推薦系統是網際網路的經濟引擎,現在也獲得全新的加成動能:NVIDIA Grace Hopper 超級晶片
推薦系統每天都會為數十億人提供上兆的搜尋結果、廣告、產品、音樂和新聞報導。推薦系統能在網際網路世界的一團混亂中,找到使用者想要的寶貴資訊,是我們這個時代最重要的人工智慧模型之一。
這些機器學習流程會執行數 TB 的資料。推薦系統使用越多資料,結果越準確,投資報酬率就越高。
為了處理海嘯般的資料量,企業已採用加速運算技術,為客戶提供個人化服務。Grace Hopper 則將這些技術提升至全新境界。
GPU 可將互動率提高 16%
Pinterest 這家共享影像社群媒體公司在採用 NVIDIA GPU 後,將推薦模型擴大 100 倍,並讓他們 4 億多名使用者的互動率提高 16%。
該公司的一位軟體工程師在最近的一篇部落格文章說:「通常,只要有 2% 的提升就很令人開心了,而 16% 的提升只不過是個開始。我們得到額外的收益,這也帶來更多機會。」
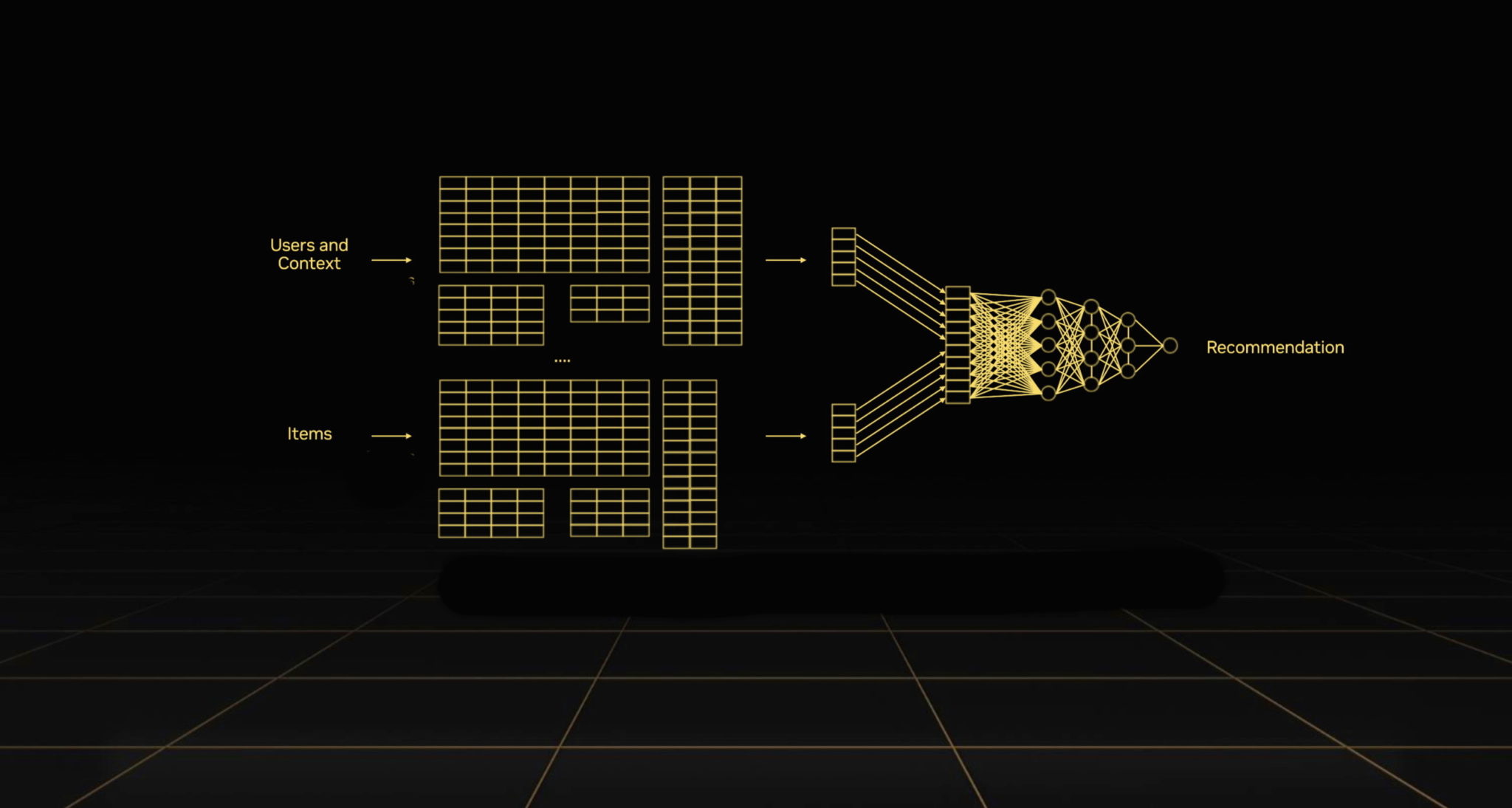
新一代 NVIDIA 人工智慧平台有望為使用超大型推薦模型處理大量資料集的公司,帶來更大收益。
由於資料是人工智慧的動力,Grace Hopper 的設計目的是透過推薦系統傳輸更多資料,並超越地球上其他任何處理器。
NVLink 加速 Grace Hopper
Grace Hopper 之所以能達到此成果,是因為這是將兩個晶片融入一個單元的超級晶片,並共用超快速的晶片對晶片互連技術。設計上是一個採用 Arm 架構的 NVIDIA Grace CPU 與一個 Hopper GPU 透過 NVIDIA NVLink-C2C 互連。
此外,NVLink 也將許多超級晶片連結到超級系統,這是專為執行 TB 級推薦系統而打造的運算叢集。
NVLink 以每秒高達 900 GB 的速度傳輸資料,比起即將推出的最頂尖系統使用的 PCIe 第 5 代互連技術,頻寬提高 7 倍。
這表示 Grace Hopper 可向推薦系統提供的嵌入內容 (包含背景資訊的資料表格),比系統為使用者個人化結果時所需要的資料多 7 倍。
更多的記憶體、更高的效率
Grace CPU 採用 LPDDR5X,此記憶體在頻寬、能源效率和推薦系統及其他嚴苛工作負載成本之間取得最佳平衡。此記憶體的頻寬增加 50%,同時比起傳統的 DDR5 記憶體子系統,每 GB 所需消耗的功率只要八分之一。
叢集中的任何 Hopper GPU 都可以透過 NVLink 存取 Grace 的記憶體。這是 Grace Hopper 的功能,可提供史上最大的 GPU 記憶體池。
此外,NVLink-C2C 傳輸每位元資料時,只需消耗 1.3 皮焦耳,能源效率是第 5 代 PCIe 的 5 倍以上。
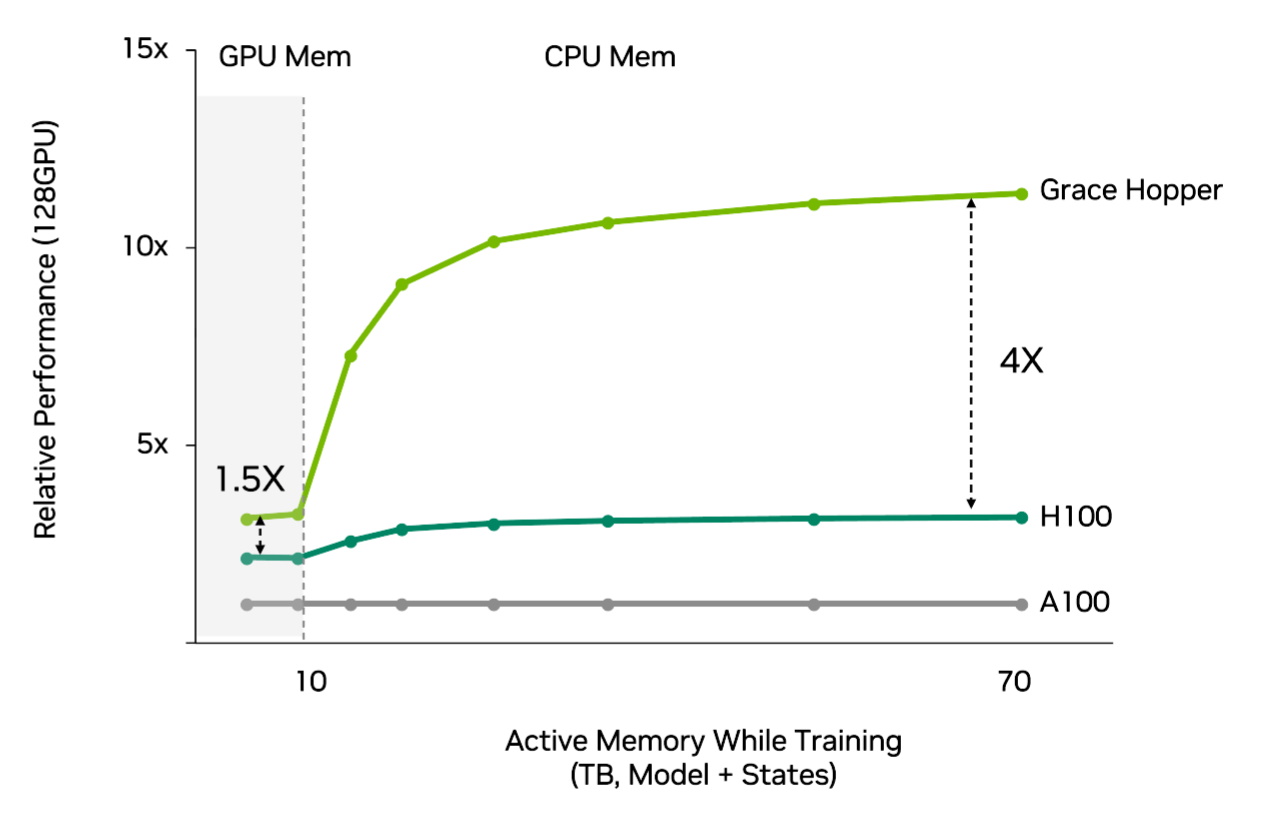
整體結果是,與使用傳統 CPU 的 Hopper 相比,推薦系統使用 Grace Hopper 時,效能提升 4 倍,效率也更高 (請見下方圖表)。
您需要的所有軟體
Grace Hopper 超級晶片執行當今全球一些最大推薦系統中使用的完整 NVIDIA 人工智慧軟體堆疊。
NVIDIA Merlin 是推薦系統的強大動力來源,集結一系列打造人工智慧系統的模型、方法和函式庫,可改善預測成果和增加點擊率。
NVIDIA Merlin HugeCTR 推薦系統框架在 NVIDIA 集合通訊函式庫協助下,可協助使用者跨分散式 GPU 叢集,處理大量資料集。
在此技術部落格文章深入瞭解 Grace Hopper 與 NVLink。並觀看這場 GTC 演講,深入瞭解如何打造推薦系統。