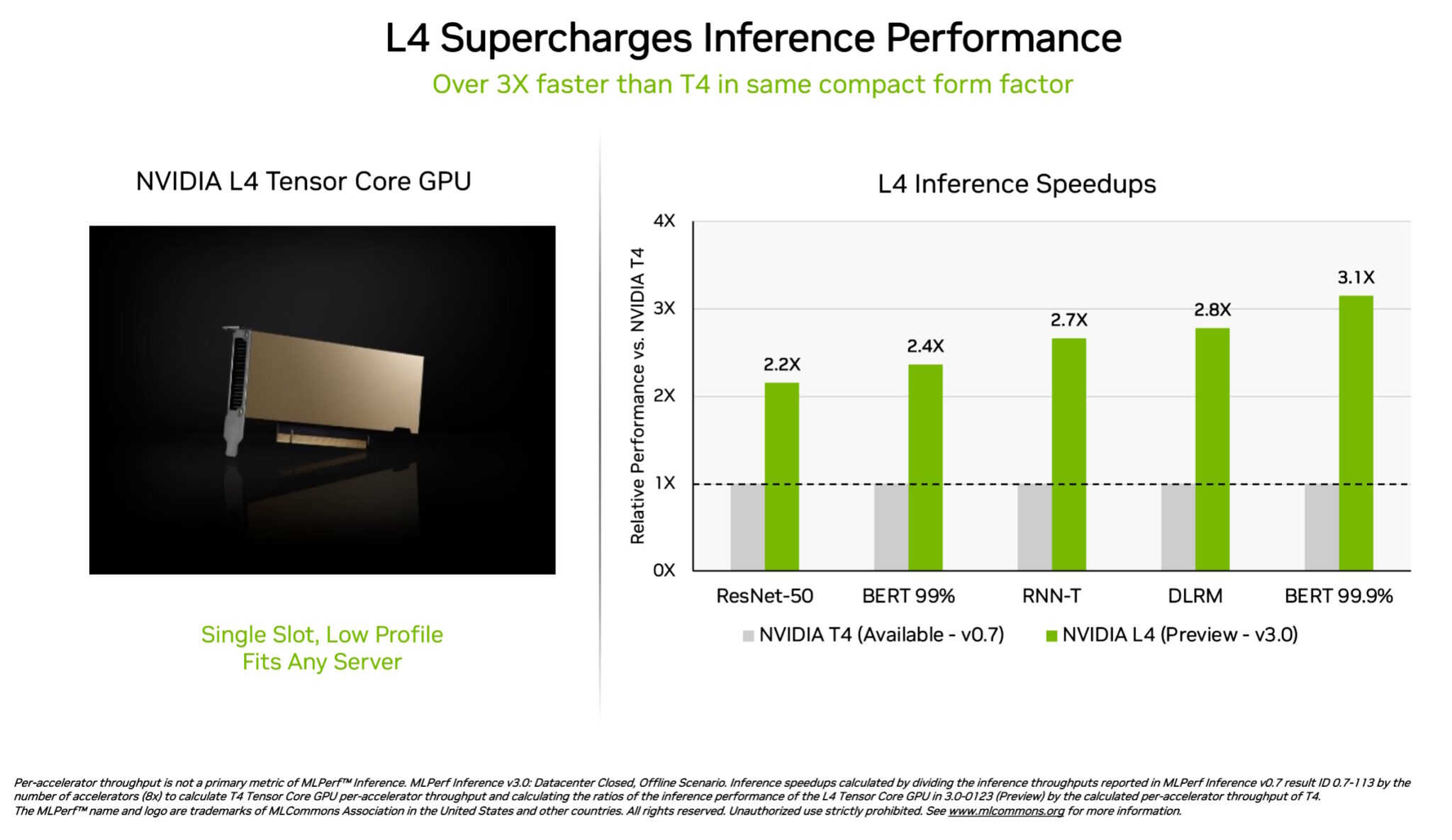
除了出色的人工智慧效能外,L4 GPU 還能提供高達 10 倍更快的圖像解碼速度,高達 3.2 倍更快的影片處理速度以及超過 4 倍更快的圖形和即時渲染效能。
兩周前的 GTC 上即宣布,已可從主要系統製造商和雲端服務供應商獲得這些加速器。L4 GPU 是 NVIDIA 在 GTC 推出的最新人工智慧推理平台產品組合的最新成員。
軟體和網路在系統測試中大放異彩
NVIDIA 的全棧人工智慧平台在新的 MLPerf 測試中展現了其領先地位。所謂的網路劃分基準測試會將資料流傳輸到遠端推論伺服器,這反映了企業使用者在雲端執行 AI 工作,並將資料儲存到企業防火牆後的常見場景。
在 BERT 測試中,遠端 NVIDIA DGX A100 系統的表現達到了其最大本地性能的 96%,速度變慢的部分原因是它們需要等待 CPU 完成某些任務。而在僅由 GPU 處理的 ResNet-50 電腦視覺測試中,它們達到了 100% 的最佳表現。這兩個結果在很大程度上要歸功於 NVIDIA Quantum Infiniband 網絡、NVIDIA ConnectX SmartNIC 和 NVIDIA GPUDirect 等軟體。
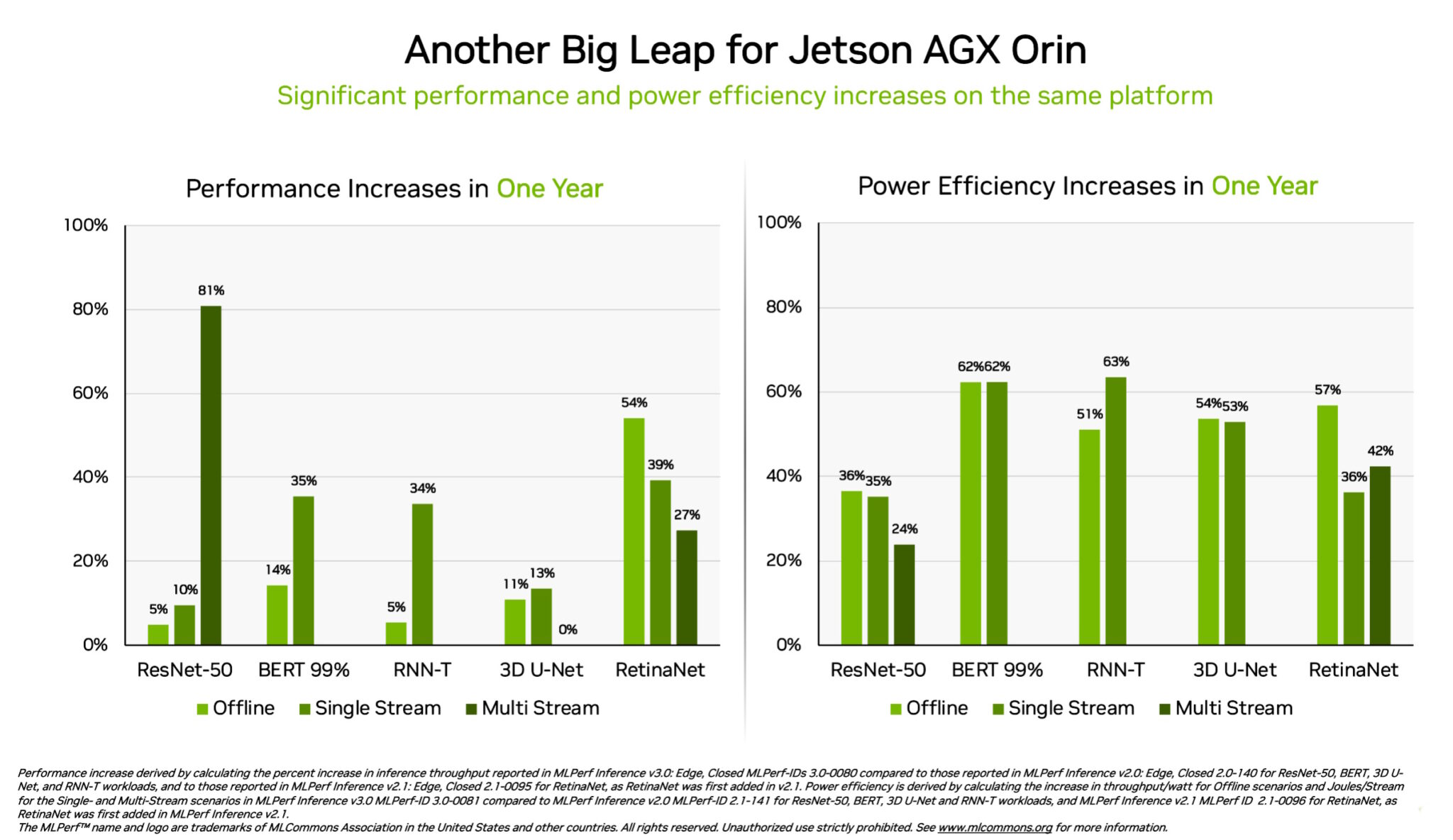
Orin 在邊緣顯示 3.2 倍的效能提升
另外,NVIDIA Jetson AGX Orin 系統模組的能效和性能表現,與前一年的結果相較,分別提高了 63% 和 81%。Jetson AGX Orin 可在有限空間以低功率水平(包括僅由電池供電的系統)提供人工智慧推論。
對於需要更小模塊且功耗更低的應用,Jetson Orin NX 16G 在其首次亮相的基準測試中表現出色。它提供的性能比上一代 Jetson Xavier NX 處理器高出多達 3.2 倍。
廣大的 NVIDIA AI 生態系
從 MLPerf 的測試結果便能看出 NVIDIA AI 獲得業界最廣泛的機器學習生態系支持。
本輪有 10 家公司在基於 NVIDIA 平台上提交了結果。 他們來自 Microsoft Azure 雲端服務和系統製造商,包括像是由華碩(ASUS)、戴爾科技集團(Dell Technologies)、技嘉(GIGABYTE)、新華三集團(New H3C Information Technologies)、聯想(Lenovo)、寧暢信息產業(北京)有限公司(Nettrix)、美超微(Supermicro)和超聚變數字技術有限公司(xFusion)。
它們的測試結果顯示,無論是在雲端或在用戶自己的資料中心伺服器上,使用 NVIDIA AI 獲得絕佳效能。
NVIDIA 的合作夥伴深知,MLPerf 是一項讓客戶用於評估 AI 平台及供應商的寶貴工具,因此才會加入測試。最新一輪的結果顯示,他們如今提供給用戶的出色效能,將隨著 NVIDIA 平台的發展而更將持續強化。
使用者需要多樣化的效能
NVIDIA AI 是唯一能在資料中心和邊緣運算中執行所有 MLPerf 推論工作負載和情境的平台。其多功能的效能與效率,讓使用者成為真正的贏家。
現實應用通常使用許多不同類型的神經網路,這些神經網路通常需要即時提供出答案。例如,AI 應用可能需要理解使用者的口語請求,對圖像進行分類,進行推薦,然後以類人聲的語音傳遞回應。每個步驟都需要不同類型的 AI 模型。MLPerf 基準測試涵蓋這些和其他常見的 AI 工作負載。也就是這些測試何以確保 IT 決策者能獲得既可靠且可以靈活部署的效能。
使用者可依據 MLPerf 結果做出明智的購買決定,因為這些測試是透明和客觀的。 這些基準測試得到了包括 Arm、百度、Facebook AI、Google、哈佛、Intel、微軟、史丹福和多倫多大學在內的廣大團體支持。
可以使用的軟體
NVIDIA AI 平台的軟體層NVIDIA AI Enterprise確保使用者從基礎架構投資中獲得優化的效能,以及在企業資料中心中執行 AI 所需的企業級支援、安全性和可靠性。
於此次測試中使用的各種軟體公開於 MLPerf 資源庫,每個人都能取得這些世界級的成果。我們不斷將最佳化結果放入 NGC (GPU 加速軟體目錄) 的容器中。用來為本次提交的 AI 推論測試結果進行最佳化的 NVIDIA TensorRT 也能在 NGC 中取得。
敬請參閱我們的技術部落格,深入了解促使 NVIDIA MLPerf 效能與效率提升的優化技術。