編者按:本文為「解碼 AI 」系列文章,以深入淺出的方式解密 AI,並向 RTX 電腦的使用者展示新的軟硬體、工具與加速功能。
大型語言模型 (LLM) 正在改變生產力的面貌。這類模型可草擬文件、整理網頁摘要,而且經過大量資料訓練,幾乎任何主題的問題都能正確回答。LLM 是許多生成式 AI 新興使用案例的核心,包括數位助理、對話型虛擬分身和客服專員。
可在 PC 或工作站本機執行的最新款 LLM 很多。支援在本機執行之所以實用的理由很多:使用者可讓對話與內容維持私密、不連接網際網路就能使用 AI,或者純粹是在系統使用強大的 NVIDIA GeForce RTX GPU。其他模型則因為大小和複雜度之故,無法搭配本機 GPU 的視訊記憶體 (VRAM) 使用,需要大型資料中心的硬體。
然而,運用所謂的 GPU 卸載技術,便可以本機方式,在 RTX 支援的 PC 加速資料中心級模型的部分提示功能。這樣一來,使用者便可擺脫 GPU 記憶體限制,享受 GPU 加速技術的效益。
大小與品質相較於效能
模型大小與回應品質以及效能之間,魚與熊掌無法兼得。一般來說,模型越大,提供的回應品質越高,但執行速度則越慢。模型越小則效能越高,但品質越低。
這種取捨未必一向直截了當。在某些情況下,效能可能比品質重要。部分使用者在內容生成這類情況可能首重準確度,因為這類工作可在背景執行。對話助理則必須快速,並提供準確的回應。
專為在資料中心執行而設計的 LLM 中,準確度最高的 LLM,大小達數十 GB,可能不適合在 GPU 記憶體使用。因此,應用程式一向無法利用 GPU 加速技術。然而,GPU 卸載讓使用者可以在 GPU 使用部分的 LLM,以及在 CPU 使用部分的 LLM,讓使用者擺脫模型大小限制,充分利用 GPU 加速技術。
利用 GPU 卸載與 LM Studio 將 AI 加速最佳化
使用者使用 LM Studio 這款應用程式時,可在桌上型電腦或筆記型電腦下載及託管 LLM,而且介面簡單易用,因此可廣泛自訂這些模型的運作方式。LM Studio 以 llama.cpp 為建置基礎,因此已針對搭配 GeForce RTX 與 NVIDIA RTX GPU 使用全面最佳化。
有了 LM Studio 與 GPU 卸載技術,即使模型無法完全載入 VRAM,使用者也能利用 GPU 加速技術,大幅提升本機託管 LLM 的效能。
LM Studio 利用 GPU 卸載,將模型分成更小的區塊,或是代表模型架構分層的「子圖」。子圖並非永久固定於 GPU,而是視需要載入及卸載。使用者可利用 LM Studio 的 GPU 卸載滑桿,決定這些分層由 GPU 處理的數量。
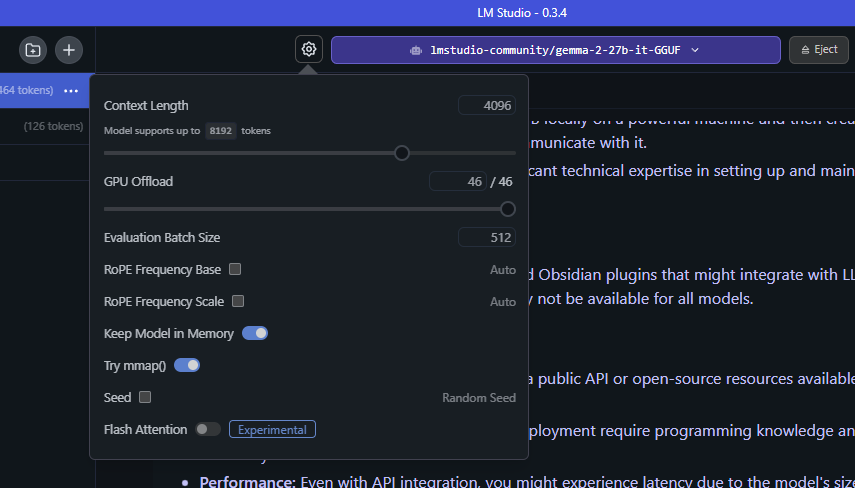
舉例而言,請試想這種 GPU 卸載技術搭配 Gemma 2 27B 這類大型模型使用的情況。「27B」是指模型的參數數量,就執行模型需要多少記憶體提供估計值。4-bit 量化這項技術,可在不大幅降低準確度的情況縮小 LLM,每個參數耗用半個位元組的記憶體。也就是說,模型應該需要耗用大約 135 億個位元組或 13.5 GB ,外加一般最少 1-5 GB 的開銷。
若純粹使用 GPU 加速這個模型,GeForce RTX 4090 桌上型 GPU 需要有 19 GB VRAM。利用 GPU 卸載技術,模型可在低階 GPU 執行,同時享有加速技術的效益。
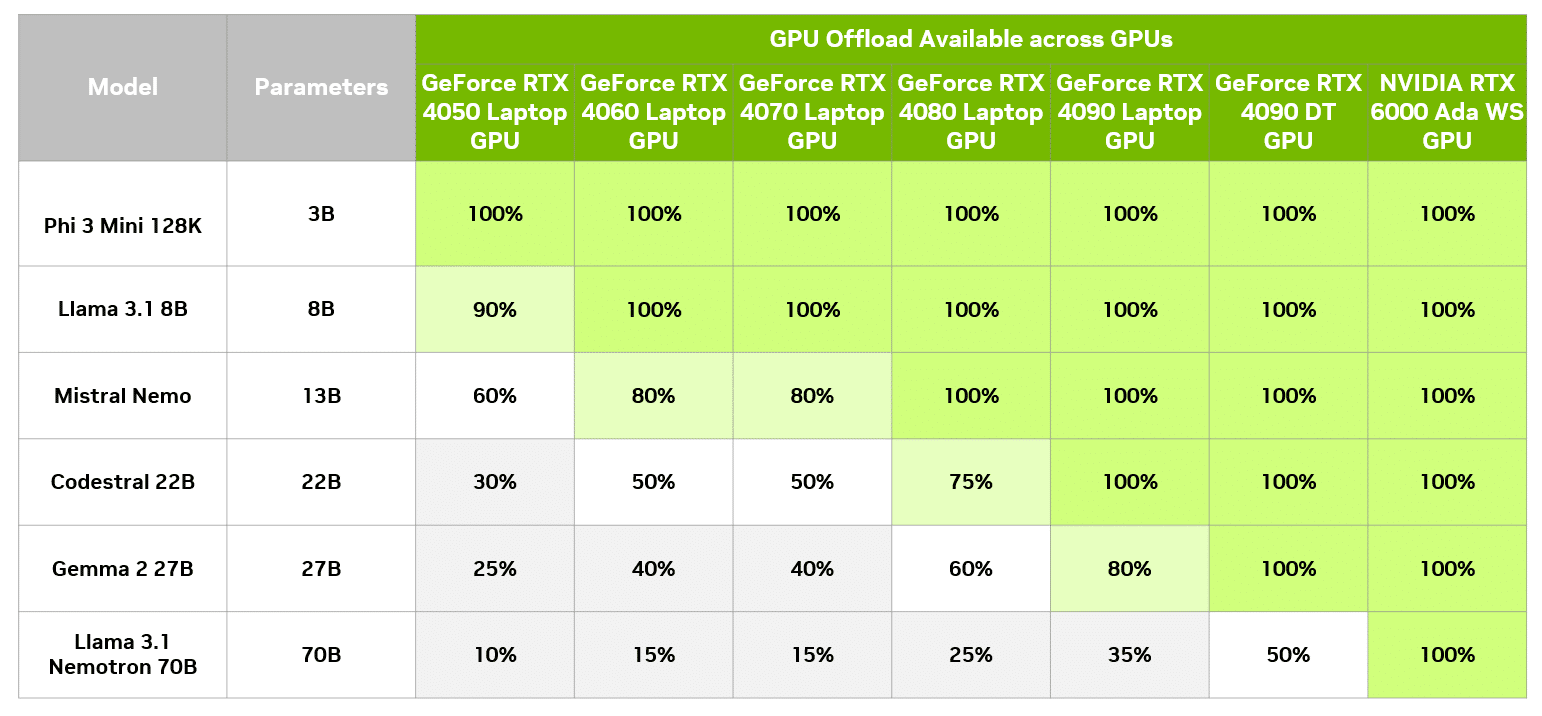
在 LM Studio,可以對照單純使用 CPU,評估不同 GPU 卸載程度對效能的影響。下表顯示,在 GeForce RTX 4090 桌上型 GPU 搭配不同卸載程度執行相同查詢的結果。

使用這個特定模型時,即使是使用 8GB GPU 的使用者,相較於單單使用 CPU 執行,速度也能顯著提升。當然,8GB GPU 絕對能執行與 GPU 記憶體完全相符的小型模型,並獲得完整 GPU 加速的效益。
實現最佳平衡
LM Studio 的 GPU 卸載功能是強大工具,可讓為資料中心設計的 LLM 發揮得淋漓盡致,例如 RTX AI PC 本機上的 Gemma-2-27B。這項功能讓採用 GeForce RTX 與 NVIDIA RTX GPU 的整個 PC 系列,都能使用更大也更複雜的模型。
下載 LM Studio,在大型模型試用 GPU 卸載,或是在 RTX AI PC 與工作站測試本機執行的各種 RTX 加速 LLM。
生成式AI正在改變遊戲、視訊會議和各種互動式體驗的生態。立即訂閲解碼AI電子報,掌握最新消息和未來趨勢。