
無論是倉庫需要平衡產品配送與最佳化運量、工廠組裝線檢查,或醫院管理,以確保員工和照護人員使用個人防護裝備照顧患者時,皆可使用先進的智慧影像分析(intelligent video analytics,IVA)。
在基礎層,有數十億個攝影機和 IoT 感測器部署在世界各地的城市、體育館、工廠和醫院中,每天產生數 PB 的資料。在資料呈爆炸性成長的情況下,必須使用 AI 簡化和執行有效的 IVA。
許多公司和開發人員都在致力建構可管理的 IVA 工作流程,因為這些工作需要具備 AI 專業知識、高效率硬體、可靠的軟體以及大量資源,才能大規模地部署。NVIDIA 打造出 DeepStream SDK 以消除這些障礙,讓任何人都能輕鬆快速地建立以 AI 為基礎的 GPU 加速應用程式,以進行影像分析。
DeepStream SDK 是可為邊緣端建構高效能代管 IVA 應用程式的可擴充框架。您可以使用 DeepStream 為各種產業建構 AI 應用程式,從智慧城市和建築,到零售、製造以及醫療。
DeepStream 執行階段系統是一套端對端的流程,可以進行深度學習推論、影像和感測器處理,並在串流應用程式中將洞見傳送至雲端。您可以使用容器建構雲端原生的 DeepStream 應用程式,並透過 Kubernetes 平台執行協調,以進行大規模的部署。當部署在邊緣端時,應用程式可以在 IoT 裝置與雲端標準訊息代理程式(例如 Kafka 和 MQTT)之間通訊,以進行大規模的廣域部署。
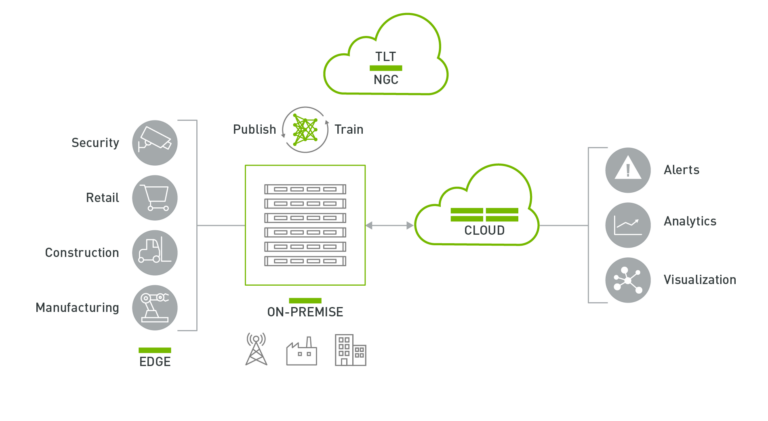
DeepStream 應用程式可在搭載 NVIDIA Jetson 的邊緣端裝置上,或在搭載 NVIDIA T4 的內部部署伺服器上執行。可以將來自邊緣端的資料傳送至雲端,進行更高層級的分析和視覺化。
本文章將深入探討 DeepStream 5.0 的主要功能。
DeepStream 5.0 功能
在推出 DeepStream 5.0 之後,NVIDIA 已能比以往更輕鬆地在邊緣端建構和部署以 AI 為基礎的 IVA 應用程式。新功能如下:
- 支援 NVIDIA Triton 推論伺服器
- Python 繫結
- 遠端管理和控制應用程式
- 安全通訊
- 透過 Mask R-CNN 執行個體分割
支援 Triton 推論伺服器
建立 AI 是一種迭代、實驗性的過程,資料科學家耗費大量的時間,使用不同的架構進行實驗和原型設計。在此階段,他們比較著重於如何有效解決問題,而非 AI 模型的效率。他們希望能有更多的時間,可以確保使用案例的高準確性,而非反覆將推論最佳化。他們希望能在實際情境中快速設計原型,並檢查模型的效能。
在過去,使用 DeepStream 執行影像分析時,必須將模型轉換成推論執行階段 NVIDIA TensorRT。從 DeepStream 5.0 開始,您可以選擇在訓練框架中,以原生方式執行模型。讓您能更快速地設計出端對端系統的原型。
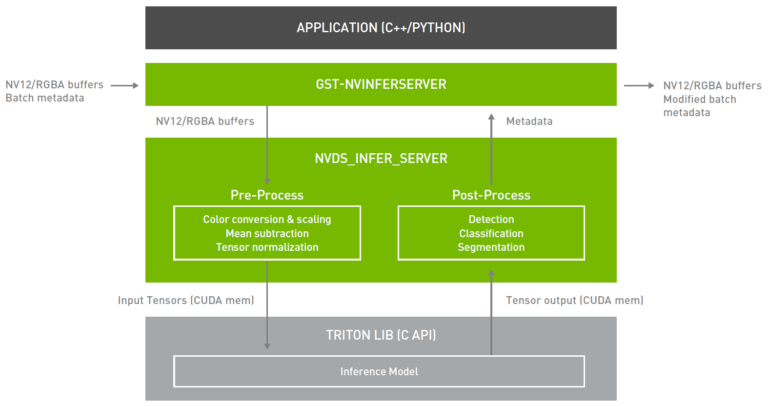
DeepStream 5.0 直接從應用程式整合 Triton 伺服器。Triton 伺服器讓您可以靈活地將任何深度學習框架與 DeepStream 搭配使用。推論服務是透過可用的 API,從 DeepStream 外掛程式(Gst-nvinferserver)進行原生整合。外掛程式會接收 NV12/RGBA 緩衝區,並將其傳送至較低層級的函式庫。該函式庫會將影像進行預處理,並轉換成模型可接受之需要的張量大小。張量是透過 CUDA 共用記憶體傳送至 Triton 伺服器函式庫。
在推論之後,Triton 伺服器會將輸出張量回傳至共用函式庫中進行後處理,以產生中繼資料。這些中繼資料被附加回現有的中繼資料並向下游傳送。您可以透過整合推論伺服器,使用 DeepStream 中的所有構件,建立高效率的 IVA 工作流程,以及在訓練框架上以原生方式執行推論。
DeepStream 仍支援 TensorRT。如果您需要最高推論傳輸量,或在資源有限的情況下部署完整框架和大型模型時,此方法為首選途徑。如果您需要靈活性,且可以捨棄一些效能時,Triton 伺服器則是最佳途徑。
下表列出兩種方法的優缺點。
| TensorRT | Triton 伺服器 | |
| 優點 | 最高傳輸量 | 最高靈活性 |
| 缺點 | 自訂層需要編寫外掛程式 | 效能不如 TensorRT 解決方案 |
Triton 伺服器搭配 DeepStream 的主要功能如下:
- 支援下列模型格式:
- Jetson 與 T4 上的 TensorRT、TensorFlow GraphDef 和 SavedModel,以及 TensorFlow-TensorRT 模型
- 僅 T4 上的 ONNX、PyTorch 和 Caffe2 NetDef
- 在同一個 GPU 上,可以同時執行多個模型(或同一模型的多個執行個體)。
為了開始使用 Triton 伺服器搭配 DeepStream,我們提供幾個範例配置檔和腳本以檢視開放原始碼模型,是可執行 TensorRT 和 TensorFlow 模型的範例。本文提到的 DeepStream 安裝目錄為 $DEEPSTREAM_DIR。實際之安裝目錄,將視您使用的是裸機版本或容器而定。
如果在 x86 平台上執行 NVIDIA GPU,請從 NVIDIA NGC 提取 nvcr.io/nvidia/deepstream:5.0-20.04-triton 容器。x86 上的 Triton 伺服器搭配 DeepStream 僅適用於 -triton 容器。如果在 Jetson 上執行,則 Triton 伺服器共用函式庫已預先安裝做為 DeepStream 的一部分。將可以與任何 Jetson 容器搭配使用。
前往/samples 目錄:
執行該目錄中的 bash 指令碼。該指令碼會下載所有需要的開放原始碼模型,並將提供的 Caffe 和 UFF 模型轉換成 TensorRT 引擎檔案。此步驟會將所有模型轉換成引擎檔案,因此可能需要幾分鐘或更長的時間。
產生之引擎檔案的最大批次大小是在 bash 指令碼中指定。若想要修改預設批次大小,則必須修改此指令碼。同時會下載 TensorFlow ssd-inception_v2 模型。
模型是在 /trtis_model_repo 目錄中產生或複製。執行 ssd-inception_v2 模型的方式如下。首先前往 /trtis_model_repo/ssd_inception_v2_coco_2018_01_28 目錄,並找出 config.pbtxt 檔案。如果能成功執行 bash 指令碼,應該會看到 1/model.graphdef。這是 TensorFlow 凍結的 graphdef。
這是模型儲存庫提供的範例 config.pbtxt 檔案。首先使用 platform 關鍵字指定深度學習框架。可用的選項如下所示:
- tensorrt_plan
- tensorflow_graphdef
- tensorflow_savedmodel
- caffe2_netdef
- onnxruntime_onnx
- pytorch_libtorch
- custom
其次,指定輸入維度、資料類型和資料格式。然後,指定所有的輸出維度以及所有輸出張量的資料類型。欲深入瞭解配置檔中的所有選項,請參閱模型配置。
platform: “tensorflow_graphdef”
max_batch_size: 128
input [
{ name: “image_tensor” data_type: TYPE_UINT8 format: FORMAT_NHWC dims: [ 300, 300, 3 ] }]
output [
{ name: “detection_boxes” data_type: TYPE_FP32 dims: [ 100, 4] reshape { shape: [100,4] } }, { name: “detection_classes” data_type: TYPE_FP32 dims: [ 100 ] }, { name: “detection_scores” data_type: TYPE_FP32 dims: [ 100 ] }, { name: “num_detections” data_type: TYPE_FP32 dims: [ 1 ] reshape { shape: [] } }]
接著使用 ssd_inception_v2 模型執行 deepstream-app。Triton 伺服器的範例配置檔在 /configs/deepstream-app-trtis 中。通常需要多個配置檔才能執行 deepstream-app。其中之一是為整個工作流程設定參數的頂層配置檔,其他則是用於推論的配置檔。
每一個推論引擎都需要一個唯一配置檔,才能方便使用與簡化。如果串聯多個推論,則需要多個配置檔。此範例使用以下檔案:
- source1_primary_detector.txt
- config_infer_primary_detector_ssd_inception_v2_coco_2018_01_28.txt
enable=1
(0): nvinfer; (1): nvinferserver
plugin-type=1
infer-raw-output-dir=trtis-output
batch-size=1
interval=0
gie-unique-id=1
config-file=config_infer_primary_detector_ssd_inception_v2_coco_2018_01_28.txt
source1_primary_detector.txt 檔案為頂層配置檔。若使用原生 TensorRT 或 Triton 伺服器進行推論則很常見。在此配置檔中,將 [primary-gie] 下的 plugin-type 改為 1,以使用推論伺服器。
config_infer_primary_detector_ssd_inception_v2_coco_2018_01_28.txt 檔案用於指定推論選項,例如預處理、後處理和模型儲存庫。欲深入瞭解不同的選項,請參閱 NVIDIA DeepStream SDK 快速入門指南和 NVIDIA DeepStream 外掛程式手冊。
為了將張量資料後處理至定界框,此範例是使用名稱為 NvDsInferParseCustomTfSSD 的自訂定界框剖析器,而該剖析器是由配置檔中的 custom_parse_bbox_func 機碼指定。此項自訂函式是在以下配置檔之 custom_lib 部分下指定的函式庫中編譯。$DEEPSTREAM_DIR/sources/libs/nvdsinfer_customparser/ 中提供 NvDsInferParseCustomTfSSD 的原始碼。
infer_config {
unique_id: 5 gpu_ids: [0] max_batch_size: 4 backend { trt_is { model_name: “ssd_inception_v2_coco_2018_01_28” version: -1 model_repo { root: “../../trtis_model_repo” log_level: 2 tf_gpu_memory_fraction: 0.6 } } } preprocess { network_format: IMAGE_FORMAT_RGB tensor_order: TENSOR_ORDER_NONE maintain_aspect_ratio: 0 normalize { scale_factor: 1.0 channel_offsets: [0, 0, 0] } } postprocess { labelfile_path: “../../trtis_model_repo/ssd_inception_v2_coco_2018_01_28/labels.txt” detection { num_detected_classes: 91 custom_parse_bbox_func: “NvDsInferParseCustomTfSSD” nms { confidence_threshold: 0.3 iou_threshold: 0.4 topk : 20 } } } extra { copy_input_to_host_buffers: false } custom_lib { path: “/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_infercustomparser.so” }}
input_control {
process_mode: PROCESS_MODE_FULL_FRAME
interval: 0
}
現在,使用以下命令執行應用程式:
會開啟範例影片的視窗,顯示出行人、汽車和單車周圍的定界框。
應用程式需要幾分鐘的時間建立 TensorFlow 圖譜。如果應用程式無法執行,並回傳「Killed」時,很有可能是系統記憶體不足。請檢查系統記憶體使用量,以確認問題。如果是記憶體問題,則修改 config_infer_primary_detector_ssd_inception_v2_coco_2018_01_28.txt 中 infer_config 下的 tf_gpu_memory_fraction 參數,或視情況根據模型修改任何其他 nvinferserver 配置檔。此參數會針對 TF 模型,分配每一個處理序的 GPU 記憶體配額。將其改為 0.4 可能會有幫助。欲深入瞭解如何使用此參數,請參閱 DS 外掛程式手冊 – Gst-inferserver。
此模型可以偵測多達 91 種類別,包括各種動物、食物和運動器材。欲深入瞭解可偵測的類別,請參閱 trtis-model-repo/ssd_inception_v2_coco_2018_01_28/labels.txt 檔案。
嘗試將此應用程式與其他影片同時執行,以檢查模型是否可偵測其他類別。若想要將 Triton 伺服器與自訂 DeepStream 工作流程搭配使用時,請在 $DEEPSTREAM_DIR/sources/apps/sample-apps/deepstream-app 下查看 deepstream-app 的原始碼。
Python 繫結
Python 很容易使用,而受到資料科學家和深度學習專家廣泛用於建立 AI 模型。將 NVIDIA 導入 Python 繫結,可協助使用 Python 建構高效能 AI 應用程式。可以使用 GStreamer 框架的 Python 繫結 Gst-Python 建構 DeepStream 工作流程。
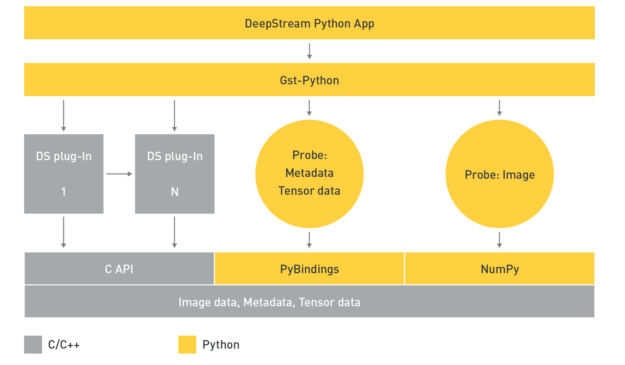
DeepStream Python 應用程式是使用 Gst-Python API 操作建構工作流程,並使用探測函式存取工作流程中各個點的資料。資料類型全都在原生 C 中,必須透過 PyBindings 或 NumPy 建立中介層,才能從 Python 應用程式存取資料。張量資料是在推論後產生的原始張量輸出。如果想要檢測物件,則必須透過剖析和叢集演算法,針對張量資料進行後處理,以在偵測到的物件周圍建立定界框。
在取得張量資料之後,即可在 Python 應用程式內建立剖析演算法。這很重要,因為張量資料的大小和維度以及剖析資料需要的剖析和叢集演算法,皆取決於 AI 模型的類型。如果您希望能將新的模型或新的後處理技術導入 DeepStream 時,將會發現真的非常有用。
另一個有用的資料來源是影像資料。可以記錄 AI 模型辨別物件的異常,且可以儲存影像以供日後參考。現在,已可透過應用程式支援存取此畫格。
DeepStream 中繼資料的 Python 繫結與範例應用程式為一併提供,以示範其用法。Python 範例應用程式可以從 GitHub 儲存庫 NVIDIA-AI-IOT/deepstream_python_apps 下載。現在 Python 繫結模組已成為 DeepStream SDK 套件的一部分。
遠端管理和控制應用程式
從邊緣端傳送中繼資料至雲端是很有用的,但是能夠從雲端至邊緣端接收和控制訊息同樣很重要。
DeepStream 5.0 已可支援雙向通訊,以傳送和接收雲端至裝置的訊息。此功能對於各種使用案例而言格外重要,例如觸發應用程式以記錄重要事件、變更操作參數和應用程式配置、無線(over-the-air,OTA)更新,或要求系統紀錄及其他重要資訊。
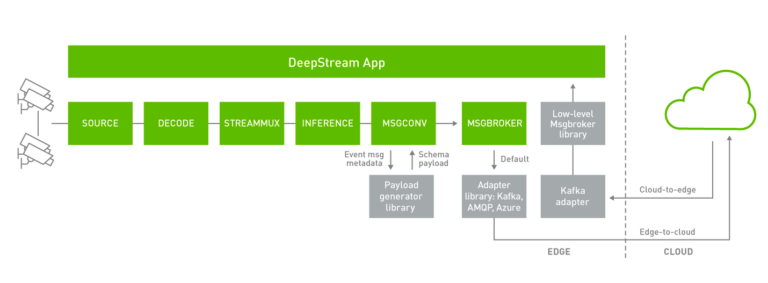
DeepStream 應用程式可以訂閱 Apache Kafka 主題,以接收來自雲端的訊息。目前是透過 Gstnvmsgbroker (MSGBROKER) 外掛程式進行裝置到雲端的通訊。Gstnvmsgbroker 外掛程式是預設為透過對應的協定,調用較低層級的轉接器函式庫。您可以選擇 Kafka、AMQP、MQTT 或 Azure IoT,或可以建立自訂轉接器。DeepStream 5.0 導入了新的低層級 msgbroker 函式庫,提供統一的介面,以透過各種協定進行雙向通訊。Gstnvmsgbroker 外掛程式提供與此新函式庫介接,而不直接叫用協定轉接器函式庫的選項,是使用配置選項進行控制。
在雲端至邊緣端的通訊方法,DeepStream 5.0 支援的協定為 Kafka,是使用新的低層級 msgbroker 函式庫,直接與 DeepStream 應用程式互動。
DeepStream 5.0 可支援一些能與雙向通訊搭配使用的其他 IoT 功能。現在 DeepStream 提供了一個 API,可以根據異常或雲端至裝置的訊息進行智慧記錄。此外 DeepStream 也可以在執行應用程式時,支援 AI 模型進行 OTA 更新。
智慧錄影
通常必須進行以事件為基礎的錄影。智慧記錄不會連續記錄內容,可以節省寶貴的磁碟空間,並提供更快的搜尋能力。
智慧記錄僅會在觸發特定規則或條件時記錄事件。指示記錄的觸發器可以來自應用程式本身、來自在邊緣端執行的某些服務,或來自雲端。
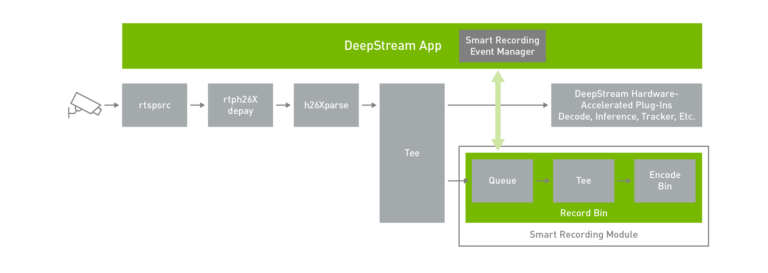
提供豐富的 API,以建構智慧記錄事件管理器。使用這些操作可以隨時開始和停止記錄。在必須記錄事件時,最有用的方式是在觸發之前,開始儲存影片。您可以透過智慧記錄 API 操作,設定為記錄事件發生前的時間。這是非常有用的方式,因為在偵測到及觸發異常時,發生異常的時間與記錄事件管理器開始記錄的時間之間存有些許延遲。在記錄開始之前記錄一段有限的時間,以提供整體事件的順序。
為了示範此功能,deepstream-test5 應用程式內建了智慧記錄事件管理器。智慧記錄模組會保留影片快取,不僅會錄影事件發生後的畫格,且會留存事件發生前的畫格。影片快取的大小可以根據使用案例進行設定。事件管理器會啟動智慧記錄模組的開始和停止選項。
可以透過從雲端接收的 JSON 訊息觸發記錄。訊息格式如下:
command: string // start: string // “2020-05-18T20:02:00.051Z” end: string // “2020-05-18T20:02:02.851Z”, sensor: { id: string }}
deepstream-test5 範例應用程式已示範了如何從雲端接收和處理此類訊息。目前支援 Kafka。若想要啟用此功能,請在應用程序配置檔中填入與啟用以下區塊:
[message-consumer0]
enable=1
proto-lib=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_kafka_proto.so
conn-str=;
config-file=
subscribe-topic-list=;;
Use this option if message has sensor name as id instead of index (0,1,2 etc.).
sensor-list-file=dstest5_msgconv_sample_config.txt
在執行應用程式時,請使用 Kafka 代理程式在 subscribe-topic-list 中的主題上發布上述 JSON 訊息,以開始和停止記錄。
欲深入瞭解如何在應用程式中使用此功能,請參閱 NVIDIA DeepStream 外掛程式手冊的智慧錄影一節。在以下目錄中可以找到 deepstream-test5 的原始碼:
在以下檔案中可以找到智慧記錄事件管理器的建置:
OTA 模型更新
邊緣端 IVA 應用程式的理想要求之一,是在 AI 模型強化時立即修改或更新模型,以提高準確性。您現在可以利用 DeepStream 5.0,在執行應用程式時更新模型。表示可以在零停機時間的情況下更新模型。這對於無法接受任何延遲的任務關鍵性應用程式而言很重要。
在必須不斷切換模型的情況下,此功能也很有用。例如根據時段切換模型。通常一個模型在光線充足的白天可能很有效,但是另一個模型在低光環境下的效果可能更好。在此情況下,必須根據時段輕鬆切換模型,而無須重新啟動應用程式。前提是需要更新的模型,應具有相同的網路參數。
在範例應用程式中,是由修改組態配置檔的使用者啟動模型更新。DeepStream 應用程式會監視與驗證在配置檔中進行的變更。在驗證變更之後,DeepStream OTA 處理程序會切換成新模型,以完成流程。
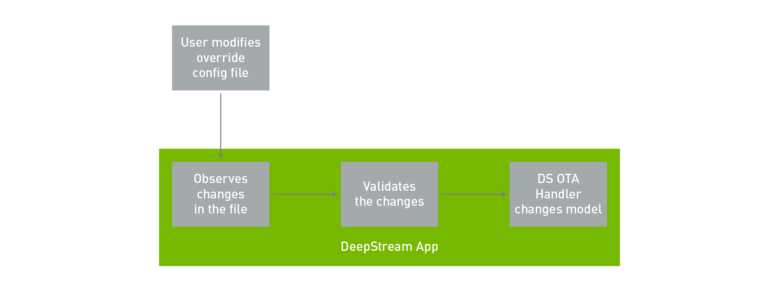
deepstream-test5 應用程式中已使用提供的原始碼示範此功能。請使用 -o 選項執行應用程式,以執行 OTA 模型更新。這是 OTA 覆蓋檔案。在切換模型時,請使用新的模型引擎檔案更新此檔案。
更新後的模型必須是 TensorRT 引擎檔案,並在變更 OTA 覆蓋檔案之前離線完成。若想要建立 TensorRT 引擎檔案,請執行 trtexec:
在產生模型後,請更新 OTA 覆蓋檔案。當應用程式偵測到此變更時,會自動啟動模型更新程序。在實際的環境中,將需要邊緣端常駐程式或服務,在邊緣端更新檔案或從雲端更新檔案。
安全通訊
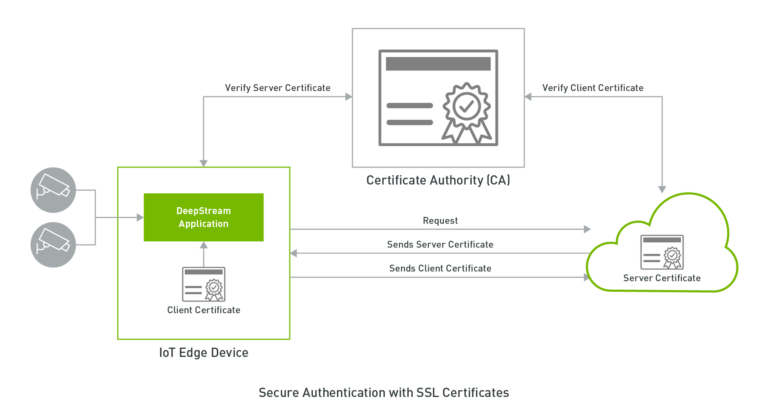
若想要大規模成功部署 IoT 裝置時,最重要且最常忽視的層面是安全性:可以在邊緣裝置與雲端之間安全地通訊。對公司而言,最重要的是保護 IoT 裝置,以及在受信任位置之間往返傳送和接收敏感資料。
使用 DeepStream 5.0 的 Kafka 轉接器,支援使用以 TLS 為基礎的加密進行安全通訊,進而確保資料的機密性。TLS(Transport Layer Security,傳輸層安全性)是 SSL 的後繼協定,但是在文獻中仍互換使用這兩個術語。TLS/SSL 通常是在連線至網路上的伺服器(例如 HTTPS)時,用於進行安全通訊。TLS 是使用公開金鑰密碼學,建立供 DeepStream 應用程式和代理程式對稱使用的工作階段金鑰,為工作階段期間傳輸的資料進行加密,因此即使在公用網路上傳送資料也能確保機密性。
DeepStream 5.0 支援兩種形式的用戶端驗證:以 SSL 憑證為基礎的雙向 TLS 驗證,以及以使用者/密碼機制為基礎的 SASL/Plain 驗證。用戶端驗證讓代理程式可以驗證與其連線的用戶端,並根據其身分選擇性地提供存取控制。SASL/Plain 是使用熟悉及易於設定的密碼驗證機制,雙向 TLS 則是以用戶端憑證進行驗證,並提供一些可以建置穩健之安全性機制的優點。
欲深入瞭解如何建置安全連線,請參閱 NVIDIA DeepStream 外掛程式手冊。
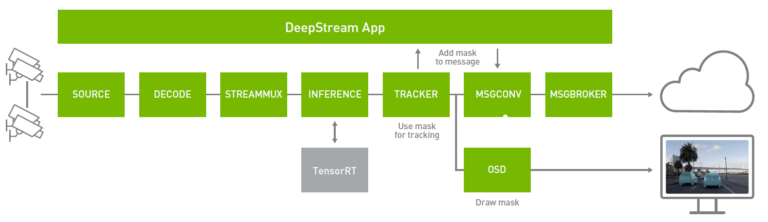
透過 Mask R-CNN 執行個體分割
電腦視覺是仰賴深度學習,提供對環境的理解,以感知產生可行之見解的像素。物件偵測是一種常用的技術,可識別畫格中的個別物件,例如人或汽車。雖然物件偵測對於某些應用有益,卻不足以在像素層級理解物件。
個體分割可在識別物件時提供像素層級的準確性。分割對於必須劃分物件與背景的應用非常有用,例如在採用 AI 的綠幕中,必須模糊或改變畫格的背景或分割畫格中的道路或天空。它也可以使用輸出中的執行個體遮罩,提高追蹤器的準確性。
DeepStream 是以新的自訂剖析器進行後處理、螢幕顯示(On-Screen Display,OSD)中的遮罩覆疊函式渲染分割遮罩、新的中繼資料類型處理遮罩,並以新的訊息結構描述在訊息轉換器中識別多邊形,在工作流程中實現執行個體分割。您可以使用追蹤器中的遮罩中繼資料改善追蹤、在螢幕上渲染遮罩,或透過訊息代理程式傳送遮罩中繼資料,進行離線分析。
若想要開始使用 Mask R-CNN,請從 NVIDIA-AI-IOT/deepstream_tlt_apps#tlt-models GitHub 儲存庫下載預先訓練模型。此模型是在 NVIDIA 內部汽車行車記錄器影像資料集上訓練,以辨識汽車。若需要更多資訊,請參閱 利用在NVIDIA 轉移學習工具中的 Mask R-CNN 訓練個體分割模型。
DeepStream SDK 包含兩個範例應用程式,以示範如何使用經過預先訓練的 Mask R-CNN 模型。可從 deepstream-app 呼叫 Mask R-CNN 模型。在以下目錄中提供了配置工作流程和模型的組態:
以下是 Mask R-CNN 模型執行的關鍵配置檔:
$DEEPSTREAM_DIR/samples/configs/tlt_pretrained_models/deepstream_app_source1_mrcnn.txt
$DEEPSTREAM_DIR/samples/configs/tlt_pretrained_models/config_infer_primary_mrcnn.txt
/deepstream_app_source1_mrcnn.txt 是 deepstream-app 使用的主要配置檔,並為整體影像分析工作流程設定參數。若需要更多資訊,請參閱參考應用程式配置。以下是必須根據模型修改的關鍵參數。在 [OSD] 下,將 display-mask 選項改為 1,會在物件上覆疊遮罩。
enable=1
gpu-id=0
border-width=3
text-size=15
text-color=1;1;1;1;
text-bg-color=0.3;0.3;0.3;1
font=Serif
display-mask=1
display-bbox=0
display-text=0
/config_infer_primary_mrcnn.txt 檔案是設定 Mask R-CNN 推論參數的推論配置檔。此檔案是由 [primary-gie] 部分下的主要 deepstream_app_source1_mrcnn.txt 配置參照。以下是執行 Mask R-CNN 需要的關鍵參數:
gpu-id=0
net-scale-factor=0.017507
offsets=123.675;116.280;103.53
model-color-format=0
tlt-model-key=
tlt-encoded-model=
output-blob-names=generate_detections;mask_head/mask_fcn_logits/BiasAdd
parse-bbox-instance-mask-func-name=NvDsInferParseCustomMrcnnTLT
custom-lib-path=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_infercustomparser.so
network-type=3 ## 3 is for instance segmentation network
labelfile-path=
int8-calib-file=
infer-dims=
num-detected-classes=<# of classes if different than default>
uff-input-blob-name=Input
batch-size=1
0=FP32, 1=INT8, 2=FP16 mode
network-mode=2
interval=0
gie-unique-id=1
no cluster
0=Group Rectangles, 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
MRCNN supports only cluster-mode=4; Clustering is done by the model itself
cluster-mode=4
output-instance-mask=1
在 parse-bbox-instance-mask-func-name 選項設定自訂後處理函式,以剖析推論的輸出。此函式是內建於 custom-lib-path 指定的 .so 檔案中。在以下目錄中提供了此函式庫的原始碼:
若想要執行應用程式,請執行以下命令:
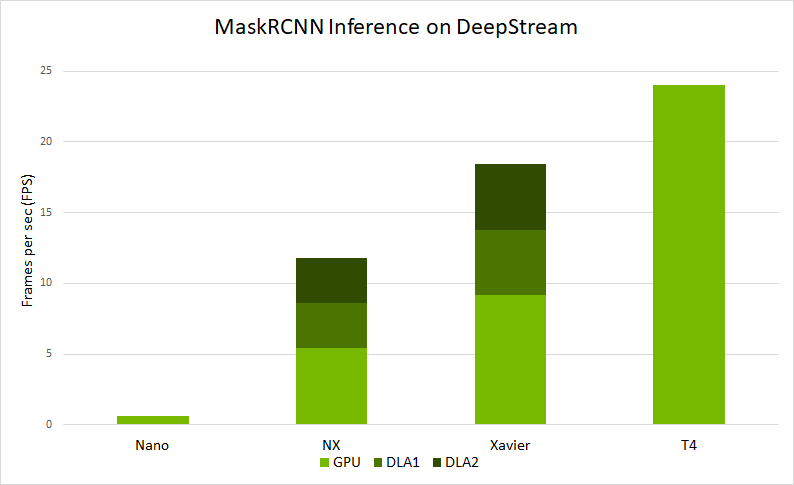
將會在 SDK 中提供的影片上執行。若想要在您的原始碼上測試,請修改 /deepstream_app_source1_mrcnn.txt 中的 [source0]。圖 9 顯示 deepstream-app 在各種平台上的端對端效能。效能是以 deepstream-app 處理的每秒畫格數(frames per sec,FPS)為單位:
- 在 Jetson Nano 和 DLA 上,以批次大小 1 執行。
- 在 Jetson AGX Xavier 和 Xavier NX 上,以批次大小 2 執行。
- 在 T4 上,以批次大小 4 執行。
雖然最好能將輸出視覺化,但是在實際使用案例中,可能是將中繼資料傳送至不同的處理序或雲端。邊緣端或雲端上的其他應用程式可以使用這些資訊,進行進一步的分析。
您可以藉由 DeepStream,使用為遮罩多邊形而定義的結構描述,透過支援的訊息代理程式協定(例如 Kafka 或 MQTT)傳送遮罩中繼資料。DeepStream 隨附 MaskRCNN 模型的邊緣端到雲端範例。欲深入瞭解如何使用訊息代理程式準備事件中繼資料和傳送遮罩資訊,請參閱以下應用程式:
為部署而建構
DeepStream 5.0 提供了許多實用功能,可以輕鬆地開發邊緣端部署的 AI 應用程式。您可以使用 Python API 操作和 Triton 伺服器快速進行原型設計,並輕鬆建立 IVA 工作流程。
可以透過 Triton 伺服器在訓練框架中原生部署 AI 模型,以增加靈活性。您可以使用眾多實用的 IoT 功能,建立可以管理的 IVA 應用程式。可以使用雙向 TLS 驗證,安全地將訊息從邊緣傳送到雲端。邊緣端與雲端之間的雙向通訊提供了更好的應用程式可管理性。可以用於更新邊緣端的 AI 模型、記錄重要事件,或從裝置擷取資訊。
請下載 DeepStream 5.0,立即開始使用。若需要更多資訊,請參閱以下資源:
深入瞭解採用 DeepStream 和 TLT 的 Jetson 開發人員社群專案