
在過去幾年,語音互動已成為許多產業產品的功能,如 Amazon Alexa、Google Home、小米 Xiaz、Yandex Alice 等語音平台,以及其他家用語音助理皆提供了易於安裝的智慧家庭技術,讓不瞭解科技的消費者也能輕鬆使用。
語音平台的快速普及和效能提升,引起了人們對智慧家庭的關注。家庭助理可以理解語音命令,無論是回答問題、播放音樂或開燈。為了能自然地與人交談,助理通常結合使用以下 AI 技術:
- 自動語音辨識(automatic speech recognition,ASR)是將口語轉換成文字表示的語音處理元件。
- 自然語言理解(natural language understanding,NLU)是將使用者提出的需求,從自然語言轉譯成正式語意的形式。之後,系統會使用此表示選擇下一個動作,並產生回應。通常要達成 NLU 必須完成各種任務,例如文字正規化、構詞分析、語意分析、排序和命名實體識別。
- 文字轉語音(text-to-speech,TTS)是以文字格式取得回應,並產生語音表示。
市面上有許多開箱即用的家庭助理,同時有開放原始碼專案,例如 Home Assistant。若想要隨手取得最先進的對話式 AI 技術,歡迎試用 DeepPavlov,現在是以 NVIDIA NGC 上的最佳化容器形式提供。
DeepPavlov 的對話系統
開放原始碼 DeepPavlov 函式庫是建構對話系統的絕佳選擇。其具備解決 NLP 相關問題的預先定義元件集合以及建立模組化管道的框架,讓您能流暢地訓練和測試機器學習模型。此函式庫支援 Linux 和 Windows 平台、Python 3.6 以及 Python 3.7。
NLU 的核心 DeepPavlov 技術是以宣告式方法,在設定檔中定義執行模型的順序。讓您可以追蹤相依性以及自動下載缺少的元件。
用於開發以 DeepPavlov 為基礎之語音助理的元件
除了使用代管的開箱即用的解決方案外,開發語音助理將會伴隨超出 NLU 和對話管理的各種挑戰。若想要建立完整的系統,即必須將自動語音辨識和文字轉語音合成元件加入至 NLU 核心。
語音辨識與合成
DeepPavlov ASR 和 TTS 元件是以 NVIDIA NeMo (v0.10.0) 工具套件中的預建模組為基礎。我們在 DeepPavlov 的最新版本中,建置了三個語音處理工作流程:
- asr 使用預先訓練的模型 QuartzNet15x5En 定義英語語音辨識的最小工作流程。其可將語音資料擷取為音訊檔案路徑的批次或二進位 I/O 物件的批次,並回傳轉錄文字的批次。
- tts 使用預先訓練的模型 Tacotron2 和 WaveGlow 定義英語語音合成的最小工作流程。Tacotron2 是從文字產生聲譜圖,WaveGlow 則是從聲譜圖產生音訊。tts 工作流程可取得兩個批次做為輸入、文字批次和路徑批次,以儲存音訊檔案。
- asr_tts 定義了轉錄語音及進行複誦的完整語音轉語音循環。此工作流程與 asr 和 tts不同,可以執行 REST 網頁服務,以接收來自另一個程序的語音,並回傳語音做為回應。asr_tts 是使用與 asr 和 tts 相同的預先訓練的模型。
安裝
您可以執行以下命令,從 asr 和 tts 配置安裝 DeepPavlov 與預先訓練的模型:
python -m deeppavlov install asr_tts
python -m deeppavlov download asr_tts
若要測試工作流程,需要採用 WAV 檔案格式的單聲道 16 Khz 錄音。您可以自行錄製,或從開放原始碼 LibriSpeech 資料集下載語音範例。
ASR 工作流程
如果已經有單聲道 WAV 檔案,則四行程式碼即足以轉錄音訊:
model = build_model(configs.nemo.asr)
text_batch = model([‘/path/to/your/wav/file’])
print(text_batch[0])
若要記錄即時語音,請使用 sounddevice 函式庫。確認已安裝所有必要的套件,並嘗試使用以下指令碼錄製語音,以及透過 asr 工作流程進行轉錄:
from io import BytesIO
import sounddevice as sd
from scipy.io.wavfile import write
from deeppavlov import build_model, configs
sr = 16000
duration = 3
print(‘Recording…’)
myrecording = sd.rec(duration*sr, samplerate=sr, channels=1)
sd.wait()
print(‘done’)
out = BytesIO()
write(out, sr, myrecording)
model = build_model(configs.nemo.asr)
text_batch = model([out])
print(text_batch[0])
若要改進語音辨識模型,請使用 NeMo 為您的資料集進行訓練或微調。如果有變更已訓練模型的架構,則應修改模組的配置檔。將該檔案的路徑傳遞至 nemo_asr 元件,做為 nemo_params_path 引數的值。
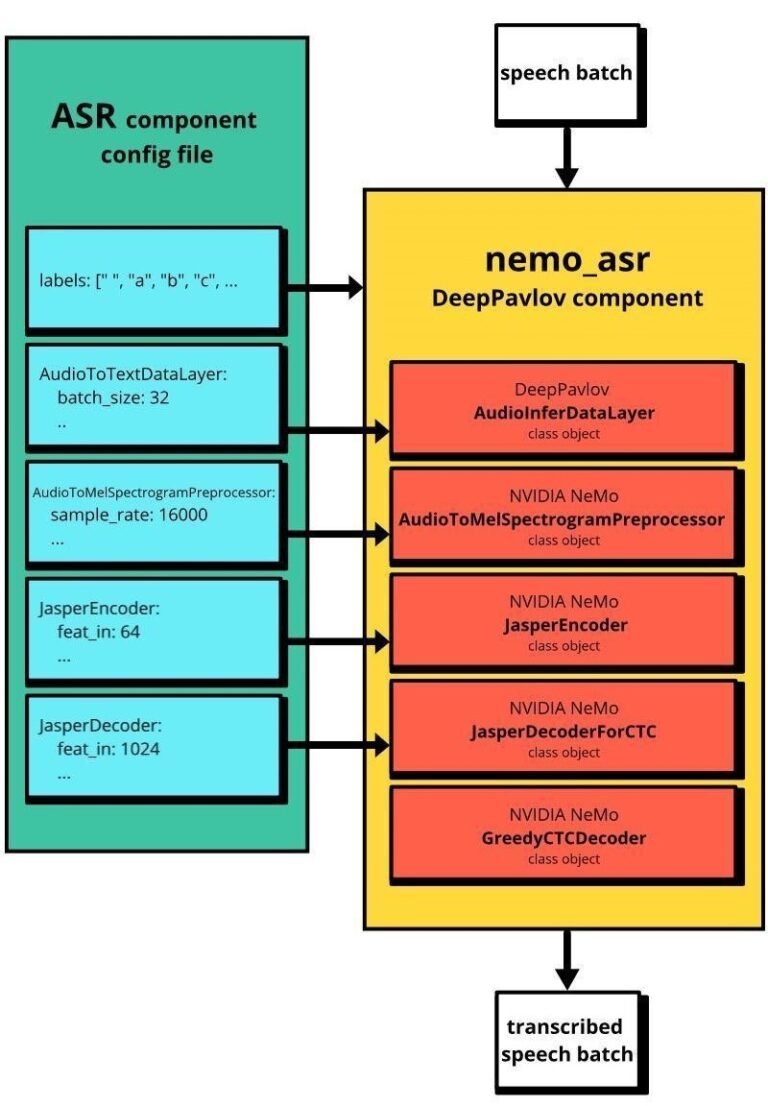
欲深入瞭解構成 nemo_asr 元件的模組,請參閱語音辨識。圖 1 為 NeMo ASR 與 DeepPavlov nemo_asr 工作流程之間的關係。
TTS
僅需要三行程式碼即能透過 tts 配置檔使用 tts 工作流程,從文字產生語音:
from deeppavlov import build_model, configs
model = build_model(configs.nemo.tts)
filepath_batch = model([‘Hello world’], [‘/path/to/save/the/file.wav’])
print(f’Generated speech has successfully saved at {filepath_batch[0]}’)
如果從配置檔中刪除 filepath 引數,則模型會回傳包含產生語音的 Bytes I/O 物件,而非儲存檔案的路徑。如同之前的 nemo_asr 範例,您可以使用 NVIDIA NeMo 訓練 nemo_tts 元件的檢查點。
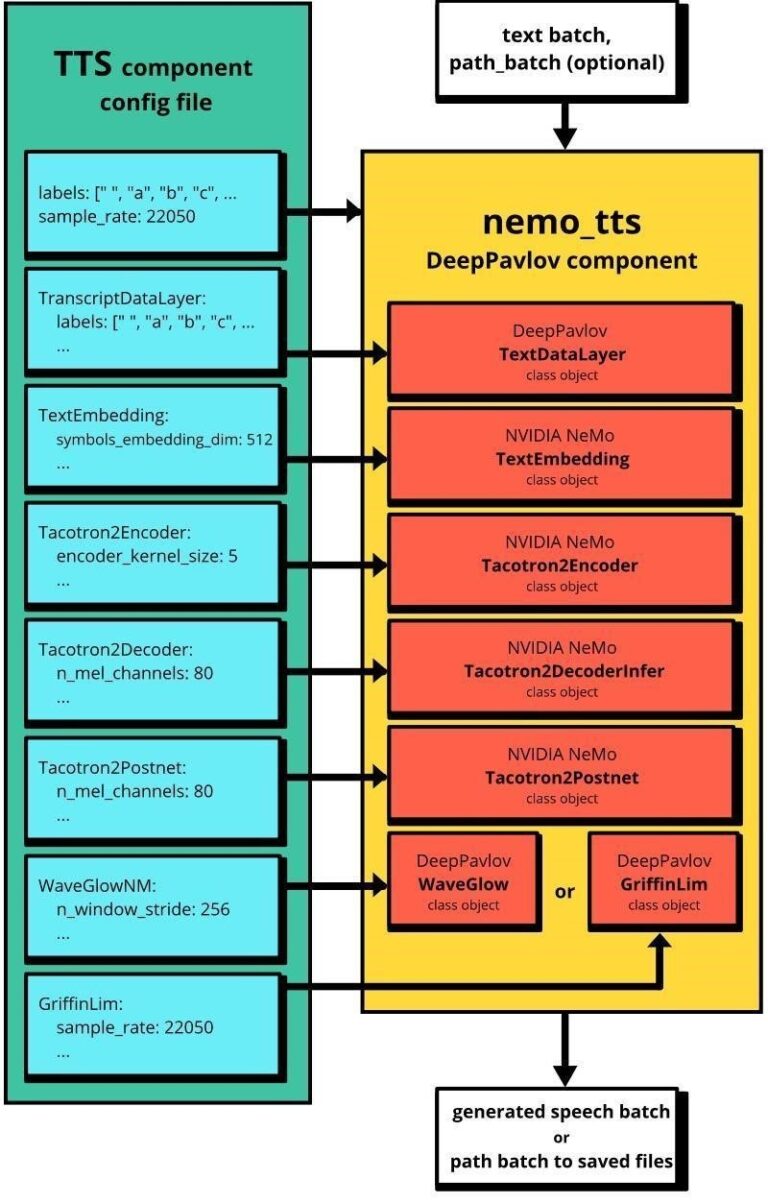
nemo_tts 產生音訊的預設持續時間為 11.6 秒。若需要更長的持續時間,請從 nemo_tts 配置檔之 Tacotron2Decoder 部分提高 max_decoder_steps 參數的值。圖 2 顯示 NeMo 與 nemo_tts 工作流程之間的關係。
GPU vs. CPU
GPU 基礎架構對語音處理應用而言非常重要。我們在 Xeon i7 CPU 和 NVIDIA V100 GPU 上,針對 DeepPavlov asr/tts 工作流程進行基準測試。當語音轉換成文字之後,語音長度會在 37 到 367 個字元之間,CPU 的推論時間從 70 ms 到 290 ms 不等,而 GPU 的推論時間幾乎會持續維持在 80ms。在 TTS 可發現更明顯的差異。在 Xeon i7 CPU 上,從句子產生語音訊號的時間比 NVIDIA V100 GPU 長 20 倍以上。
使用 REST API 進行語音轉語音
我們示範了如何在本機電腦上使用 DeepPavlov 產生和轉錄語音。但是,如何建立類似量產的用戶端-伺服器架構呢?asr_tts 工作流程可以透過執行服務,使用 64 個 ASCII 字元,針對音訊檔案中的二進位資料進行編碼,以解決此任務。圖 3 顯示 asr_tts 工作流程的用戶端-伺服器解決方案。
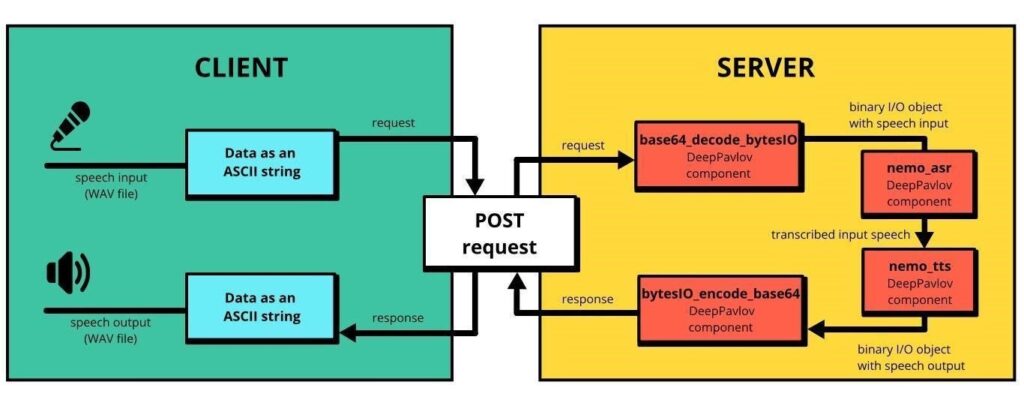
使用 ASCII 字元針對音訊檔案進行編碼,可將音訊資料嵌入至 DeepPavlov 工作流程,同時享有保留文本資料的靈活性。在實際應用時,您可以輕鬆變更針對音訊進行編碼的方式。
DeepPavlov 預設支援以服務形式執行工作流程。若要以 asr_tts 工作流程啟動伺服器,請使用以下命令:
伺服器是在連接埠 5000 上執行。若要使用其他連接埠,請在命令提示字元的尾端加上 -p <port_number_to_use>。
在收到「Application startup complete」的訊息之後,即可使用以下程式碼範例,將需要辨識的語音傳送至伺服器,然後進行複誦。請將 127.0.0.1 改成您的伺服器位址。
from base64 import encodebytes, decodebytes
from requests import post
with open(‘/path/to/wav/file/with/speech’, ‘rb’) as fin:
input_speech = fin.read()
input_ascii = encodebytes(input_speech).decode(‘ascii’)
resp = post(‘https://127.0.0.1:5000/model’, json={“speech_in_encoded”: [input_ascii]})
text, generated_speech_ascii = resp.json()[0]
generated_speech = decodebytes(generated_speech_ascii.encode())
with open(‘/path/where/to/save/generated/wav/file’, ‘wb’) as fout:
fout.write(generated_speech)
print(f’Speech transcriptions is: {text}’)
若要增加一些 NLU 功能,請在 asr_tts 配置檔中,將目標 DeepPavlov 模型插入 nemo_asr 與 nemo_tts 元件之間。
建構簡單的語音助理:智慧照明!

現在,建立一個最簡單的應用程式,使用使用者的命令開啟和關閉裝置,例如燈泡。此範例僅示範與語音辨識和語音產生整合的一般方法,未建置特定的開關功能。同樣地,此範例具有用戶端-伺服器架構。
伺服器
首先,建立包含 nemo_tts 元件的新 DeepPavlov 配置檔,名稱為 my_tts.json。以下程式碼範例為回傳 Bytes I/O 物件,而非寫入至檔案:
“chainer”: { “in”: [“text”], “pipe”: [ { “class_name”: “nemo_tts”, “nemo_params_path”: “{TTS_PATH}/tacotron2_waveglow.yaml”, “load_path”: “{TTS_PATH}”, “in”: [“text”], “out”: [“saved_path”] } ], “out”: [“saved_path”] }, “metadata”: { “variables”: { “NEMO_PATH”: “~/.deeppavlov/models/nemo”, “TTS_PATH”: “{NEMO_PATH}/tacotron2_waveglow” }, “requirements”: [ “{DEEPPAVLOV_PATH}/requirements/pytorch.txt”, “{DEEPPAVLOV_PATH}/requirements/nemo-asr.txt”, “{DEEPPAVLOV_PATH}/requirements/nemo-tts.txt” ], “download”: [ { “url”: “https://files.deeppavlov.ai/deeppavlov_data/nemo/tacotron2_waveglow.tar.gz”, “subdir”: “{NEMO_PATH}” } ] }}
此配置與 asr 的差別僅在於缺少 filepath 引數。
安裝 FastAPI 接收上傳檔案需要的 python-multipart 模組:
最後,執行以下指令碼,以啟動伺服器:
from io import BytesIO
import uvicorn
from deeppavlov import build_model, configs
from fastapi import FastAPI, File
from starlette.responses import StreamingResponseapp = FastAPI(__file__)
asr = build_model(configs.nemo.asr)
tts = build_model(‘my_tts.json’)
@app.post(“/light”)
def interact(file: bytes = File(…)):
input_text = asr([BytesIO(file)])[0]
response_text = “Can’t understand your command.Please repeat.”
if input_text == ‘turn on’:
response_text = ‘Turned on the light’
elif input_text == ‘turn off’:
response_text = ‘Turned off the light’
speech_response = tts([response_text])[0]
return StreamingResponse(speech_response, media_type=’audio/wav’)
uvicorn.run(app)
除變更 response_text 變數的值之外,您也可以新增特定的命令建置,以控制裝置。DeepPavlov 具有各種元件,您可以輕鬆將元件新增至工作流程。例如,您可以新增轉錄語音的自動拼字校正或意圖分類。
用戶端
以下指令碼會記錄來自麥克風的命令,並將命令傳送至伺服器,然後播放伺服器回應:
import sounddevice as sd
from requests import post
from scipy.io.wavfile import write, readsr = 16000
duration = 3print(‘Recording command…’)
myrecording = sd.rec(duration*sr, samplerate=sr, channels=1)
sd.wait()
print(‘done’)command = BytesIO()
write(command, sr, myrecording)
response = post(‘https://127.0.0.1:8000/light’, files={‘file’: command})
samplerate, data = read(BytesIO(response.content))sd.play(data, samplerate)
sd.wait()
為了簡化系統設定,我們已經預先錄製開啟和關閉兩個命令(turn on、turn off)。您可以在沒有麥克風的情況下執行以下指令碼,以傳送命令:
from io import BytesIO
import sounddevice as sd
from requests import post
from scipy.io.wavfile import read
with open(‘turn_on.wav’, ‘rb’) as command:
response = post(‘https://127.0.0.1:8000/light’, files={‘file’: command})
samplerate, data = read(BytesIO(response.content))
sd.play(data, samplerate)
sd.wait()
結論
在本文中,我們示範了如何在本機電腦上使用 DeepPavlov 語音工具,以及如何建立 asr 和 tts 工作流程。我們同時示範如何建置用戶端-伺服器架構及透過語音命令控制裝置。
希望對您有幫助,且相信您已經等不及想要試用 DeepPavlov 建構語音 AI 助理。請在官方 DeepPavlov 部落格中進一步瞭解我們。歡迎使用我們的互動式 Text QA 示範測試模型。DeepPavlov 以 NVIDIA NGC 上的容器形式提供。請別忘了專用論壇,歡迎您在提出任何與框架和模型有關的問題。請持續關注!