對話式人工智慧(Conversational AI)是一個使用以語音和自然語言為基礎的介面,結合了人機互動擬人化的技術。以對話式人工智慧為基礎的系統可以透過辨識語音和文字理解命令、在不同的語言之間即時翻譯、理解我們的意圖,並以模仿人類對話的方式回應。
建構對話式人工智慧系統和應用程式是很困難的事。為資料中心部署量身打造單一元件,以滿足企業需求更是難上加難。部署領域專屬的應用程式,通常需要進行多次重新訓練、微調和部署模型,直至滿足要求為止。
為了解決這些問題,本文探討了三個關鍵資產:
- NVIDIA TAO 工具套件促進對話式人工智慧模型的訓練和微調。
- NVIDIA RIVA 簡化產生模型的部署和推論。
- NVIDIA NGC 目錄具有經過預先訓練的對話式人工智慧模型,可以作為進一步微調或部署的起點。
由於這些資產已緊密整合,您可以將為期 80 小時的訓練、微調和部署週期,縮短成 8 小時。本文將著重解釋 TAO 工具套件如何支援各種遷移學習情境,以及如何與 Riva 整合,以部署對話式人工智慧模型和執行即時推論。
對話式人工智慧簡介
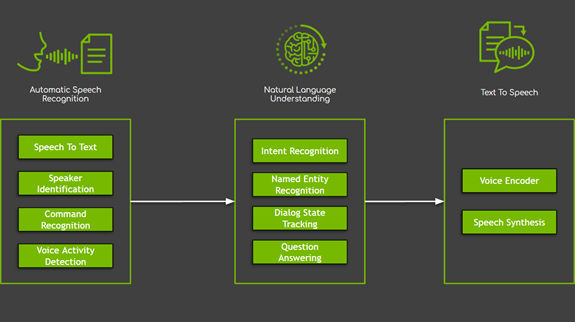
對話式人工智慧系統中有多個元件,大致分成三個主要領域(圖 1):
- 自動語音辨識(automatic speech recognition,ASR)涵蓋所有以使用者之語音做為輸入的任務。在這些任務中,最常使用語音轉文字,負責產生口語和句子的轉錄。
- 自然語言處理(natural language processing,NLP)負責文字處理,包括擷取、理解和處理語意資訊。NLP 涵蓋許多任務,從辨識命名實體等簡單任務,到對話狀態追蹤、問題回答、機器翻譯等複雜任務。
- 文字轉語音(text to speech,TTS)將採取文字形式的系統回應,轉換成可聽到的語音轉錄。
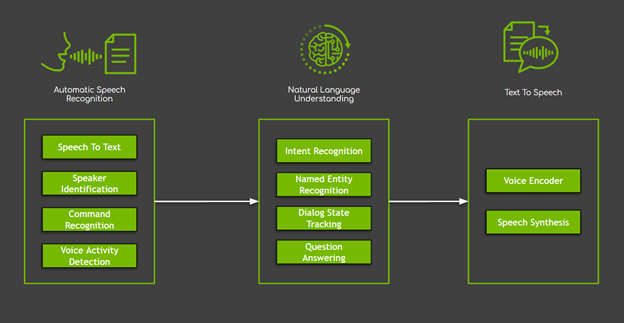
雖然可以使用各種方式執行這些任務,不過深度神經網路促成的新穎方法,已經克服大多數機器學習和規則式解決方案的限制,取得最佳結果。但是,此項進步伴隨的代價為:以神經網路為基礎的模型需要大量資料。
克服缺乏資料最常見的解決方案之一,是採用我們稱之為遷移學習的技術。遷移學習可以將現有之神經網路調整/微調為新的網路,大幅減少需要的領域專屬資料。在大多數情況下,可以大幅縮短微調需要的時間(最常見為縮短 10 倍),以節省時間和資源。最後,由於缺乏高品質、大規模的公共資料集,使此技術對於對話式人工智慧系統特別具有吸引力。
TAO 工具套件 3.0 概述
TAO 工具套件是一款 Python 工具套件,讓您可以使用自己的資料,自訂專用、經過預先訓練的神經模型。TAO 工具套件的目的是在自訂企業資料上,輕鬆重新訓練最先進、經過最佳化且預先訓練的模型。
TAO 工具套件最重要的特色為遵循零編碼範式,並隨附具有預設參數值之現有的 Python 指令碼和組態規格集合,可以立即開始進行訓練和微調。此特色使門檻降低,讓不熟悉模型、不具備深度學習專業知識或初階編碼技能的使用者,也可以訓練新模型及微調預先訓練模型。在推出新的 TAO 工具套件 3.0 版本中,此工具套件進行了重大轉變,開始支援最實用的對話式人工智慧模型。
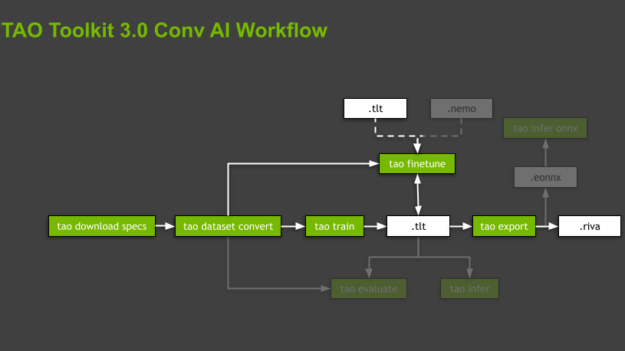
TAO 工具套件透過專用、預先建立的 Docker 容器執行所有運算,將軟體相依性抽象化。指令碼是依據與支援之模型有關的領域和領域專屬任務,採用階層結構。TAO 工具套件針對各個模型,透過強加執行的命令順序做引導,進行從資料準備、訓練和微調模型到匯出模型的推論。這些命令是子任務,而整個組織稱為工作流程(圖 2)。TAO 工具套件為每一個工作流程皆提供一些實用的指令碼。本文將著重於標註處的子任務,並僅會簡要提及其餘的子任務。
使用 TAO 工具套件 3.0 建構對話式人工智慧模型
TAO 工具套件是以 Python 套件的形式提供,可以使用 NVIDIA PyPI (Private Python Package) 中的 pip 進行安裝。進入點為 TAO Toolkit Launcher,並使用 Docker 容器。確定已滿足下列先決條件:
- 依據官方指示安裝 docker-ce。之後,依據安裝後步驟,確定可以在沒有管理員權限(即沒有 sudo)的情況下執行 Docker。
- 依據指示安裝 nvidia-container-toolkit。
- 登入 NGC Docker registry。
$ docker login nvcr.io Authenticating with existing credentials… .. Login Succeeded
建議使用與系統中其他套件分開之新的 Python 虛擬環境,管理 TAO 工具套件安裝。
# Install a virtual environment and activate it. $ virtualenv -p python3 tao-env $ source tao-env/bin/activate
最後,使用 NVIDIA Python Package Index 安裝 TAO 工具套件輪:
# Install the NVIDIA Python Package Index. $ pip install nvidia-pyindex # Install the TAO Toolkit wheel. $ pip install nvidia-tao
現在,已經可以使用 TAO 工具套件。在安裝之後,啟動以 tao 之格式提供標準化命令集合的 TAO 工具套件 Launcher。想要查看支援之不同選項的用法時,請執行 tao –help。若需要更多資訊,請參閱 TAO 工具套件 Launcher 使用指南。
$ tao --help
usage: tao [-h]
{info,list,stop,augment,classification,detectnet_v2,dssd,emotionnet,faster_rcnn,fpenet,gazenet,gesturenet,heartratenet,intent_slot_classification,lprnet,mask_rcnn,punctuation_and_capitalization,question_answering,retinanet,speech_to_text,ssd,text_classification,tlt-converter,token_classification,unet,yolo_v3,yolo_v4}
對映目錄
TAO 工具套件在背景運行 Docker 容器,以執行與不同命令有關的指令碼。此容器是隱藏在 TAO 工具套件 Launcher 後方,所以無須擔心。唯一的要求是預先指定用於儲存資料、規格檔案和結果的個別目錄。同時應裝載 .cache 目錄,以便 TAO 工具套件可以儲存下載的預先訓練檢查點。即可防止指令碼在每一次執行新的訓練或微調時,不斷下載相同的檔案。
這些目錄可以使用命令列引數設置及製作為可以顯示於 Docker 容器上,或在 ~/.tao_mounts.json 檔案中進行配置。若需要更多資訊,請參閱執行啟動器。
以下程式碼範例為配置檔。source 值代表機器中的目錄,destination 則是在 Docker 容器中的對映位置。
# Content of the file ~/. tao_mounts.json:
{
"Mounts":[
{
"source": "~/tao/data",
"destination": "/data"
},
{
"source": "~/tao/specs",
"destination": "/specs"
},
{
"source": "~/tao/results",
"destination": "/results"
},
{
"source": "~/.cache",
"destination": "/root/.cache"
}
],
"DockerOptions":{
"shm_size": "16G",
"ulimits": {
"memlock": -1,
"stack": 67108864
}
}
}
使用遷移學習建構文字分類模型
這是來自於 NLP 領域的範例任務:BERT 模型的文字分類。文字分類是根據內容,為文字分配標籤或類別的一般任務。
下一節將介紹文字分類的兩種應用:
- 情緒分析-類別表示輸入段落的正面或負面情緒。
- 領域分類-類別是不同的對話領域。
您可以透過兩種不同的方式使用 TAO 工具套件 3.0,將遷移學習運用於 NLP 領域。
下載實驗規格檔案
在將 TAO 工具套件 Launcher 初始化之後,即可以開始調用與任一工作流程有關的命令。這些命令調用的指令碼需要大量參數,例如資料集參數、模型參數以及最佳化器和訓練超參數。TAO 工具套件易於使用的部分原因是大多數參數,皆以實驗規格檔案的形式隱藏。
您可以從零開始或從可以透過執行 tao <task> download_specs <args>,針對各個任務或工作流程下載的預設檔案開始編寫規格檔案。甚至可以透過啟動器,個別覆蓋任一或所有的參數。欲深入瞭解每一個指令碼或每一個任務的子任務參數化,請參閱文字分類。
首先,下載文字分類任務的預設規格檔案:
# Here, -r and -o specify the results and the output directories, respectively.
# These directories are from the perspective of the Docker container.
$ tao text_classification download_specs \
-r /results/nlp/text_classification/download_specs/ \
-o /specs/nlp/text_classification/
# Verify that the specs are present on your machine:
$ ls ~/tao/specs/nlp/text_classification/
dataset_convert.yaml export.yaml infer_onnx.yaml train.yaml
evaluate.yaml finetune.yaml infer.yaml
請注意,-o 引數是指示將預設規格檔案下載到哪一個資料夾,-r 引數則是指示指令碼儲存紀錄的位置。確定 -o 引數是指向空的資料夾。
使用預先訓練編碼器訓練情緒分析模型
情緒分析的相關範例,請使用公用的 Stanford Sentiment Treebank(SST-2)資料集。其包含位於由 11,855 個電影評論句子組成之剖析樹狀結構中,215,154 個具有情緒標籤的短語。模型可以在細粒度(5 向)或二元(正/負)分類任務上進行訓練,並根據準確度評估效能。SST-2 格式是由各個分割資料集的 .tsv 檔案組成,亦即訓練、開發和測試資料。每一個項目都具有以空格分隔的句子,後方為定位字元和標籤。
下載資料
下載 SST-2.zip 壓縮檔,並解壓縮至主機上用於儲存資料及可裝載至 TAO 工具套件 Docker 的目錄。在此範例中,是主資料夾中的 /data 資料夾:
# Download the archive. $ wget https://dl.fbaipublicfiles.com/glue/data/SST-2.zip # Unzip the archive. $ unzip SST-2.zip -d ~/tao/data
準備資料
訓練或微調模型的第一步是準備資料。TAO 工具套件可支援此步驟,以專用的資料集轉換指令碼(tao dataset_convert ),將輸入資料預先處理成訓練、微調、評估或推論需要的格式。
在文字分類任務方面,TAO Toolkit dataset_conversion 指令碼可支援兩種公用資料集:SST-2 和 IMDB 資料集。本文使用 SST-2:
$ tao text_classification dataset_convert \
-e /specs/nlp/text_classification/dataset_convert.yaml \
-r /results/nlp/text_classification/dataset_convert \
dataset_name=sst2 \
source_data_dir=/data/SST-2 \
target_data_dir=/data/sst2
請注意,必要的 -e 選項負責提供組態規格檔案給指令碼,-r 選項則是指示指令碼儲存紀錄檔的位置。所有路徑都指向裝載於 Docker 容器中的目錄。
將資料集轉換成正確格式之後,工作流程的下一步是開始訓練(tao train )或微調(tao finetune )。
使用預先訓練編碼器訓練模型
從架構的觀點來看,TAO 工具套件支援的所有 NLP 模型都是屬於編碼器–解碼器模型的一般類別,編碼器是 BERT(Bidirectional Encoder Representations from Transformers,以 Transformers 為基礎的雙向編碼器表示技術)和非迴歸解碼器的變化之一。欲深入瞭解 NLP 模型和 BERT 架構,請參見下文。
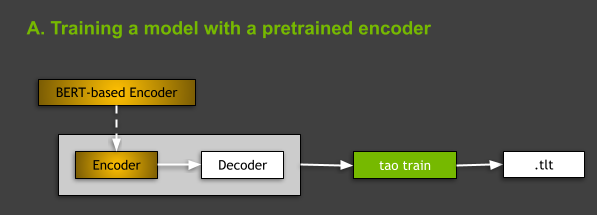
在 TAO 工具套件中訓練 NLP 模型時,有兩種選擇:從零開始訓練,或使用在某些通用 NLP 任務上預先訓練的 BERT 編碼器訓練模型。本文著重於後者,如圖 3 所示。操作方式是在規格檔案中 model: 的 language_model 子區段,指出預先訓練 BERT 編碼器的名稱:
# Content of the ~/tao/specs/nlp/text_classification/train.yaml
...
model:
...
language_model:
pretrained_model_name: bert-base-uncased
...
這是下載文字分類任務之規格檔案時的預設設定。若需要更多資訊,請參閱訓練需要的引數。
想要訓練模型時,必須執行 tao text_classification train 命令:
- -e:微調規範檔案的路徑。
- -r:儲存輸出紀錄和模型之資料夾的路徑。
- -g:將使用的 GPU 數量。
- -k:儲存或載入模型時使用的使用者指定加密金鑰。
- -r:指定儲存結果的目錄。
- 針對規格檔案中之參數進行的任何覆蓋。
若需要更多資訊,請參閱模型訓練。如同您在本文的其他部分所見,所有工作流程中大多數的 TAO 工具套件子任務皆共用這些引數。
$ tao text_classification train \
-e /specs/nlp/text_classification/train.yaml \
-r /results/nlp/text_classification/train \
-g 1 \
-k $KEY \
training_ds.file_path=/data/sst2/train.tsv \
validation_ds.file_path=/data/sst2/dev.tsv \
training_ds.num_samples=500 \
validation_ds.num_samples=500 \
trainer.max_epochs=3
在訓練成功之後,指令碼會建立新的 trained-model.tao 檔案,包含模型配置、訓練後的模型權重及一些其他成品,例如必須一併分配的輸出詞彙。此命令是假設存有 KEY 環境變數:
# Key that is used for encryption of your TAO Toolkit model. $ KEY = ""
微調領域分類模型
TAO 工具套件也可以支援不同的使用案例:微調從 NGC 下載的預先訓練模型。以下各節說明如何微調領域分類器。
從 NGC 下載預先訓練模型
TAO 工具套件在 NGC 上提供了一些資產。從 NGC TAO 工具套件文字分類模型卡下載預先訓練模型。為了方便使用,請下載至 /results 資料夾:
# Download text classification model pretrained on the Misty chatbot domain dataset. $ wget --content-disposition https://api.ngc.nvidia.com/v2/models/nvidia/tao/domainclassification_english_bert/versions/trainable_v1.0/zip -O domainclassification_english_bert_trainable_v1.0.zip # Unzip the archive. $ unzip domainclassification_english_bert_trainable_v1.0.zip # Move the model file to the mounted result folder. $ mv domainclassification_english_bert.tlt ~/tao/results/
微調預先訓練模型
想要在 TAO 工具套件中微調文字分類模型,請使用 tao text_classification finetune 命令。從命令的觀點來看,訓練與微調之間的主要差異為存有微調需要的預先訓練模型 -m 引數,其中 -m 是預先訓練模型檔案的路徑。
在此範例中,必須將資料集轉換成訓練和微調可接受的格式。若需要更多資訊,請參閱資料格式。如同訓練,您也可以手動覆蓋包含微調和驗證資料的檔案路徑,假設包含微調資料的資料夾為 ~/tao/data/my_domain_classification/)。使用上一步下載的 nlp-tc-trained-model.tao 檔案做為輸入。
$ tao text_classification finetune \
-e /specs/nlp/text_classification/finetune.yaml \
-r /results/nlp/text_classification/finetune \
-m /results/nlp-tc-trained-model.tao \
-g 1 \
-k $KEY \
finetuning_ds.file_path=/data/my_domain_classification/train.tsv \
validation_ds.file_path=/data/my_domain_classification/dev.tsv
評估效能
評估子任務之目的是在分割測試中,測量特定模型的效能。執行 tao evaluate :
$ tao text_classification evaluate \
-e /specs/nlp/text_classification/evaluate.yaml \
-r /results/nlp/text_classification/evaluate \
-m /results/nlp/text_classification/train/checkpoints/trained-model.tao \
-g 1 \
-k $KEY \
test_ds.file_path=/data/sst2/test.tsv \
test_ds.batch_size=32
執行推論
除評估子任務外,TAO 工具套件也提供 tao infer 子任務,可用於測試模型行為是否符合預期,並針對提供的原始輸入樣本(speech_to_text 任務的 .wav 檔案、question_answering 任務的原始文字或句子等),探測其輸出。在此範例中,執行推論會顯示出模型是否可以將輸入句子的情緒正確分類:
# For inference:
$ tao text_classification infer \
-e /specs/nlp/text_classification/infer.yaml \
-r /results/nlp/text_classification/infer \
-m /results/nlp/text_classification/train/checkpoints/trained.tao \
-g 1 \
-k $KEY
匯出模型
最後,在確定模型行為正確之後,即可使用 tao export 命令匯出模型,以進行部署:
# For export to Riva:
$ tao text_classification export \
-e /specs/nlp/text_classification/export.yaml \
-r /results/nlp/text_classification/export \
-m /results/nlp/text_classification/train/checkpoints/trained.tao \
-k $KEY
在預設之情況下,會導致在 /results/nlp/text_classification/export 資料夾中建立 exported-model.riva 檔案。匯出子任務也可以將模型匯出為 ONNX(Open Neural Network Exchange,開放神經網路交換)格式(.eonnx)。必須手動設定 export_format=ONNX 參數。在完成之後,同時可以執行 tao infer_onnx 命令,以測試匯出的 ONNX 模型行為。但是,從部署至 Riva 和 Riva 推論的觀點來看,是屬於可選的,目前不需要。
欲深入瞭解所有的 TAO 工作套件命令,請參閱 TAO 工作套件 v3.0 使用指南。本文稍後將會簡要探討其他接受支援的對話式人工智慧任務。
在 Riva 中是將對話式人工智慧模型部署為即時服務
NVIDIA Riva 是使用 GPU 建構多模態對話式人工智慧服務的全面加速應用程式框架。Jarvis 框架包含適用於 ASR、NLP 和 TTS 任務的預先訓練模型、工具,以及最佳化端對端服務。請使用 Riva,將模型部署為針對 GPU 推論最佳化的服務。為了充分利用 GPU 的運算能力,Riva 是使用 NVIDIA Triton 推論伺服器服務神經網路以及使用 NVIDIA TensorRT 執行推論。產生的即時服務,可以在 150 毫秒(ms)內執行,而在純 CPU 平台上則需要 25 秒。
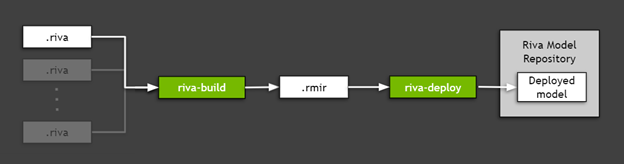
想要部署匯出至 Riva 的 TAO 工作套件模型(在上一節中建立的 .riva 檔案)時,請使用 Riva ServiceMaker,此公用程式結合了所有的必要資產如模型圖、模型權重、模型配置、用於推論的詞彙等,並部署至目標環境中。如圖 5 所示,Riva ServiceMaker 分成兩個主要元件:riva-build 和 riva-deploy。
安裝 Riva 必要元件
首先,設定一些環境變數於之後使用。在此範例中,是使用先前透過 TAO 工具套件訓練和匯出的情緒分析模型,所以必須設定對應的路徑。
# Location of Riva Quick Start. RIVA_QUICK_START=nvidia/riva/riva_quickstart:1.6.0-beta # Location Riva ServiceMaker Docker image. RIVA_SM_CONTAINER=nvcr.io/nvidia/riva/riva-speech:1.6.0-beta-servicemaker # Directory where the .riva model exported from TAO Toolkit is stored. EXP_MODEL_LOC=/results/nlp/text_classification/export # Name of the .riva file. EXP_MODEL_NAME=exported-model.riva # Riva Model Repository folder where the *.rmir and other required assets are stored. RIVA_REPO_DIR=/data/ # In the following, you reuse the $KEY variable used in TAO Toolkit.
在此範例中,是使用 /data 資料夾做為 Riva Model Repository 值,因為 Riva Quick Start 指令碼預設使用此名稱。此資料夾可以儲存模型整體,以及執行推論伺服器需要的所有資產。
其次,安裝 Riva Quick Start 指令碼。最簡單的路徑通往 NGC 登錄。安裝 NGC CLI 及執行以下命令:
# Download Riva Quick Start: $ ngc registry resource download-version $RIVA_QUICK_START
最後,提取 Riva ServiceMaker Docker 映像:
# Get the ServiceMaker Docker container $ docker pull $RIVA_SM_CONTAINER
已準備部分模型。
執行 Riva-build
riva-build 負責將一或多個匯出的模型(.riva 檔案)組合成單一檔案,包含稱為 Riva 模型中間表示(.rmir)的中間格式。此檔案包含整個端對端工作流程的不限部署規格,以及最終部署和推論需要的所有資產。想要在 Riva ServiceMaker Docker 映像內執行 riva-build 命令,請執行以下命令:
# Run the riva-build to generate an .rmir ensemble. $ docker run --gpus all --rm -v $EXP_MODEL_LOC:$EXP_MODEL_LOC -v $RIVA_REPO_DIR:/data --entrypoint="/bin/bash" $RIVA_SM_CONTAINER -- \ riva-build text_classification -f /data/rmir/tc-model.rmir:$KEY \ $EXP_MODEL_LOC/$EXP_MODEL_NAME:$KEY
執行 Riva-deploy
riva-deploy 部署工具是以 Riva 模型中間表示(.rmir),做為輸入及建立指定執行工作流程的整體配置。
在此範例中,是使用 Riva Quick Start 隨附的指令碼執行部署。欲深入瞭解如何手動調用 riva-deploy,請參閱 Riva Deploy。
使用 Quick Start 啟動 Riva 伺服器
在 Riva 中部署模型有兩種選擇。在此範例中,是使用之前從 NGC 提取的 Riva Quick Start 設定本機工作站。從提取建立的資料夾中找出 config.sh 檔案。以下程式碼範例是使用額外的變數 $RIVA_DIR,指示此資料夾。編輯 config.sh 檔案及套用以下變更:
# Enable NLP service only. service_enabled_asr=false ## MAKE CHANGES HERE service_enabled_nlp=true ## MAKE CHANGES HERE service_enabled_tts=false ## MAKE CHANGES HERE # ... # Specify the encryption key to use to deploy models. MODEL_DEPLOY_KEY= ## MAKE CHANGES HERE # ... # Indicate that you want to use .rmir generated previously. use_existing_rmirs=true ## MAKE CHANGES HERE # ... # Set Riva Model Repository path to folder with your model. riva_model_loc=/data ## MAKE CHANGES HERE
這些變更會指示 Quick Start 指令碼自動執行 riva-deploy ,以及執行 Riva 推論伺服器:
# Ensure that you have permissions to execute these scripts. $ cd $RIVA_DIR $ chmod +x ./riva_init.sh && chmod +x ./riva_start.sh # Initialize Riva model repo with your custom RMIR. $ riva_init.sh # Start the Riva server and load your custom model. $ riva_start.sh
建置用戶端應用程式
在 Riva 伺服器與模型開始運作之後,即可傳送推論要求,以查詢伺服器。想要傳送 gRPC 要求,請安裝 Riva 用戶端 Python API 繫結。此 API 是以 pip .whl 的形式,隨附於 Riva Quick Start。
# Install Riva client API bindings. $ cd $RIVA_DIR && pip install riva_api-1.0.0b1-py3-none-any.whl
現在,可以使用繫結,編寫用戶端:
import grpc
import argparse
import os
import riva_api.riva_nlp_pb2 as rnlp
import riva_api.riva_nlp_pb2_grpc as rnlp_srv
class BertTextClassifyClient(object):
def __init__(self, grpc_server, model_name):
# generate the correct model based on precision and whether or not ensemble is used
print("Using model: {}".format(model_name))
self.model_name = model_name
self.channel = grpc.insecure_channel(grpc_server)
self.riva_nlp = rnlp_srv.RivaLanguageUnderstandingStub(self.channel)
self.has_bos_eos = False
# use the text_classification network to return top-1 classes for intents/sequences
def postprocess_labels_server(self, ct_response):
results = []
for i in range(0, len(ct_response.results)):
intent_str = ct_response.results[i].labels[0].class_name
intent_conf = ct_response.results[i].labels[0].score
results.append((intent_str, intent_conf))
return results
# accept a list of strings, return a list of tuples ('intent', scores)
def run(self, input_strings):
if isinstance(input_strings, str):
# user probably passed a single string instead of a list/iterable
input_strings = [input_strings]
# get intent of the query
request = rnlp.TextClassRequest()
request.model.model_name = self.model_name
for q in input_strings:
request.text.append(q)
ct_response = self.riva_nlp.ClassifyText(request)
return self.postprocess_labels_server(ct_response)
def run_text_classify(server, model, query):
print("Client app to test text classification on Riva")
client = BertTextClassifyClient(server, model_name=model)
result = client.run(query)
print(result)
執行用戶端
現在已可以執行用戶端:
# Run the function. run_text_classify(server="localhost:50051", query="How is the weather tomorrow?")
在執行命令後,將會獲得以下結果:
Client app to test text classification on Riva
Using model: riva_text_classification
[('negative', 0.5620560050010681)]
好了!您已經學會如何使用 TAO 工具套件訓練模型、將模型部署至 Riva、執行 Riva 推論伺服器,以及使用 Riva API 編寫簡易用戶端。恭喜!
TAO 工具套件 3.0 支援的其他對話式人工智慧任務和模型
上述的文字分類任務,僅是目前 TAO 工具套件 3.0 版本支援的任務之一。此版本可支援來自兩個對話式人工智慧領域的任務:ASR 和 NLP。此版本略過 TTS 的主要原因,是我們發現難以訓練最先進的 TTS 模型。其需要使用者專業知識和領域知識。他們尚未針對零編碼範式做好準備。
自動語音辨識(ASR)
自動語音辨識(ASR)是從聽覺語音輸入中擷取有意義之資訊的任務。此領域的典型任務,包括向互動式虛擬助理下達語音命令、將音訊轉換成影片和視訊聊天上的字幕,以及將客戶互動轉錄成文字,以封存在客服中心。
目前,TAO 工具套件 3.0 可支援來自 ASR 領域的單一任務,亦即語音轉文字(speech to text,STT)(tao speech_to_text ),並負責轉錄語音。模型的輸出可以用於不同的用途。STT 的輸出可透過附加邏輯,使用於語音命令。
TAO 工具套件使用者可以使用以下三種卷積神經聲學模型模型:
- Jasper 架構可以使整個子區塊融合成單一 GPU 核心,以促進快速 GPU 推論。這對於在推論期間滿足嚴格的 STT 即時要求而言很重要。
- QuartzNet 是類似 Jasper,使用可分離卷積和較大之篩選器的網路。它具備與 Jasper 相當的準確度,而參數較少。
- Citrinet 是 QuartzNet 的一個版本,它使用 1D 時間通道可分離卷積結合子字編碼和擠壓激勵。由此產生的架構顯著減少了非自回歸和序列到序列和傳感器模型之間的差距。
自然語言處理(NLP)
自然語言處理(NLP)是對話式人工智慧應用程式的另一個支柱。此領域中的任務,包括將文字分類、理解語言意圖、辨識關鍵字或實體、增加自動標點符號和大寫,以及根據脈絡回答問題。
TAO 工具套件 3.0 可支援來自 NLP 領域的五種任務或模型:
- 聯合意圖與槽位分類(
tao intent_slot_classification)是對意圖進行分類,並在查詢中偵測該意圖之所有相關槽位/實體的任務。例如,在查詢「聖克拉拉明天早上的天氣如何?」中,應將查詢歸類為「天氣」意圖、將「聖克拉拉」偵測為地點槽位,並將「明天早上」偵測為 date_time 槽位。意圖和槽位名稱通常是取決於任務,且定義為訓練資料中的標籤。這是在任何任務驅動對話式人工智慧助理中執行的基本步驟。 - 聯合標點符號與大寫(
tao punctuation_and_capitalization)針對輸入句子或段落中的每一個單字,模型必須預測單字後的標點符號以及單字是否應大寫。 - 問題回答(
tao question_answering)根據使用自然語言的問題和脈絡,模型必須透過開始和結束位置預測脈絡範圍,以指示問題的答案。 - 文字分類(
tao text_classification)是基本,但是實用的 NLP 任務,可以適應許多應用程式,例如情緒分析、領域分類、語言識別和主題分類。例如在情緒分析中,以下輸入的「效能令人讚嘆!」具有正面情緒,「既不浪漫也不刺激。」則具有負面情緒。 - 權杖分類(
tao token_classification)是在輸出中,針對輸入權杖中之各個實體(例如單字),賦予對應標籤的任務。命名實體辨識(named entity recognition,NER)是權杖分類任務的一種應用,目的是偵測和分類文字中的關鍵資訊/實體。例如,在「Mary 住在聖克拉拉以及在 NVIDIA 工作」的句子中,模型應偵測到「Mary」是人,「聖克拉拉」是地點,「NVIDIA」是公司。
TAO 工具套件支援的所有 NLP 模型,都是以 BERT 做為骨幹編碼器。BERT 使用稱為 Transformer 的注意力架構,學習嵌入脈絡單字,表示單字之間的關係。BERT 的主要創新為使用大型文字語料庫,在兩個非監督式預測任務上訓練模型的預先訓練步驟。在這些非監督式任務上進行訓練,會產生通用語言模型,之後可以快速微調模型,在各種 NLP 任務上實現最先進的效能。
結論
您可能會問:「TAO 工具套件最適合哪些人?」 此工具套件之目前版本針對的主要人士,為已擁有模型基本架構,並嘗試自訂和微調模型,以配合工作流程中之特定使用案例的使用者。TAO 工具套件具備預先定義的規格檔案、詳細的文件、內建加密、與推論導向的 Riva 整合,以及 NGC 上的預先訓練模型集合,目標是將整個開發-部署流程加快 10 倍。我們相信 TAO 工具套件可以成為滿足任何遷移學習和對話式人工智慧需求的一站式解決方案。
若需要更多資訊,請參閱以下資源:
NVIDIA 深度學習機構 (DLI) 提供實作訓練課程,幫助您解決 AI、加速運算、資料科學、繪圖和模擬等領域最具挑戰性的問題。部分課程完成後還能取得 NVIDIA DLI 認證證書,協助自我專業職涯成長。