軟體剖析是達到系統最佳效能的關鍵,而資料科學和機器學習應用程式也是如此。在 GPU 加速深度學習的時代,當剖析深度神經網路時,必須瞭解 CPU、GPU,甚至是可能會導致訓練或推論變慢的記憶體瓶頸。
於本文章中,我們將探索從基礎技術到進階技術的許多分析方法。我們同時提供了一些根據剖析結果,將深度學習模型最佳化的技巧和訣竅。
在深入探索剖析之前,在以下提供一些基本資訊。我們在不同的框架上,使用以 ResNet50 為基礎的影像分類模型,例如 TensorFlow 和 PyTorch。我們在使用 TensorFlow 和 PyTorch 剖析 ResNet50 模型時,是採用 NVIDIA DGX A100 系統上最新與效能最強的 NVIDIA A100 GPU。此 GPU 具有 40 GB 的記憶體,並支援多種資料類型,包括新的資料類型 TensorFloat-32 (TF32)。我們採用多種工具進行剖析,以展示替代方案。
nvidia-smi
使用 GPU 的第一個重要工具是 nvidia-smi Linux 命令。此命令會顯示出與 GPU 有關的實用統計資料,例如記憶體用量、功耗以及在 GPU 上執行的處理序。目的是查看是否有充分利用 GPU 執行模型。
首先,是檢查利用了多少 GPU 記憶體。通常是希望看到模型使用了大部分的可用 GPU 記憶體,尤其是在訓練深度學習模型時,因為表示已充分利用GPU。功耗是 GPU 利用率的另一個重要指標。通常,啟動的 CUDA 或 Tensor 核心越多,消耗的 GPU 功率越高。
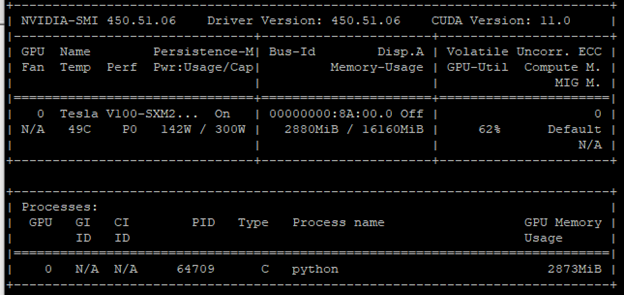
如圖 1 所示,未充分利用GPU。此結論是根據兩個指標獲得:
- 功耗:142 W / 300 W
- 記憶體用量:2880 MB / 16160 MB
GPU 利用率(GPU-Util)欄位的利用率為 62%,證實了此結論。解決方法之一是增加批次大小。啟動更多核心,以處理更大的批次。於此情形下,即可充分利用 GPU。
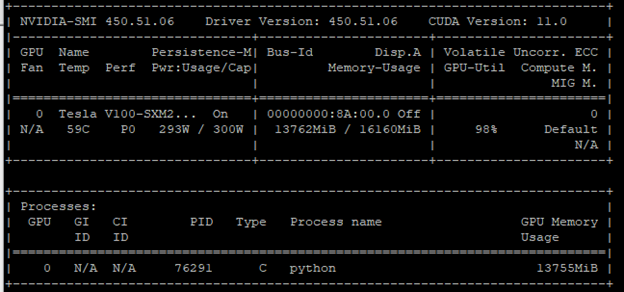
增加批次大小及進行相同的 Python 程式呼叫。如圖 2 所示,GPU 利用率為 98%。檢查功耗和記憶體用量,即可證實此結果,它們已接近極限。
您已經完成初步最佳化,使用較大的批次大小,即幾乎佔用所有 GPU 記憶體的批次大小,是在深度學習領域中提高 GPU 利用率最常使用的最佳化技術。
nvidia-smi 顯示的指標不是僅有功耗和記憶體用量。您也可以嘗試 nvidia-smi dmon,以滾動方式列出更多的 GPU 統計資料,如圖 3。
每一個 GPU 都有多個串流多處理器(streaming multiprocessors),執行 CUDA 核心。使用眾多串流多處理器表示已充分利用 GPU。如圖 3 所示,串流多處理器利用率在呼叫開始時大約為 0%,之後在實際訓練開始時上升至 90 幾。除串流多處理器利用率外,nvidia-smi dmon 也會列出下列統計資料:
- 功耗(pwr)
- GPU 溫度(gtemp)
- 記憶體溫度(mtemp)
- 記憶體利用率(mem)
- 編碼器利用率(enc)
- 解碼器利用率(dec)
- 記憶體時脈速率(mclk)
- 處理器時脈速率(pclk)
截至目前為止,範例僅使用一個 GPU。在有多個 GPU 的情況下,nvidia-smi 和 nvidia-smi dmon 會分別顯示出各個 GPU 的指標。在有多個 GPU 時,可以利用的另一個工具是 nvidia-topo -m。此呼叫會顯示出 GPU 裝置的拓撲以及彼此連接的方式。
圖 4 所示為 DGX A100 系統的拓撲配置,有 8 個 A100 GPU 與 NVLink 連接。選擇特定 GPU 執行工作負載時,建議選擇與 NVLink 連接的 GPU,因為它們具有較高的頻寬,尤其是在 DGX-1 系統上。
截至目前為止,我們已經示範如何使用 nvidia-smi 工具分析 GPU 的利用率。這些指標係指出是否有充分利用 GPU。在建模時,應始終以徹底利用 GPU 為目標,以充分利用加速運算。
TensorFlow 和 DLProf
GPU 利用率是進行剖析和最佳化之極佳的起點。您可以採用 DLProf、PyProf 等工具,進行更多詳細的建模分析。您也可以利用使用者介面目視檢查程式碼。Deep Learning Profiler(DLProf)支援 TensorBoard,讓您可以目視檢查模型。
以下程式碼範例是使用 TensorFlow 1.15 訓練 ResNet50 模型。其同時可連結 DLProf 參數,在訓練模型時執行剖析。
dlprof --nsys_opts="--sample=cpu --trace 'nvtx,cuda,osrt,cudnn'" \
--profile_name=/ecan/tf_a100_profiling --nsys_base_name=resnet50_tf_fp32_b408 \
--output_path=/ecan/tf_a100_profiling --tb_dir=resnet50_tf_fp32_b408 \
--force=true --iter_start=20 --iter_stop=40 \
python main.py \
--arch resnet50 \
--mode train \
--data_dir /ecan/tfr \
--export_dir /ecan/results \
--batch_size 256 \
--num_iter 100 \
--iter_unit batch \
--results_dir /ecan/results \
--display_every 100 \
--lr_init 0.01 \
--seed 12345
python main.py 以後的程式碼,是開始針對 ResNet50 模型(取自 NVIDIA DeepLearningExamples GitHub 儲存庫)進行訓練。開頭的 dlprof 命令設定,是用於進行剖析的 DLProf 參數。下列 DLProf 參數是用於設定輸出檔案和資料夾名稱:
- profile_name
- base_name
- output_path
- tb_dir
force 參數設為 true,以覆蓋現有的輸出檔案。iter_start 和 iter_stop 參數指定剖析工具注意的迭代範圍。如果是較大的模型,請限制剖析量,因為產生的檔案會快速變大。
DLProf 使用內部的 NVIDIA Nsight Systems 剖析器,而 nsys_opts 參數可用於傳遞 NVIDIA Nsight 參數。sample 參數用於指定是否收集 CPU 樣本。trace 參數用於選擇追蹤的呼叫。
在此設定中,我們選擇收集 nvtx API、CUDA API、作業系統執行階段,以及 CUDNN API 呼叫。DLProf 可以與預設參數搭配使用,例如 dlprof python main.py,預設參數可以提供良好的涵蓋範圍。我們在此處使用更多選項,示範如何透過 DLProf 自訂 NVIDIA Nsight 參數,並獲得更詳細的剖析輸出。
DLProf 呼叫產生兩個檔案,sqlite 和 qdrep,以及 events_folder。這些檔案包含剖析器追蹤的所有運算。您可以將 Qdrep 檔案饋入 Nsight Systems,在其中目視檢查剖析輸出。您可以從命令列以及透過具有視覺化使用者介面的應用程式,使用 Nsight Systems 剖析器。使用以下命令啟動 TensorBoard:
tensorboard --logdir events_folder
圖 5 所示為 DLProf 外掛程式 TensorBoard 範例。
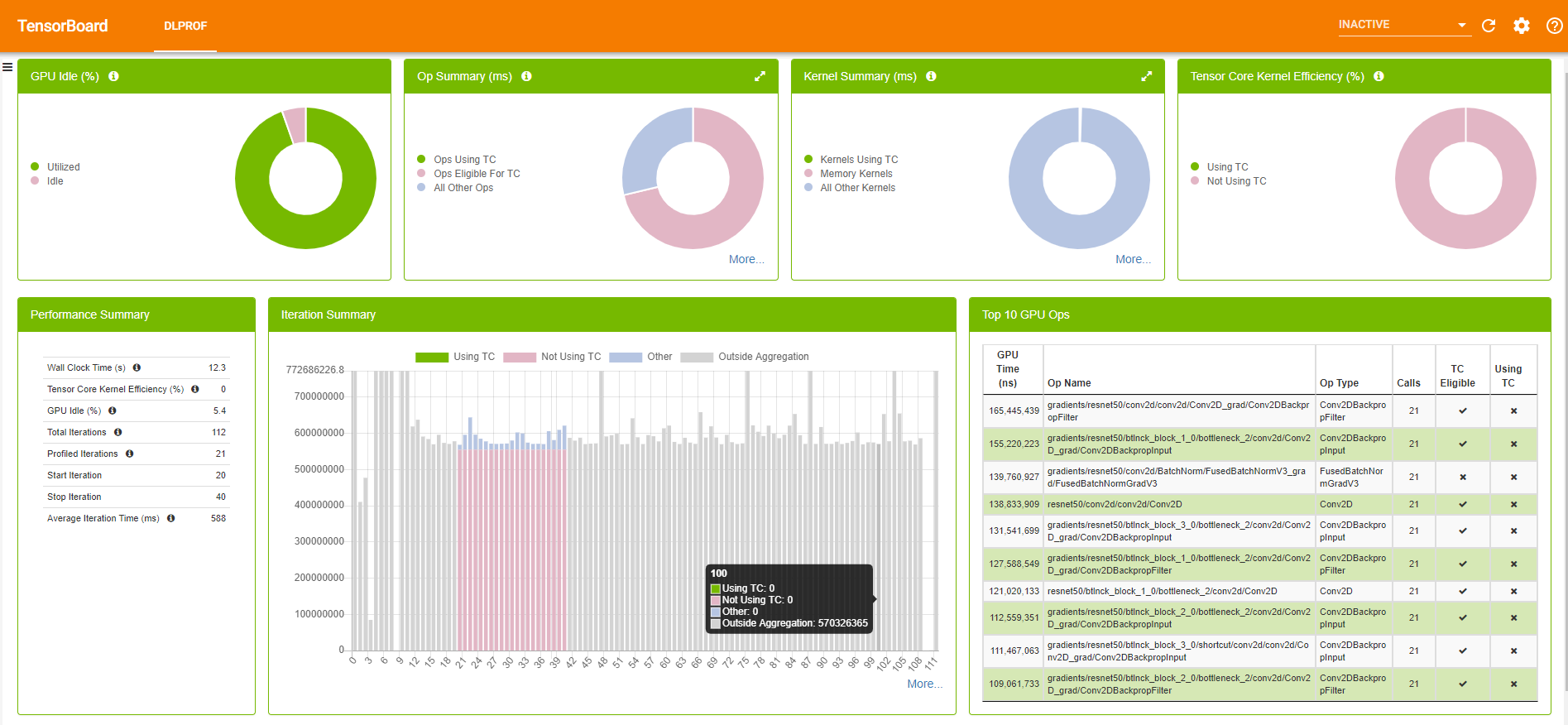
DLProf 外掛程式 TensorBoard 提供大量的模型資訊,從迭代花費的平均時間,到前 10 名的耗時核心。若需要更多與 DLProf 使用者介面有關的資訊,請參閱 DLProf Plugin for TensorBoard 使用指南。
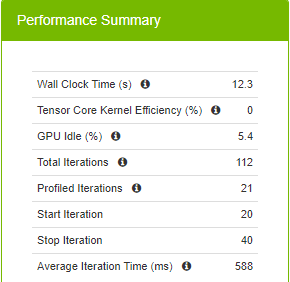
圖 6 所示為與訓練有關的執行階段指標。20 次迭代花費的總時間為 12.3 秒,該命令定義從第 20 次迭代開始,到第 40 次迭代停止,每一次迭代平均 588 毫秒。
每一次迭代平均花費 588 毫秒時,表示未利用 A100 支援的新精度類型 TF32。TF32 在矩陣乘法中使用較少的位元,同時提供相同的模型準確度,因此可加快迭代速度。除需要處理的位元較少外,TF32 同時利用了 Tensor 核心,一種深度學習的專用硬體,有助於加快矩陣乘法和累加運算。Volta (V100)、Turing (T4) 和 Ampere (A100) 世代 GPU 皆具有 Tensor 核心。
TF32 在 NVIDIA NGC TensorFlow 和 PyTorch 容器中是預設為啟用,並由 NVIDIA_TF32_OVERRIDE=0 和 NVIDIA_TF32_OVERRIDE=1 環境變數控制。
在啟用 TF32 後,進行相同的呼叫,而不變更任何參數。圖 7 呈現出前 10 名 GPU 運算以及是否使用 Tensor 核心(TC)。
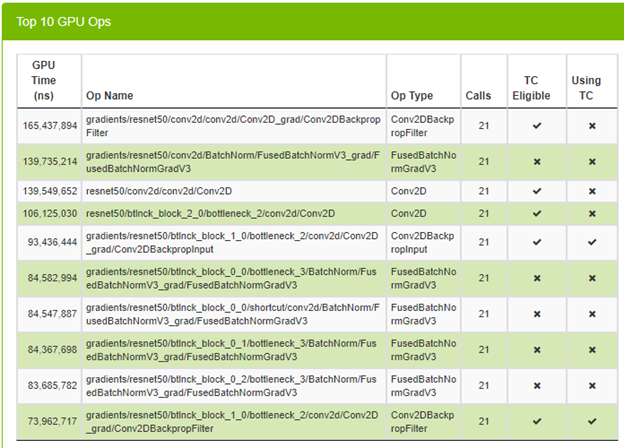
您可以看到某些運算已經使用 Tensor 核心,非常好。查看每一次迭代花費的平均時間,以檢查是否有加速效果。
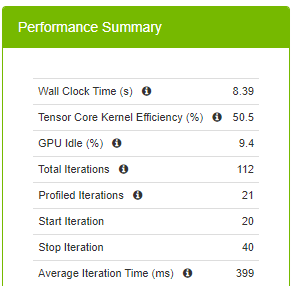
在切換至 TF32 精度時,平均迭代時間從 588 毫秒縮短成 399 毫秒。切換一個環境變數即可大幅加速。重點在於是否可以做到比 399 毫秒更好。您知道是由 DLProf 提出此建議,因此可以做到比 588 毫秒更好。

DLProf 不僅提供大量的模型資訊,同時會提出改進建議。在此範例中,其建議啟用 XLA 和 AMP(automatic mixed precision,自動混合精度)。XLA 是以加快線性代數運算為目標的線性代數編譯器。數值精度描述是用於表示值的位數。混合精度是以運算方法結合不同的數值精度。將某些張量上的儲存的需求和記憶體流量減半,能以較低的精度訓練深度學習網路,以達到高傳輸量。混合精度可以加快大型矩陣到矩陣乘加運算的訓練速度。
想要啟用 XLA 和 AMP,請在 NVIDIA 容器中設定以下環境變數 container:
export TF_XLA_FLAGS="--tf_xla_auto_jit=2" export TF_ENABLE_AUTO_MIXED_PRECISION=1
最近,大多數儲存庫皆已內建 XLA 和 AMP,通常只需傳遞相關參數。在此範例中,它們是 use_xla 和 use_tf_amp。在啟用 XLA 和 AMP 之後,可以讓模型有效率地使用 Tensor 核心、減少需要的記憶體數量,並利用更快的線性代數運算。
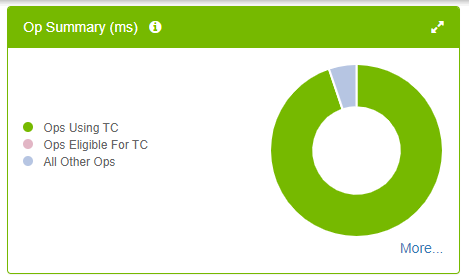
如圖 10 所示,幾乎所有符合 Tensor 核心條件的運算,皆已使用 Tensor 核心,圓餅圖中沒有粉紅色分類。這是理想的情況,然而更重要的是有助於縮短訓練時間。
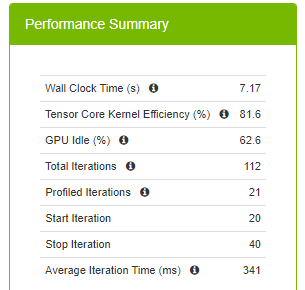
平均迭代時間從 399 毫秒以及 588 毫秒縮短成 341 毫秒。使用半精度產生的記憶體用量較少。為了進行公平的比較,請勿變更混合精度的批次大小。啟用 AMP 可以使模型的批次大小比全浮點精度高出一倍,並進一步縮短訓練時間。
總結來說,首先採用 TF32 精度及縮短訓練時間。然後,啟用 AMP 和 XLA,並進一步縮短使用 DLProf 輔助剖析時的訓練時間。
PyTorch 和 PyProf
本節示範如何在使用 PyTorch 建立模型時進行剖析。截至目前為止,我們已經示範數種最佳化技術。在 PyTorch 中,使用 TF32 和 AMP最佳化模型。
接著遵循更進階的途徑,在程式碼基礎中加入額外的程式碼。此外,直接使用 PyProf 和 Nsight Systems 剖析器,無須呼叫 DLProf。您仍可以使用 DLProf 和 TensorBoard 剖析 PyTorch 模型,因為 DLProf 亦可支援 PyTorch。但是,我們想要示範替代的剖析方式。
您可以挑選需要剖析的項目,例如僅剖析第 17 次迭代。在資料迭代迴圈中,檢查是否處於第 17 次迭代。如果是,則使用剖析器,開始和結束標記包圍執行正向傳遞、損失計算、梯度計算(反向)及更新參數(步進)的程式碼行。
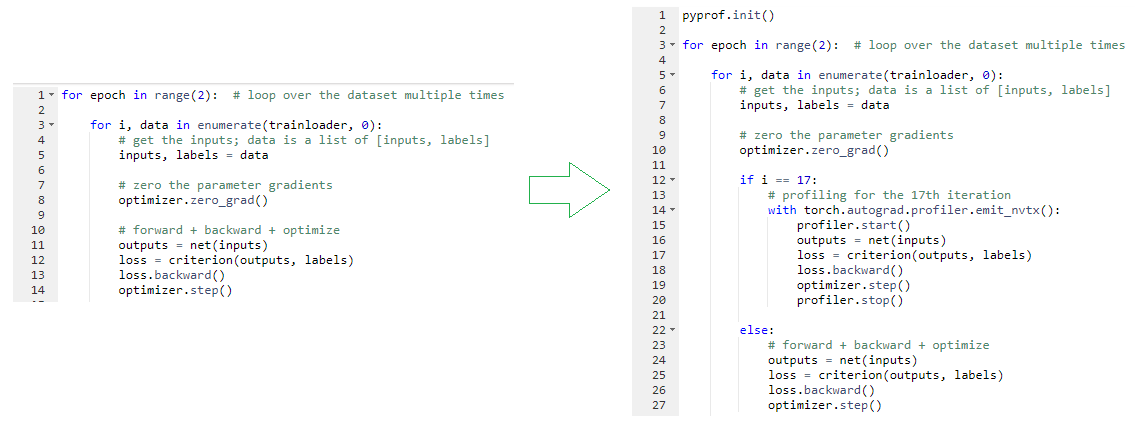
從相同的儲存庫取用 ResNet50 訓練程式碼。在訓練程式碼中變更剖析,並增加 pyprof 參數,以針對唯一的正向傳遞啟用剖析。您可以留下反向傳播,並任意設定範圍,然後推送至此分支,以供參考。在變更之後進行呼叫,以執行 PyTorch ResNet50 訓練及剖析:
nsys profile --trace 'nvtx,cuda,osrt,cudnn' -c cudaProfilerApi --stop-on-range-end true \ --show-output true --sample=cpu --export=sqlite \ -o /ecan/pytorch_a100_profiling/resnet50_pytorch_fp32_b256 \ python main.py /ecan/imagenet_small \ --raport-file raport.json -j16 -p 100 --lr 2.048 \ --optimizer-batch-size 256 --warmup 8 --arch resnet50 \ -c fanin --label-smoothing 0.1 \ --lr-schedule cosine --training-only --mom 0.875 --wd 3.0517578125e-05 -b 256\ --epochs 1 --workspace /ecan/results \ --pyprof
這一次,直接呼叫 Nsight Systems 剖析器。您已經知道 trace、sample 和 output (-o) 參數。增加 -c cudaProfilerApi –stop-on-range-end true 參數以通知剖析器,已導入開始和停止標記,使剖析器僅剖析兩者之間的事件。將 –show-output 參數設為 true 時,會將目標處理序 stdout 和 stderr 資料流列印至主控台。
此呼叫會產生兩個檔案:qdrep 和 sqlite。在 TensorFlow 中已使用 TensorBoard 的 event_files 資料夾,但是未碰觸 qdrep 檔案。這一次是使用 qdrep,在 Nsight Systems 應用程式中目視檢查剖析結果。
以下程式碼範例是使用 PyProf 呼叫,分析核心:
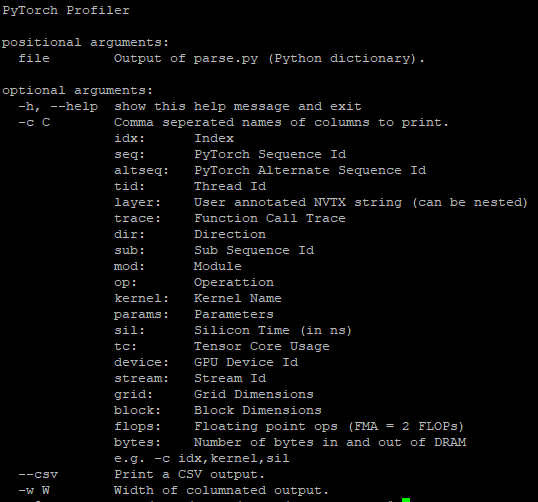
python -m pyprof.parse (resulting_sqlite_file_from_our_call) > a_file python -m pyprof.prof a_file -w 100 -c idx,trace,sil,tc,flops,bytes,kernel \ | (read -r; printf “%s\n” “$REPLY”; sort -k5 -n -r)
w 參數可設定欄位寬度,以及 c 參數可指定需要印出的選項。有多個選項,且我們選擇了這些選項,完整清單如下。我們同依據浮點運算次數排序,進行更好的分析,否則,依據執行順序排序。
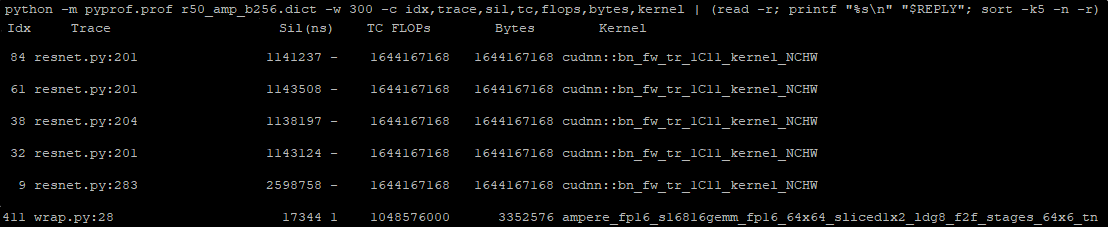
我們提供一些來自清單頂部的核心。前幾個是批次正規化核心。您也可以識別呼叫檔案的行號,例如 resnet50.py:201。有助於進一步瞭解這些核心統計資料,因為模型中可能有多個批次正規化。最後一行是使用半精度的矩陣乘法。它同時使用 Tensor 核心,非常好。
變更先前之 PyProf 呼叫的最後一行,以取得花在迭代正向傳遞上的總奈秒數:
python -m pyprof.prof a_file -w 100 -c idx,trace,sil,tc,flops,bytes,kernel \
| awk ‘{total+=$3}END{print total}’
呼叫的結果為 188,388,811 ns (188.4 ms)。截至目前為止,已使用 FP32 精度類型完成剖析。您已經知道切換至 TF32 精度類型,可以將程式碼最佳化。切換 NVIDIA_TF32_OVERRIDE 環境變數,即可利用 TF32 精度類型。
如果訓練和剖析呼叫相同,但是這一次是啟用 TF32 精度類型時,總時間為 110,250,534 ns (110.25 ms)。在切換至 TF32 之後,執行時間幾乎減半。
您已習慣在 TensorFlow 上進行最佳化,現在可以在 PyTorch 上,將程式碼最佳化。還有一個步驟:啟用混合精度,並檢查是否可以進一步將程式碼最佳化。
nsys profile --trace 'nvtx,cuda,osrt,cudnn' -c cudaProfilerApi --stop-on-range-end true \ --show-output true --sample=cpu --export=sqlite \ -o /ecan/pytorch_a100_profiling/resnet50_pytorch_amp_b256 \ python main.py /ecan/imagenet_small \ --raport-file raport.json -j16 -p 100 --lr 2.048 \ --optimizer-batch-size 256 --warmup 8 --arch resnet50 \ -c fanin --label-smoothing 0.1 \ --lr-schedule cosine --training-only --mom 0.875 --wd 3.0517578125e-05 -b 256 \ --amp --static-loss-scale 128 \ --epochs 1 --workspace /ecan/results \ --pyprof
大部分參數都與先前的呼叫相同,除 amp 和 static-loss-scale 參數外。amp 參數啟用 AMP,因為程式碼基礎可為其提供支援。static-loss-scale 參數調整損失。若需要更多與 ResNet50 訓練參數有關的資訊,請參閱 ResNet50 v1.5 For PyTorch 指南中的命令列選項一節。
在開啟 AMP 模式之情況下,執行呼叫的程式碼範例時,獲得 72,860,695 ns (72.86 ms)。這是好消息,因為已使用混合精度進一步將程式碼最佳化。在 TensorFlow 上可以獲得類似的改善。雖然 TensorFlow 已進行額外的最佳化(XLA),也可以僅使用 AMP,在 PyTorch 上獲得進一步的改善。
使用 Nsight Systems 進行剖析
截至目前為止,您已經使用透過剖析器呼叫從訓練中收集的統計資料。您同時已利用 PyProf 快速瀏覽模型中使用的核心。您使用 TensorBoard 和 DLProf 外掛程式產生絕佳的視覺化。在本文開頭,您是使用 nvidia-smi 檢查 GPU 利用率。如果您認為還不足夠,而想要深入探索時,無須擔心,我們還有更多的內容。
在完成包含剖析器呼叫的訓練之後,取得 qdrep 檔案。現在,讓我們透過 NVIDIA Nsight Systems 剖析器的使用者介面,更深入地分析模型。若需要更多資訊,請參閱 Nsight Systems 使用指南。
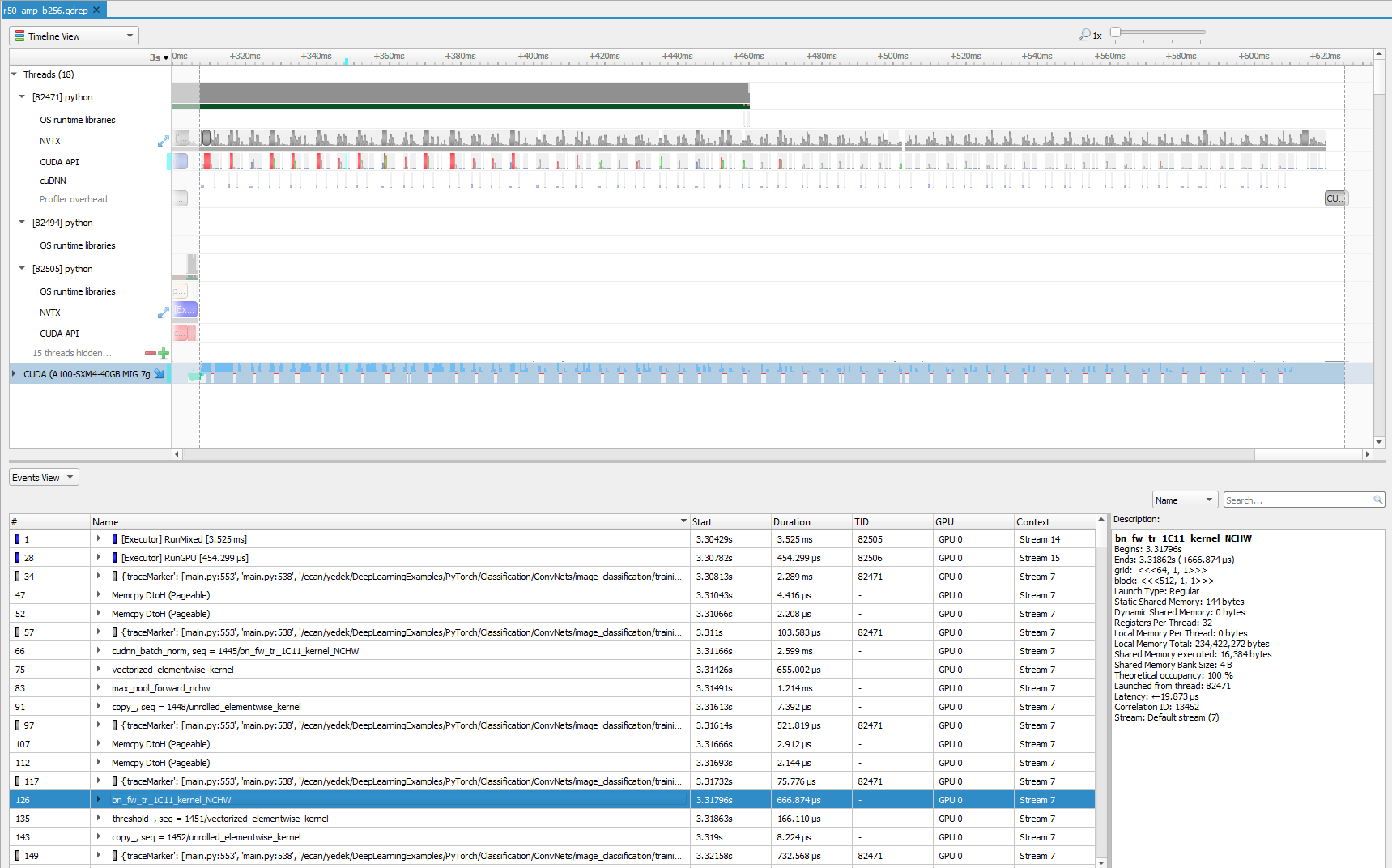
即使將剖析限制為僅限迭代正向傳播,也可以使用 Nsight Systems 剖析器目視檢查大量資訊。有時候我們會放大此畫面的特定區域,以進行進一步分析。想要仔細查看,請將訓練的開頭放大,並聚焦於幾毫秒。
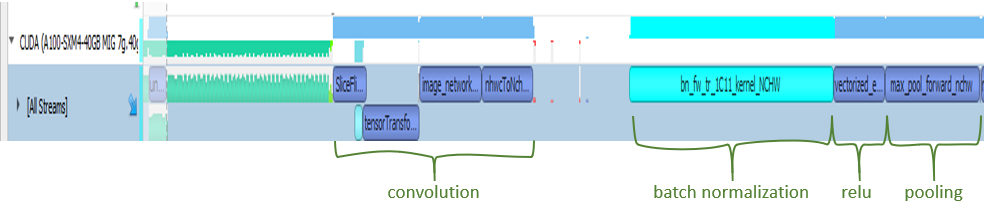
首先看到一些綠色的記憶體運算,接著是卷積運算。然後,開始將批次正規化。不出所料,下一步就是啟用函式。於此範例中,它是 ReLU。最後,看到執行最大池化。這是在程式碼基礎和大多數 ResNet 模型中看到的順序。您也可以查看堆疊追蹤,以取得更多與選擇之運算有關的資訊,在選取時會變成青綠色。

在結束本篇文章之前,我們想要示範另一種最佳化方法。在 PyTorch 中,可以變更記憶體格式。通常是使用以下格式儲存資料:
[ number of elements in the batch, number of channels (depth or number of filters), height, width ]
PyTorch 以 [n, h, w, c] 格式運作。以 [n, h, w, c] 格式處理類批次正規化層的速度較快。最耗時的運算是批次正規化,如圖 14 所示。此外,Tensor 核心原生採用 [n, h, w, c] 格式。基本上,透過變更記憶體格式,可以在處理類批次正規化層時節省一些時間,且可在 CUDNN 核心中避免一些格式轉換的時間。
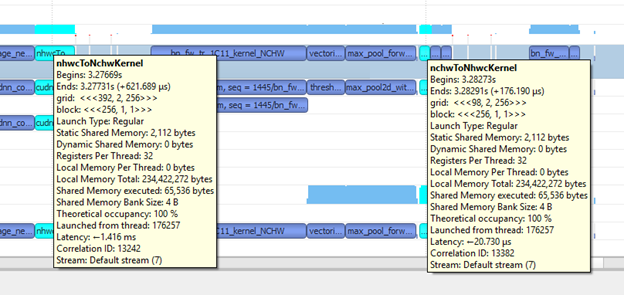
在先前的呼叫中增加 –memory format nchw 即可,且讓您可以使用 [n, c, h, w] 記憶體格式。在採用 [n, c, h, w] 記憶體格式之後,訓練不再需要記憶體格式轉換操作,例如 nhwcToNchwKernel 和 nchwToNhwcKernel,請參見圖 18。因此可以節省更多時間。換言之,您已透過變更記憶體格式,再次完成最佳化。為了確認這一點,請計算花在核心的總時間。我們的結果是 45,631,828 ns (45.6 ms)。在採用 [n, c, h, w] 記憶體格式時,大約為 70 毫秒。利用記憶體格式最佳化技術進一步縮短執行時間。
總結
本文詳細介紹了如何使用各種工具剖析深度學習模型:nvidia-smi、DLProf 和 PyProf,以及 NVIDIA Nsight Systems 剖析器。每一個工具都可以指出不同層級的效能改善機會。剖析是使用兩個常見的深度學習框架執行:PyTorch 和 TensorFlow。DeepLearningExamples GitHub 儲存庫中提供了程式碼範例,同時有 PyProf 和 PyTorch 呼叫的程式碼變更。建議您複製這些步驟,以便能更熟悉剖析工具。
若需要更多資訊,請參閱以下資源: