
即時理解自然語言的內容,將改變我們與智慧型機器和應用程式的互動方式。
迅速、智慧又自然的回應,才能造就出人和機器之間高品質的對話。
然而直到現在,開發出在背後支持著即時語音應用程式之語言處理神經網路的人員,面臨著一個兩難的取捨:到底要快速回應,而犧牲掉回應的品質;還是要提出一個智慧的回應,結果速度又太慢。
原因在於人類之間的對話異常複雜,要看說話的前後脈絡及先前的互動內容,才決定要怎麼說出下一句話,從話語中的梗到文化借鑒和文字遊戲,人們口中說出的話,一字一句都有著極其微妙的差異。每個幾乎是瞬間萌生的反應環環相扣,友人之間的聊天甚至在對方說話之前,就能料到這個人要說些什麼。
何謂對話式人工智慧?
真正的對話式人工智慧是一項語音助理,可以從事跟人類一樣的自然對話、取得對話裡的前後脈絡,再提供智慧回應。這樣的人工智慧模型規模碩大無朋,且極為複雜。
可是模型愈大,使用者發話與人工智慧回答之間的時間差就愈大,超過 0.3 秒便會使得對話聽起來很不自然。
真正的對話式人工智慧是以可進行擬人對話、擷取脈絡,並提供智慧化回應的語音助理。此類 人工智慧模型勢必很龐大,且極度複雜。
但是模型越大,使用者的問題與人工智慧回應之間的延遲就會越長。超過 0.3 秒的間隔,就可能會聽起來不自然。
利用 NVIDIA GPU、對話式人工智慧軟體和 CUDA-X 人工智慧函式庫,可以快速訓練與改進龐大、先進的語言模型,以在短短數毫秒 (千分之一秒) 內執行推論,而朝向終結快速人工智慧模型與大型複雜模型之間的取捨邁進一大步。
這些突破可以協助開發人員建構和部署目前最先進的神經網路,並讓我們更接近實現真正對話式人工智慧的目標。
GPU 最佳化語言理解模型,可以整合至醫療、零售、金融服務等產業的人工智慧應用程式中,在智慧揚聲器和客戶服務專線中驅動先進的數位語音助理。這些高品質對話式人工智慧工具,可以讓各領域的業者在與客戶互動時,提供過去無法達到的個人化服務標準。
對話式人工智慧的速度到底得多快?
在自然對話中,回應之間的間隔通常大約為 300 毫秒。想要讓人工智慧複製擬人互動,可能必須依序執行十幾個神經網路,以處理多層任務-都在 300 毫秒或更短的時間內完成。
回答問題涉及幾個步驟:將使用者的語音轉換成文字、理解文字的含義、在脈絡中搜尋想要提供的最佳回應,以及透過文字轉語音工具提供回應。每一個步驟都必須執行多個人工智慧模型-因此,可以供個別網路執行的時間大約為 10 毫秒或更短。
如果每一個模型都需要更長的時間執行,則回應會過於遲鈍,而使對話變得不協調與不自然。
在如此嚴格的延遲預算下,現在的語言理解工具開發人員必須進行取捨。當高品質的複雜模型可以做為聊天機器人使用時,延遲即不會如同在語音介面中那麼重要。或者,開發人員可以仰賴較小的語言處理模型,此類模型可以更快速地提供結果,但是缺少細膩的回應。
應用程式框架可以協助開發人員建構極度準確的對話式人工智慧應用程式,使其執行時間低於互動式應用程式要求的 300 毫秒閾值。企業的開發人員可以從已在 100,000 小時的先進模型開始。
企業可以使用遷移學習工具套件應用遷移學習,在自訂資料上微調這些模型。使這些模型更能理解公司的專有術語,進而提高使用者滿意度。可以透過 NVIDIA 的高效能推論 SDK TensorRT 最佳化模型,並部署可以在資料中心執行和擴充的服務。可以同時使用語音和視覺,創造使人機互動變得自然及更擬人化的應用程式。Riva 讓每一個企業都能使用過去僅供 人工智慧專家嘗試的世界級對話式人工智慧技術。
未來的對話式人工智慧會是什麼樣子?
電話樹演算法 (包含提示,例如「想要預訂新航班時,請說『預訂』」) 等基本的語音介面是屬於交易性,需要步驟和回應集合,以在預先設計的佇列中移動使用者。有時候,僅有位於電話樹末端的人類專員才能理解細膩的問題,並運用智慧解答來電者的問題。
現今市場上之語音助理的功能更多,但是,都是以複雜度不如本身的語言模型為基礎,僅有數百萬,而不是數十億個參數。這些人工智慧工具在回答問題之前,會提供如同「讓我為您查詢」的回應,因此可能會在對話過程中停滯。或者,它們會顯示網路搜尋的結果清單,而不是以對話式語言回答問題。
真正的對話式人工智慧將會更進一步。理想的模型具有充分的複雜度和速度,可以準確理解人類在銀行對帳單或醫療報告結果方面的疑問,並使用流暢的自然語言,以接近即時之方式回應。
此技術之應用可能包括醫師辦公室的語音助理,協助患者安排預約和追蹤血液檢驗,或零售業語音人工智慧向失望的來電者解釋包裹運輸延誤的原因,並提供商店信用額度。
對於此類先進對話式人工智慧工具的需求正在持續上升中:到 2020 年,預估將有 50% 的搜尋是透過語音進行,到 2023 年,將使用 80 億個數位語音助理。
什麼是 BERT?
BERT (Bidirectional Encoder Representations from Transformers,來自轉換器的雙向編碼器表示) 是龐大及需要密集運算的模型,在去年發布時,即為自然語言理解樹立了先進的基準。它可以透過微調,應用在各種語言任務,例如閱讀理解、情緒分析或問答。
在包含 33 億個英文單字的龐大語料庫上訓練的 BERT,在理解語言方面的表現非凡,且在某些情況下,甚至超越一般人。其優勢在於可以在無標籤資料集上訓練,且僅需要小幅修改,即可推廣至各種應用上。
BERT 可以理解多種語言,並可進行微調,以執行特定任務,例如翻譯、自動完成或針對搜尋結果進行排序。此種多用途性,使其成為發展複雜之自然語言理解的熱門選擇。
BERT 的基礎是轉換器層,可以替代遞迴神經網路,採用注意力技術-將注意力集中在句子前後最相關的單字,以剖析句子。
例如,「There’s a crane outside the window」可能是描述鳥或建築工地,視句子以「of the lakeside cabin」或「of my office」結尾而定。 如同 BERT 的語言模型,是採用稱為雙向或非定向編碼的方法,利用脈絡線索,進一步理解在各個情況下適用的含義。
現今各領域的主要語言處理模型都是以 BERT 為基礎,包括 BioBERT (適用於生物醫學文件) 和 SciBERT (適用於科學刊物)。
NVIDIA 的技術如何優化以 Transformer 為基礎的模型?
NVIDIA GPU 的平行處理能力和 Tensor 核心架構,可以在使用複雜的語言模型時提高傳輸量和擴充性-為 BERT 的訓練和推論提供破紀錄的效能。
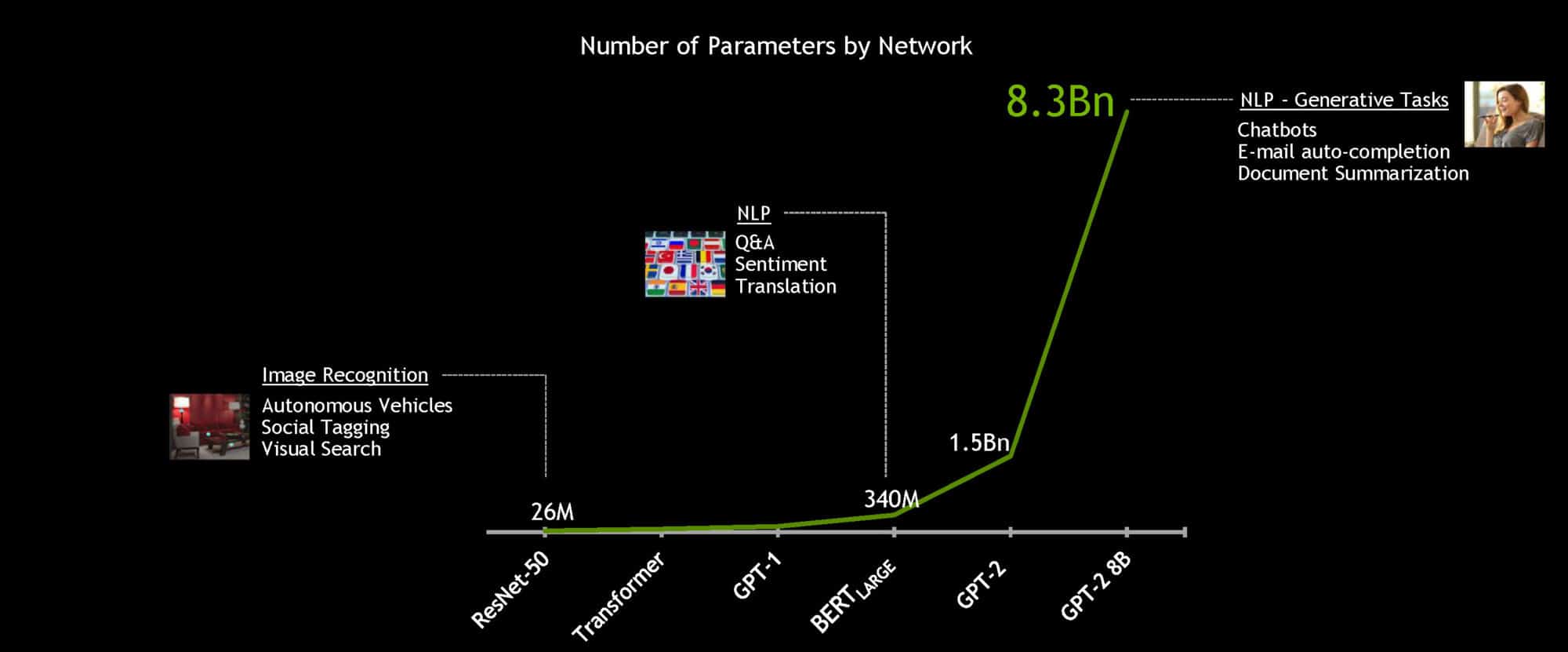
使用強大的 NVIDIA DGX SuperPOD 系統,可以在一小時內,訓練具有 3.4 億個參數的 BERT-Large 模型,而一般的訓練時間長達數天。但是針對即時對話式人工智慧而言,基本加速是為了推論。
NVIDIA 開發人員是使用 TensorRT 軟體,最佳化具有 1.1 億個參數的 BERT-Base 模型,以進行推論。模型在 NVIDIA T4 GPU 上執行,以及在 Stanford Question Answering Dataset 上測試時,可以在短短 2.2 毫秒內算出回應。該資料集稱為 SQuAD,是評估模型理解脈絡能力的常用基準。
許多即時應用程式的延遲閾值皆為 10 毫秒。即使是高度最佳化的 CPU 程式碼,處理時間也會超過 40 毫秒。
將推論時間縮短至幾毫秒之後,第一次使在生產中部署 BERT 變成可行。不僅止於 BERT-可以使用相同的方法,加快其他龐大、以轉換器為基礎的自然語言模型,例如 GPT-2、XLNet 和 RoBERTa。
為了朝真正對話式人工智慧的目標邁進,語言模型會隨著時間而變大。未來的模型將會比現在使用的模型大很多倍,因此,NVIDIA 打造出目前為止最大的轉換器人工智慧,並釋出開放原始碼:GPT-2 8B,具有 83 億個參數的語言處理模型,比 BERT-Large 大 24 倍。
瞭解如何自行建構以 Transformer 為基礎的自然語言處理應用程式
NVIDIA 深度學習機構提供由講師指導的實作訓練,教授如何使用基本工具和技術,建構以 Transformer 為基礎的自然語言處理模型,以執行文字分類任務,例如文件分類。參與由專家授課的 8 小時實作坊讓學員可以:
- 瞭解單字嵌入在 NLP 任務中如何迅速演變,從以 Word2Vec 和遞迴神經網路為基礎的嵌入,到以 Transformer 為基礎的的脈絡化嵌入。
- 瞭解如何使用 Transformer 架構功能 (尤其是自我注意力),建立沒有 RNN 的語言模型。
- 使用自我監督改進 BERT、Megatron 及其他變體中的 Transformer 架構,以獲得優異的 NLP 結果。
- 利用經過預先訓練的現代 NLP 模型,解決多項任務,例如文字分類、NER 和問題回答。
- 管理推論挑戰,並為即時應用程式部署完善的模型。
獲得 DLI 證書,以證明獲得相關主題的能力,並加快職涯成長。查看課程資訊,或為您的組織申請實作坊。
如需更多關於在 GPU 上訓練 BERT、優化 BERT 的推論能力,以及其它自然語言處理開發案的資訊,請見 NVIDIA 的開發者部落格專文內容。