
在 1982 年熱門電視影集《霹靂遊俠》(Knight Rider)裡,由大衛.赫索霍夫(David Hasselhoff)飾演的李麥克,還有他所駕駛的霹靂車,也就是那部未來感十足的龐蒂克火鳥跑車,或許就能解答上述問題。
1982 年在由大衛.赫索霍夫主演的電視影集《霹靂遊俠》裡,他跟那部未來感十足,能協助他打擊犯罪的龐蒂克火鳥跑車對未來提出了預言。能自動駕駛又會說話的汽車還讓人藉由好萊塢的影集,瞭解什麼是影像及語言辨識技術。
要是現在編寫這套影集的劇本,李麥克那輛稱為「夥計」(KITT)的人工智慧車,將以搭配卷積神經網路(CNN)和循環神經網路(RNN)的深度學習技術來觀察四周車況、聽聲及說話。
原因在於機器現在使用 CNN 來消化處理影像,相當於眼睛的角色,以辨識不同物體;而 RNN 是數學計算引擎,相當於耳朵和嘴巴的角色,以解析各種語言模式。
從1980年代便開始快速發展的 CNN,是當今自動駕駛車、石油探勘及核融合研究的眼睛,用以更快速地在醫學影像裡找出疾病和挽救生命。
現代的「李麥克」跟其他數十億人一樣,即使在不知情的情況下,也能享受 CNN 帶來的優點,像是把朋友的照片 po 在 Facebook 上,FB 就會自動加上姓名標籤,提高個人的社交活躍程度。
那輛龐蒂克火鳥跑車如果少了 CNN,它便不再擁有電腦化的雙眼來進行自動駕駛,只是另一個啞巴道具。
拿掉那輛時髦感十足,又會自動駕駛的黑色龐蒂克火鳥跑車上的 RNN,那個聰明的電腦語音就不會再揶揄李麥克這個單身漢,更不用說也無法用法文和西班牙文來操控夥計。
毫無疑問的是,RNN 加快了語音方面運算革命的發展腳步。RNN 是處理自然語言的大腦,讓 Amazon 的 Alexa、Google 的 Assistant 及 Apple 的 Siri 擁有耳朵和嘴巴,可以聽取和發出語音;也為 Google 的自動填入功能提供未卜先知般的能力,當你在搜尋時它會自動填入字句。

再者,目前運用 CNN 與 RNN 打造出的汽車,早就超出好萊塢編劇們的幻想,各大車廠如今已在快速發展未來跟《霹靂遊俠》影集裡夥計一樣的車款。
現在的自動駕駛車在正式上路前,開發人員便在模擬環境裡測試和驗證車輛的雙眼,可以透過超越人類的感知能力來看清四周車況。
運用 CNN 及 RNN 之故,讓各類人工智慧機器擁有像人類一樣的眼睛和耳朵。數十年來在開發深度神經網路方面的進展,加上 GPU 在運用高效能運算來處理大量資料方面的進步,讓許多應用人工智慧的想法化為實際。
CNN 發展史簡介
人們常問我們是怎麼做到現在的程度。其實早在自動駕駛車出現前,研究一般人工神經網路的人員便受到人腦神經元間生物連結的啟發,而 CNN 的研究人員就是按照這種思維方式。
1988年是 CNN 發展史上的一個關鍵時刻。那一年 Yann LeCun 及另外三名作者 Léon Bottou、Yoshua Bengio 與 Patrick Haffner 共同發表了一篇極具影響力的報告《Gradient-based Learning Applied to Document Recognition》。
在該文中介紹了如何在最小預先處理程度的情況下,將這些學習演算法用於對手寫字母的模式進行分類。對 CNN 的研究成果證明了判讀銀行支票時的準確度打破紀錄,如今已在商業領域廣泛用於處理銀行支票。
這為人工智慧的應用前景帶來無比的希望。該篇報告首席研究員的 LeCun 在2003年成為紐約大學的教授,又在2018年加入 Facebook,成為該公司的首席人工智慧科學家。
第二次的突破性關鍵時刻發生在2012年。那時多倫多大學的研究人員 Alex Krizhevsky、Ilya Sutskever 與 Geoffrey Hinton 發表了《ImageNet Classification with Deep Convolutional Neural Networks》這篇具有開創性的報告。
在這篇報告裡說明了物體辨識的狀態。這三名研究人員訓練了一套深度卷積神經網路,對 ImageNet Large Scale Visual Recognition Challenge 賽事的120萬張影像進行分類,以在降低錯誤率的幅度方面打破紀錄之姿而贏得了冠軍。
這引發了現代人工智慧蓬勃發展的浪潮。
解釋 CNN:小狗還是小馬?
我們以下例來說明影像辨識。人類看到一隻大丹犬,知道這隻狗的體型很大,不過還是能看出這是一隻狗。電腦只會看到數字,它們要怎麼知道大丹犬並不是一匹小馬?那麼可以透過一層層的 CNN 來處理以數字來表現的像素,按照這種方式來分辨大丹犬的多種特徵以獲得答案。
現在讓我們更深入介紹 CNN 的技術層面。
CNN 由一個輸入層(像是以數字代表像素來呈現影像)、一個或多個隱藏層和一個輸出層所組成。
這些數學運算層有助於電腦一點一滴地定義影像的細節,以求最終能分辨出特定物體或動物或其它目標。不過在辨識時常會出錯,尤其是在訓練初期。
卷積層:
數學裡的卷積是一種循環函數,而在 CNN 裡卷積存在於兩個矩陣(以列和行排列的矩形數字陣列)之間,以形成第三個輸出用的矩陣。
CNN 在卷積層裡使用這些卷積來過濾輸入的資料和查找資訊。
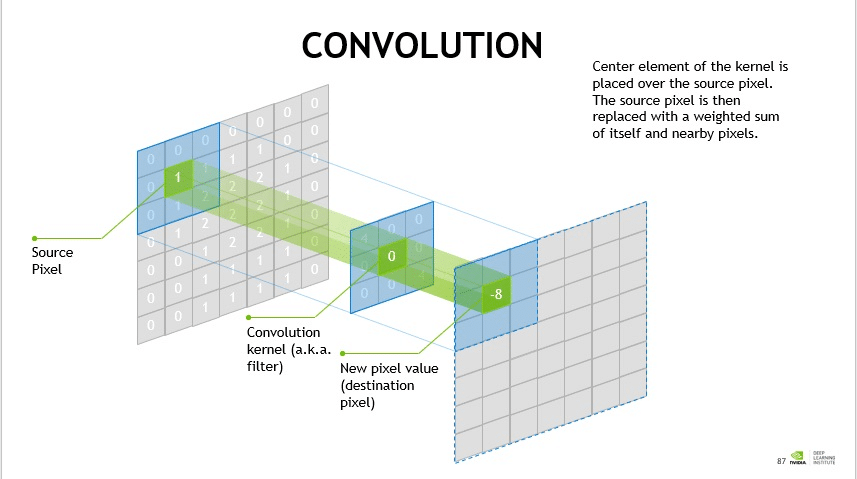
卷積層在 CNN 中負擔多數繁重的運算工作,當成數學過濾器以幫助電腦找出影像邊緣、暗區和亮區、顏色,以及高度、寬度和深度等其它細節。
通常會在一個影像上使用多個卷積層過濾器。
- 池化層:池化層(pooling layer)通常夾在卷積層之間,用於減小卷積層創造出的表示內容大小,還有減少對記憶體的需求,以置入更多卷積層。
- 歸一化層:歸一化(normalization)是一種用於提升神經網路效能和穩定性的技術,將所有輸入內容轉換成均值為0、變異數為1的情況,以便更容易管理各層的輸入內容。可以把標準化視為用以規範資料的角色。
- 全連結層:全連結層(fully connected layer)用於將一層裡的各神經元連接到另一層裡的所有神經元。
請見 NVIDIA 開發者專區網站的 CNN 頁面,會更深入介紹技術層面。
CNN 非常適合用於處理電腦視覺作業,不過要是提供充足資料給 CNN,它也能用於處理影片、語音、音樂和文字。
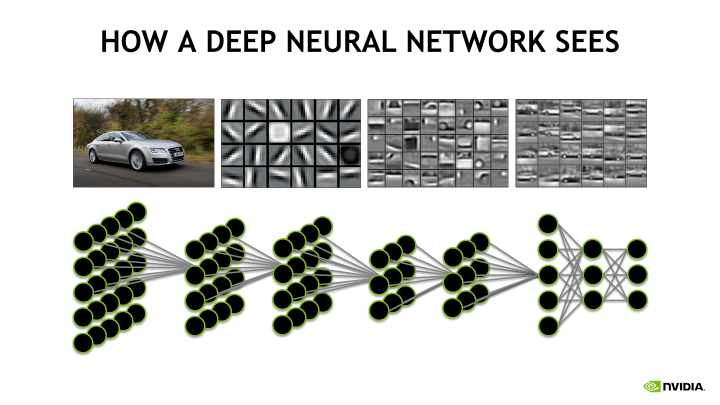
它們可以在這些隱藏層裡插入一系列已加強辨識影像效率的過濾器(或是神經元)。CNN 採用將資訊從這一層送到下一層的方式,又被稱為「前饋」神經網路。
或者 RNN 跟傳統人工神經網路及 CNN 採用幾乎相同的架構,除了它們具有當成回饋迴路的記憶體。就像是人腦會更重視資訊的新近度以預測句子,在談話時尤為如此。
這使得 RNN 適合用於預測一系列單字裡接下來的內容,還能將長度不一的資料序列送入 RNN,而 CNN 是使用固定的輸入資料。
RNN 發展史簡介
就像大衛.赫索霍夫這個冉冉升起的新星,RNN 自1980年代以來便一直存在。1982年 John Hopfield 發明了 Hopfield 網路,這是發展初期的 RNN。
Sepp Hochreiter 與 Jürgen Schmidhuber 在1997年發明 RNN 使用的長期短期記憶(LSTM)網。到了2007年左右,LSTM 在語音辨識方面的表現出現了長足的進步。
2009年有一套 RNN 贏得了手寫模式辨識競賽的冠軍。2014年中國的百度搜索引擎打破了 Switchboard Hub5’00 語音辨識標準,創下新的里程碑。
解釋 RNN:午餐要吃什麼?
RNN 是一個擁有稱為 LSTM 這種活性資料記憶體的神經網路,可以用於一系列資料以猜測接下來會發生的內容。
某些層的輸出內容透過 RNN 送回到前一層當成輸入項,如此一來便建立起回饋迴路。
我們利用這個經典的例子來說明一個簡單的 RNN:我們想要追蹤餐廳供應主菜的日期,嚴格奉行每週的同一天出同一道菜,假設週一提供漢堡、週二提供玉米餅、週三提供披薩、週四提供壽司、周五提供義大利麵。
在使用 RNN 的情況下,要是將輸出項「壽司」送回神經網路以判斷週五的主菜,那麼 RNN 就會知道序列中的下一個主菜是義大利麵(它已經知道主菜的順序,這時又剛送出週四的主菜資料,便能得知週五的主菜是什麼)。
這裡用句子來當成下一個例子:我跑了十英里,需要喝一杯______。人類會按照過去的經驗想出空格內要填入什麼,而過去可能有使用類似句子來訓練 RNN 的記憶功能,使得 RNN 可以預測接下來的內容,便會在空格處填入「水」這個字。
RNN 不單能用於處理自然語言和語音辨識,還能用於語言翻譯、股票預測和演算法交易。
神經網路圖靈機(neural Turing machine,NTM)則是能存取外部記憶體的 RNN。
最後所謂的雙向 RNN 接受一個輸入向量,並且在兩個 RNN 上訓練它,其中一個在常規 RNN 輸入序列上接受訓練,而另一個則是在反向序列上進行訓練,然後再將兩個 RNN 的輸出內容進行串連或合併。
總而言之,CNN 與 RNN 使得 app、網路及機器擁有更強大的視覺和語音能力,要是少了這兩項強大的人工智慧技術,很多機器就會變得一點都不有趣了。
像是 Amazon 的 Alexa 讓我們知道怎麼跟廚房裡的 Echo「收音機」聊天,用它奇特的人工智慧技術回答各種新的問題。
即將上路的自動駕駛車,會在我們的生活裡扮演主角。
如需獲得更深入關於 RNN 技術的資訊,請見 NVIDIA 開發者專區網頁。如需更多關於深度學習的資訊,請至NVIDIA 深度學習學院,以取得課程相關最新資訊。
https://soundcloud.com/theaipodcast/ai-podcast-dank-memes-lawrence-pierson