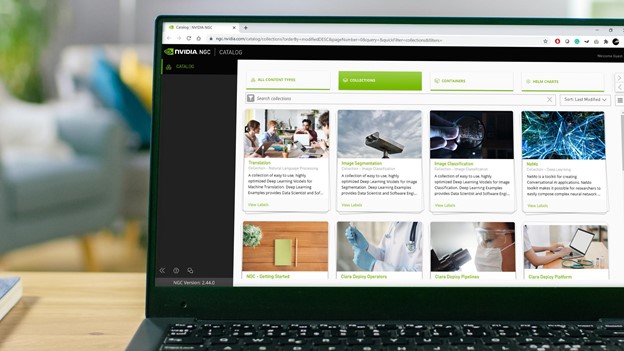
AI 工作流程十分複雜。建構 AI 應用程式不是容易的事,因為需要各種具備相關領域之專業知識的人,大規模開發和部署應用程式。資料科學家和開發人員需要能輕鬆存取模型、容器等軟體構件,且該等構件應具備安全性和高效能,以及建構 AI 模型需要的基礎架構。在建構應用程式之後,DevOps 和 IT 管理者還需要可以協助他們在內部、雲端或邊緣的各種裝置上,流暢部署和管理這些應用程式的工具。
NVIDIA 透過建立 NGC 目錄,簡化和加快 AI 工作流程,讓使用者可以輕鬆存取 GPU 最佳化的軟體,例如建構 AI 應用程式需要的容器、預先訓練好的模型、應用程式框架以及 Helm chart。
本文說明了如何使用 NGC 目錄及其核心基礎功能(例如 Collection、NGC Private Registry、AI 構件)建構和部署口罩偵測應用程式,做為呈現開發至部署工作流程的範例。
簡化使用者旅程
在推出 NGC Collection 後,NVIDIA 簡化了整體使用者體驗,並將您需要的相關容器、模型、程式碼及 Helm chart 集中在相同的位置,即無須在目錄中尋找和協調各種個別構件。
您可以找到針對特定任務工作負載的 NGC Collection,例如自動語音辨識或影像分類,以及產業 SDK,例如 NVIDIA Clara 或轉移學習工具套件(TAO Toolkit)。若想要建構物件偵測應用程式,則可在目錄中搜尋該collection,將能在相同的位置找到所有相關資源。
先決條件
首先,在建構應用程式之前,需先完成以下事項:
- 配置 GPU 執行個體:
- 安裝與配置 Docker 執行階段。
- 安裝與配置 NGC CLI。
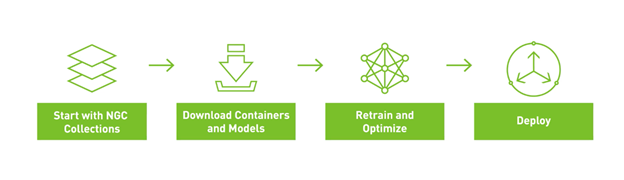
圖 1 所示為重建整個範例的整體工作流程。從 NGC Celloection 開始,下載相關的模型和容器,重新訓練、最佳化模型以進行推論,然後使用 Helm chart 部署模型,以進行推論。
擷取和啟動 TLT 容器
如前所述,NGC Collection 使建構 AI 變得非常流暢。我們將所有深度學習軟體應用程式、相關模型以及程式碼範例,皆集中在易於使用的單一位置,讓您能輕鬆快速地找到需要的所有內容。
在 TLT collection 中,詳細介紹了 TLT 是什麼、如何運作以及從何處開始的說明。Entities 索引標籤也列出了協助使用 TLT 的所有 NGC 內容:容器、模型、Helm chart 及其他資源。
第一步是從 NGC 將 TLT 容器擷取至 GPU 執行個體上。欲深入瞭解如何安裝和配置 Docker,請參閱 Orientation and setup。欲深入瞭解 TLT 容器本身,請從 TLT collection 的 Entities 索引標籤中,選擇 TAO Toolkits For Streaming Video Analytics 容器。
容器頁面中提供了所有資訊,包括相依性和入門說明文件。在最上層中繼資料區域中有一個 Docker 命令程式碼區塊,可以將此容器提取至 GPU 執行個體中。
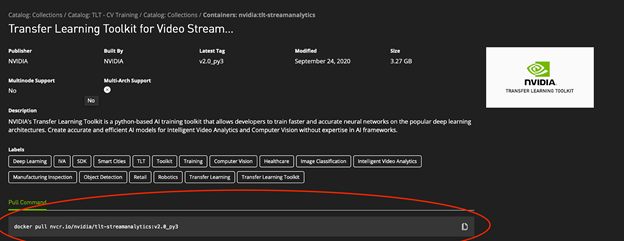
將 Docker 命令複製及貼至終端機工作階段中,可將最新版本 GPU 最佳化的 TLT 容器提取至本機電腦中:
$ docker pull nvcr.io/nvidia/tlt-streamanalytics:v2.0_py3
容器的概述頁面同時提供在互動式終端機工作階段中啟動容器需要的命令。Http 要求是轉送自 Jupyter notebook 的連接埠 80:8888。本機目錄是裝載於 GPU 執行個體上,可以存取轉移學習資料集:
$ docker run --gpus all -it -v "/path/to/dir/on/host":"/path/to/dir/in/docker" \ -p 80:8888 nvcr.io/nvidia/tlt-streamanalytics:v2.0_py3 /bin/bash
TLT 容器已預先安裝了 NGC CLI,讓您能以更簡單之方式使用目錄中的模型和程式碼。您可以使用此 CLI 取得本文章隨附的範例 notebook。其可使用以下命令,取得需要的所有說明和程式碼:
$ ngc registry resource download-version "nvidia/gtcfallngcdemo:1.0.0"
啟動 Jupyter notebook,並從網頁瀏覽器存取 notebook:
$ jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root
從 GitHub 取得資料集預處理指令碼
由於 TLT 要求資料集採用 KITTI 格式,因此必須從範例中取得協助函式指令碼,才能轉換部分原始資料。TLT GitHub 頁面提供了範例。執行以下命令:
!git clone https://github.com/NVIDIA-AI-IOT/face-mask-detection.git
可協助將函式指令碼下載至電腦上。下一步是安裝相依性:
#Fixes the fact that pip doesn't work in Ubuntu right now... !curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py !python3 get-pip.py --force-reinstall # Install dependencies !cd face-mask-detection && python3 -m pip install -r requirements.txt
下載資料集
口罩偵測示範使用了四種資料集:
- 戴口罩的人臉:
- Kaggle 口罩資料集
- MAFA – MAsked FAces:密碼:4fz6
- 未戴口罩的人臉:
下載的資料集必須位於特定的資料樹結構中,範例才能運作。如果已將需要的資料集下載至電腦,且資料集是位於需要的結構中,請修改以下命令,將它們複製到您的 GPU 叢集:
scp -r </home/workspace>
準備資料集
想要將資料集與 TLT 搭配使用,必須將資料集轉換成 KITTI 格式。之前下載的 GitHub 儲存庫,具有可以轉換四種資料集的協助函式指令碼。
以下為執行的範本命令:
python3 data2kitti.py --kaggle-dataset-path \
--mafa-dataset-path \
--fddb-dataset-path < FDDB dataset absolute directory path> \
--widerface-dataset-path \
--kitti-base-path < Out directory for storing KITTI formatted annotations > \
--category-limit < Category Limit for Masked and No-Mask Faces > \
--tlt-input-dims_width < tlt input width > \
--tlt-input-dims_height \
--train < for generating training dataset >
設定絕對路徑。如果之前已符合 SCP 命令的結構,則無須在下一個命令中進行任何變更。TLT_INPUT_DIMS 屬性取決於模型。該範例是使用 DetectNet-V2 的預設值。若需要更多資訊,請參閱 Object Detection with DetectNetv2。搜尋需要的模型架構及更新對應的值。
DetectNet_v2
- 輸入大小:C * W * H(其中 C = 1 或 3,W > =960,H >=544,W、H 是 16 的倍數)
- 影像格式:JPG、JPEG、PNG
- 標籤格式:KITTI 偵測
在將資料集轉換成 KITTI 格式時,請使用以下命令:
!python3 /workspace/face-mask-detection/data2kitti.py --kaggle-dataset-path $KAGGLE_DATASET_PATH \
--mafa-dataset-path $MAFA_DATASET_PATH \
--fddb-dataset-path $FDDB_DATASET_PATH \
--widerface-dataset-path $WIDERFACE_DATASET_PATH \
--kitti-base-path $KITTI_BASE_PATH \
--category-limit $CATEGORY_LIMIT \
--tlt-input-dims_width $TLT_INPUT_DIMS_WIDTH\
--tlt-input-dims_height $TLT_INPUT_DIMS_HEIGHT \
--train
從 KITTI 格式資料集準備 TF 紀錄
在處理資料之後,必須產生 TFRecords,這是開始訓練之前的最後一步。以下命令可以更新 TFRecords 規格檔案,以接受 KITTI 格式資料集,並使用 tlt-dataset-convert 建立 TFRecords。
首先,必須將從 GitHub 下載的範本規格檔案移動至 /Spec 目錄:
!mkdir detectnet_v2 !mkdir $SPECS_DIR !mv face-mask-detection/tlt_specs/* $SPECS_DIR !ls $SPECS_DIR
其次,編輯 $SPECS_DIR/detectnet_v2_tfrecords_kitti_trainval.txt 檔案,以指向轉換後的影像。此命令可以更新該規格檔案,以配合口罩偵測使用案例:
%env KITTI_CONFIG=kitti_config {\
root_directory_path: "/workspace/converted_datasets/train/"\
image_dir_name: "images"\
label_dir_name: "labels"\
image_extension: ".jpg"\
partition_mode: "random"\
num_partitions: 2\
val_split: 20\
num_shards: 10 }
在此步驟中是使用 TLT 資料集轉換函式,產生重新訓練模型需要的 TFRecord 檔案:
!tlt-dataset-convert -d $SPECS_DIR/detectnet_v2_tfrecords_kitti_trainval.txt \
-o $DATA_DOWNLOAD_DIR/tfrecords/kitti_trainval/
下載預先訓練模型
快完成了!想要使用 TLT 進行重新訓練時,請在 NGC 目錄中取得最新的物件偵測模型或 DetectNet 模型。
請注意,在 DetectNet_v2 方面,將以採取 RGB 順序的輸入通道,將輸入 0-1 正規化。因此,為了獲得最佳結果,請下載名稱中有 *_detectnet_v2 的模型。所有其他模型都是以均值減法和採取 RGB 順序的輸入通道進行輸入預處理,因此,使用它們做為預先訓練權重,可能會導致效能欠佳。
NGC CLI 可以列出目錄中的所有 DetectNet 模型:
!ngc registry model list nvidia/tlt_pretrained_detectnet_v2:*
建立目錄,以儲存預先訓練模型:
!mkdir -p $USER_EXPERIMENT_DIR/pretrained_resnet18/
現在可以從 NGC 目錄下載模型:
!ngc registry model download-version nvidia/tlt_pretrained_detectnet_v2:resnet18 \
--dest $USER_EXPERIMENT_DIR/pretrained_resnet18
使用 TLT 訓練-修剪-訓練口罩偵測器
訓練口罩偵測器分成三個階段:
- 使用轉移學習,以透過準備好的自訂資料集,重新訓練來自 NGC 目錄的預先訓練模型。
- 修剪該模型,以刪除不必要的權重。
- 重新訓練修剪後的模型,以確保準確度。
提供訓練規格檔案
必須提供訓練規格檔案給 TLT,才能開始重新訓練。您可以看到規格檔案包含下列資訊:
- 訓練資料集的 TFRecords
- 想要使用新產生的 TFRecords 時,請更新規格檔案中的 dataset_config 參數。
- 更新想要用於評估的倍數。如果是隨機資料分割,請僅使用倍數 0。
- 如果是依序分割,則可使用資料集轉換工具產生的任何倍數。
- 預先訓練模型
- 適用於即時資料擴增的擴增參數
- 其他的訓練(超)參數,例如批次大小、期數、學習率等等。
更新 detectnet_v2_train_resnet18_kitti.txt 訓練規格檔案,以指向從 NGC 目錄下載的模型權重:
workspace/detectnet_v2/specs/detectnet_v2_train_resnet18_kitti.txt
| 屬性 | 值 |
| tfrecords_path | /workspace/data/tfrecords/kitti_trainval/* |
| image_directory_path | /workspace/converted_datasets/train |
| pretrained_model_file | /workspace/detectnet_v2/pretrained_resnet18/tlt_pretrained_detectnet_v2_vresnet18/resnet18.hdf5 |
執行 TLT 訓練
現在將要訓練模型,方式是提供下列資訊給 TLT,以開始進行以下實驗:
- 訓練規格檔案(先前已檢視)
- 重新訓練模型的輸出目錄位置
- 先前指定的模型金鑰
- 用於訓練的網路類型
訓練可能需要數個小時才能完成。此範例是使用單 GPU,但是您可以使用多 GPU 或以叢集為基礎的系統,大幅加快訓練時間。
!mkdir -p $USER_EXPERIMENT_DIR/pretrained_resnet18/
現在可以從 NGC 目錄下載模型:
!tlt-train detectnet_v2 -e $SPECS_DIR/detectnet_v2_train_resnet18_kitti.txt \
-r $USER_EXPERIMENT_DIR/experiment_dir_unpruned \
-k $KEY \
-n resnet18_detector
評估已訓練的模型
在完成轉移學習之後,可以使用 TLT,根據測試資料評估模型的效能。
- -e-來自規格檔案的實驗詳細資訊。
- -m-經過重新訓練的模型。
- -k-先前指定的模型金鑰。
!tlt-train detectnet_v2 -e $SPECS_DIR/detectnet_v2_train_resnet18_kitti.txt \
-r
$USER_EXPERIMENT_DIR/experiment_dir_unpruned \
-k $KEY \
-n resnet18_detector
修剪已訓練模型
修剪模型是很重要的步驟,因為可以將模型最佳化,並刪除不必要的權重,以滿足對於串流視訊使用案例而言不可缺少之低延遲推論的需求。參數如下所示:
- -m-修剪預先訓練的模型。
- -eq-等化標準,適用於 ResNet 和 MobileNet 模型。
- -pth-修剪閾值。0.01 是 detectnet_v2 模型極佳的起點。
- -k-儲存/載入模型的金鑰。
- -o-已修剪模型的輸出目錄。
以下為修剪模型的程式碼:
!tlt-prune -m $USER_EXPERIMENT_DIR/experiment_dir_unpruned/weights/resnet18_detector.tlt \
-o $USER_EXPERIMENT_DIR/experiment_dir_pruned/resnet18_nopool_bn_detectnet_v2_pruned.tlt \
-eq union \
-pth 0.8 \
-k $KEY
重新訓練已修剪的模型
必須重新訓練修剪的網路,以恢復在修剪階段失去的準確度。首先,更新實驗檔案,並將 model_config 檔案中的 load_graph 設為 true。然後,使用修剪後的模型做為經過預先訓練的權重,更新重新訓練的規格。
如果模型的 mAP 降低,則可能表示原本訓練的模型修剪過度。嘗試降低上一步中的修剪閾值,以降低修剪比例,並使用新模型進行重新訓練。
現在,可以編輯 detectnet_v2_retrain_resnet18_kitti.txt 檔案,以變更以下參數:
workspace/detectnet_v2/specs/detectnet_v2_retrain_resnet18_kitti.txt
| 屬性 | 值 |
| tfrecords_path | /workspace/data/tfrecords/kitti_trainval/* |
| image_directory_path | /workspace/converted_datasets/train |
| pretrained_model_file | /workspace/detectnet_v2/experiment_dir_pruned/resnet18_nopool_bn_detectnet_v2_pruned.tlt |
您可以使用 TLT 重新訓練已修剪模型,如下所述:
# Retraining using the pruned model as pretrained weights
!tlt-train detectnet_v2 -e $SPECS_DIR/detectnet_v2_retrain_resnet18_kitti.txt \
-r $USER_EXPERIMENT_DIR/experiment_dir_retrain \
-k $KEY \
-n resnet18_detector_pruned
評估已修剪模型
您可以使用 tlt-evaluate 評估經過修剪和重新訓練的模型,並檢視人臉偵測器的效能:
!tlt-evaluate detectnet_v2 -e $SPECS_DIR/detectnet_v2_retrain_resnet18_kitti.txt \
-m $USER_EXPERIMENT_DIR/experiment_dir_retrain/weights/resnet18_detector_pruned.tlt \
-k $KEY
匯出 TLT 模型以進行推論
最後一步是匯出 TLT 模型,使用 DeepStream 進行推論,以便能在現場使用口罩偵測器應用程式。使用 tlt-export 公用程式匯出權重:
!mkdir -p $USER_EXPERIMENT_DIR/experiment_dir_final_pruned
# Removing a preexisting copy of the etlt if there is one.
import os
output_file=os.path.join(os.environ['USER_EXPERIMENT_DIR'],
"experiment_dir_final/resnet18_detector_pruned.etlt")
if os.path.exists(output_file):
os.system("rm {}".format(output_file))
!tlt-export detectnet_v2 \
-m
$USER_EXPERIMENT_DIR/experiment_dir_retrain/weights/resnet18_detector_pruned.tlt \
-o
$USER_EXPERIMENT_DIR/experiment_dir_final_pruned/resnet18_detector_pruned.etlt \
-k $KEY
準備 DeepStream 配置檔
為了能將模型與 NVIDIA DeepStream 應用程式有效搭配使用,以進行推論,請更新配置檔,配合新訓練的模型。更新下列參數:
/workspace/face-mask-detection/ds_configs/config_infer_primary_masknet_gpu.txt
- tlt-encoded-model-部署在 DeepStream 容器中時,模型的相對路徑。如果遵循此 notebook,則路徑為 ./resnet18_detector_pruned.etlt
- labelfile-path-notebook 標籤檔案的相對路徑 ./labels.txt
- input-dims-應與先前設定的 input-dims 值相符:960×544。
- model-engine-與模型檔案相同的路徑,但有 .engine
- network-mode-部署的網路模式。由於使用了即時串流,此值必須為 2
無須針對標籤檔案進行任何變更,因為使用的類別與來自 GitHub 之範例相同。
- mask-正向結果,主體有戴口罩。
- no-mask-反向結果,視訊中的主體未戴口罩。
- default-DetectNet 模型的預設值。
您同時必須取得 DeepStream 容器中提供的 DeepStream 配置,但由於是使用 Helm 進行部署,因此必須建立本身的配置。取得來自 GitHub 的範例,並針對您的使用案例進行修改。
配置需要兩個屬性:
- RTSP Stream Location-視訊來源的 URL。
- DeepStream Inference Config-已更新模型的推論配置路徑。
由於之前已更新此配置,因此無須採取其他動作。
!wget https://raw.githubusercontent.com/ChrisParsonsDev/ngc-gtc-content/master/demo-assets/dsconfig.txt
現在可以使用 TLT 重新訓練 DetectNet 模型,識別串流視訊中戴口罩的人。最終階段是使用 Helm chart 部署應用程式。
將模型發布至 NGC Private Registry
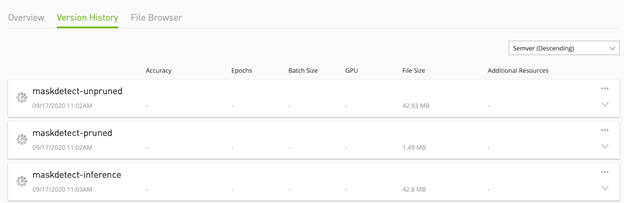
您可以將最終模型上傳至 NGC private registry,以便其他團隊成員可以在他們的使用案例中運用該模型。但是此為非必要條件,因為您也可以從本身的內部儲存庫部署模型。在完成之後,應可以在 NGC Private Registry UI 中看到列出的模型(圖 3)。
圖 4 為 NGC 中的模型版本。
使用 Helm 封裝應用程式
NGC 具有完整的 Helm Registry,您可以使用其管理 Helm chart 以及 Helm 目錄。您可以修改 NGC 目錄中提供的 DeepStream 圖表,為口罩偵測器建立已封裝部署模式。
下載與安裝 Helm 和外掛程式
第一步是在您的環境中下載與安裝 Helm。即可下載或發表 chart 至 NGC Private Registry。必須安裝下列元件:
- Helm-協調工具。
- Helm 推送外掛程式-適用於將圖表發布至 NGC。
想要安裝 Helm 時,請使用以下命令:
!curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 !chmod 700 get_helm.sh !./get_helm.sh
想要安裝推送外掛程式時,請使用以下命令:
!helm plugin install https://github.com/chartmuseum/helm-push.git
登入 NGC Helm Registry
NGC 文件提供了與配置 Helm 環境有關的逐步說明。您可以使用之前設定的 NGC CLI API 金鑰,透過 Helm 服務進行驗證。必須新增兩個 Helm 儲存庫:公用目錄(可以取得入門 DeepStream 圖表)和 NGC Private Registry(可以分享和修改圖表,以使用人臉偵測器模型)。
登入 NGC 目錄和 private registry:
!helm repo add ngc-catalog https://helm.ngc.nvidia.com/nvidia # Edit the repo name/url to match your private registry !helm repo add ngc-privatereg https://helm.ngc.nvidia.com/ngcvideos --username=\$oauthtoken --password=$NGC_KEY
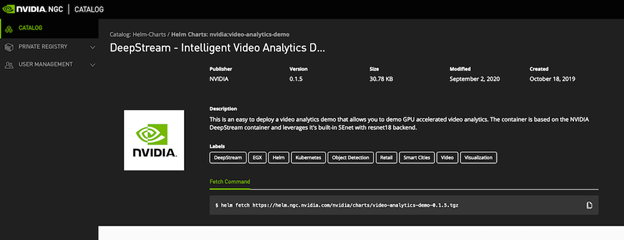
下載 DeepStream Helm chart
從 NGC 下載 DeepStream 圖表,並修改口罩偵測使用案例。使用 Helm CLI 檢查是否在 NGC 目錄中:
!helm search repo video-analytics-demo
然後,將圖表從 NGC 目錄,提取至本機環境。NGC UI 使此工作流程變得容易。如同提取模型和容器,請直接在使用者介面中使用 helm fetch 命令(圖 5)。
修改圖表以使用模型
從 NGC 目錄中下載圖表之後必須進行修改,以搭配口罩偵測器模型。
- 重新命名 private registry 的圖表。
- 將圖表解壓縮。
- 編輯圖表以指向模型。
- 封裝圖表。
在 values.yaml 檔案中的 ngcModel 標題下編輯以下屬性,將圖表指向人臉偵測器模型:
- getModel-從 private registry 下載模型的 NGC CLI 命令。
- name-模型的名稱。
- filename-模型檔案的名稱。
- modelConfig-模型的配置檔。
編輯 camera 的詳細資訊,以指向您的視訊資料流:
- camera1-攝影機的 rtsp 資料流連結。
您可以新增資料列,以新增其他攝影機,例如 camera2、camera3,依此類推。
在範例中,使用以下屬性更新 values.yaml 檔案:
| 屬性 | 值 |
| getModel | wget –content-disposition https://api.ngc.nvidia.com/v2/models/ngcvideos/facemaskdetector/versions/maskdetect |
| name | facemaskdetector |
| filename | resnet18_detector_unpruned.etlt |
| modelConfig | /opt/nvidia/deepstream/deepstream5.0/samples/configs/tlt_pretrained_models/config_infer_primary_detectnet_v2 |
| camera1 | rtsp://admin:password@IPAddress/Streaming/Channels/101 |
您可以執行程式碼範例,以查看完成的 values.yaml 檔案。
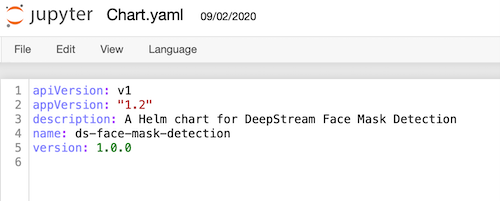
之後,更新 chart.yaml 檔案,以更新已修改圖表的名稱描述和版本號:
- name-已封裝圖表的名稱。
- description-圖表的簡要描述。
- version-圖表的 SemVer 版本。
更新後的值,應如下所示:
| 屬性 | 值 |
| name | ds-face-mask-detection |
| description | DeepStream 口罩偵測的 Helm chart。 |
| Version | 1.0.0 |
將圖表發布至 NGC private registry
在編輯圖表值之後,封裝 Helm chart,並發布至 private registry。第一步是使用 helm package 命令,封裝圖表:
!helm package video-analytics-demo
以下命令可將該圖表推送至 private registry:
!helm push ds-face-mask-detection-1.0.0.tgz ngc-privatereg
您可以使用 NVIDIA Fleet Command 混合雲端平台,或執行 helm install 命令進行部署。將應用程式部署及附加至 RTSP 攝影機資料流之後,將能即時偵測人們是否戴口罩。
總結
本文說明透過使用所有的構件,利用 NGC Collection 建構人臉偵測應用程式的完整流程,例如容器、預先訓練模型,以及 Helm chart。您也可以使用 NGC 目錄中的其他 collection,針對您的使用案例自訂 AI 應用程式。
欲深入瞭解如何開始建構自己的口罩偵測應用程式,請參閱 NGC GTC Fall 2020 Notebook.ipynb notebook。