
Python 在科學、工程、資料分析和深度學習應用生態系統中扮演關鍵角色。長期以來,NVIDIA 皆致力於協助 Python 生態系統利用 GPU 的加速大規模平行效能,提供標準化函式庫、工具和應用程式。如今,我們已經改善了 Python 程式碼的可移植性和相容性,進一步朝簡化開發人員體驗邁進。
我們的目標是以單一標準低階介面集合,協助統一 Python CUDA 生態系統,提供全面地覆蓋和從 Python 存取 CUDA 主機的 API。我們希望能提供生態系統基礎,讓不同的加速函式庫彼此互通。最重要的是,Python 開發人員可以更輕鬆地使用 NVIDIA GPU。
CUDA Python:漫長且曲折的道路
截至目前為止,想要透過 Python 存取 CUDA 和 NVIDIA GPU 僅能使用第三方軟體,例如 Numba、CuPy、Scikit-CUDA、RAPIDS、PyCUDA、PyTorch 或 TensorFlow。他們都在 CUDA API 與 Python 之間編寫各自的互通層。
NVIDIA 發布的 CUDA Python,可以讓這些平台供應商專注於各自的附加價值產品與服務。NVIDIA 同時希望能降低其他 Python 開發人員使用 NVIDIA GPU 的門檻。CUDA Python 初版包含用於 CUDA 驅動程式和執行階段 API 的 Cython 與 Python 包裝函式。
我們可能會在未來版本中,提供用於 CUDA 函式庫如 cuBLAS、cuFFT、cuDNN、nvJPEG 等的 Pythonic 物件模型和包裝函式。未來版本可能會與 GitHub 上的開放原始碼一併提供,或透過 PIP 和 Conda 封裝。
CUDA Python 工作流程
由於 Python 是一種解譯語言,必須先設法將裝置程式碼編譯成 PTX,然後擷取將要在應用程式中呼叫的函數。相比之下理解 CUDA Python 不是最重要的,但是需要瞭解 Parallel Thread Execution(PTX)是一種低階虛擬機器和指令集架構(instruction set architecture,ISA)。以字串形式建構裝置程式碼,並使用 CUDA C++ 執行階段編譯函式庫 NVRTC 進行編譯。使用 NVIDIA 驅動程式 API,在 GPU 上手動建立 CUDA 脈絡及所有的必要資源,然後啟動已編譯 CUDA C++ 程式碼,並從 GPU 擷取結果。現在,您已經大致瞭解,接著將進入平行程式設計的常用範例:SAXPY。
首先,從 CUDA Python 套件匯入驅動程式 API 和 NVRTC 模組。在此範例中,將資料從主機複製到裝置。需要 NumPy 在主機上儲存資料。
import cuda_driver as cuda # Subject to change before release import nvrtc # Subject to change before release import numpy as np
錯誤檢查是程式碼開發的基本最佳做法,且已提供了程式碼範例。為求精簡,省略了範例中的錯誤檢查。在未來版本中,可能會使用 Python 物件模型自動引發例外。
def ASSERT_DRV(err):
if isinstance(err, cuda.CUresult):
if err != cuda.CUresult.CUDA_SUCCESS:
raise RuntimeError("Cuda Error: {}".format(err))
elif isinstance(err, nvrtc.nvrtcResult):
if err != nvrtc.nvrtcResult.NVRTC_SUCCESS:
raise RuntimeError("Nvrtc Error: {}".format(err))
else:
raise RuntimeError("Unknown error type: {}".format(err))
常見之做法是在轉譯單位的頂部附近編寫 CUDA 核心,所以接下來將編寫此部分。使用三引號包住整個核心,以形成字串。之後使用 NVRTC 編譯字串。這是 CUDA Python 中唯一需要理解 CUDA C++ 的部分。若需要更多資訊,請參閱 An Even Easier Introduction to CUDA。
saxpy = """\
extern "C" __global__
void saxpy(float a, float *x, float *y, float *out, size_t n)
{
size_t tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < n) {
out[tid] = a * x[tid] + y[tid];
}
}
"""
繼續將核心編譯成 PTX。請記住,這是使用 NVRTC,在執行階段執行。NVRTC 有三個基本步驟:
- 從字串建立程式。
- 編譯程式。
- 從已編譯程式中擷取 PTX。
在以下程式碼範例中,針對運算能力 75 或 Turing 架構進行編譯,並啟用 FMAD。如果編譯失敗,請使用 nvrtcGetProgramLog 擷取編譯紀錄,以取得其他資訊。
# Create program err, prog = nvrtc.nvrtcCreateProgram(str.encode(saxpy), b"saxpy.cu", 0, [], []) # Compile program opts = [b"--fmad=false", b"--gpu-architecture=compute_75"] err, = nvrtc.nvrtcCompileProgram(prog, 2, opts) # Get PTX from compilation err, ptxSize = nvrtc.nvrtcGetPTXSize(prog) ptx = b" " * ptxSize err, = nvrtc.nvrtcGetPTX(prog, ptx)
在使用 PTX 或在 GPU 上執行任何工作之前,必須先建立 CUDA 脈絡。CUDA 脈絡類似於裝置的主機處理序。在以下程式碼範例中,將驅動程式 API 初始化,以存取 NVIDIA 驅動程式和 GPU。其次,將運算裝置 0 的控點傳遞至 cuCtxCreate,以指定該 GPU 建立脈絡。在建立脈絡之後,可以繼續使用 NVRTC 編譯 CUDA 核心。
# Initialize CUDA Driver API
err, = cuda.cuInit(0)
# Retrieve handle for device 0
err, cuDevice = cuda.cuDeviceGet(0)
# Create context
err, context = cuda.cuCtxCreate(0, cuDevice)
在裝置 0 上建立 CUDA 脈絡之後,將先前產生的 PTX 載入至模組。模組類似於裝置的動態載入函式庫。在載入至模組之後,使用 cuModuleGetFunction 擷取特定核心。多個核心常駐於 PTX 中不是罕見的情形。
# Load PTX as module data and retrieve function ptx = np.char.array(ptx) err, module = cuda.cuModuleLoadData(ptx.ctypes.get_data()) err, kernel = cuda.cuModuleGetFunction(module, b"saxpy")
之後,準備所有資料及傳輸至 GPU。為了提高應用程式效能,可以在裝置上輸入資料,以省略資料傳輸。為了能完整理解,此範例將示範如何將資料輸入與輸出裝置。
NUM_THREADS = 512 # Threads per block NUM_BLOCKS = 32768 # Blocks per grid a = np.array([2.0], dtype=np.float32) n = np.array(NUM_THREADS * NUM_BLOCKS, dtype=np.uint32) bufferSize = n * a.itemsize hX = np.random.rand(n).astype(dtype=np.float32) hY = np.random.rand(n).astype(dtype=np.float32) hOut = np.zeros(n).astype(dtype=np.float32)
為 SAXPY 轉換裝置建立輸入資料 a、x、y 之後必須分配資源,以使用 cuMemAlloc 儲存資料。想要在運算與資料移動之間允許更多重疊時,請使用非同步函式 cuMemcpyHtoDAsync。它會在命令執行後,立即將控制權交還給 CPU。
Python 沒有自然的指標概念,但是 cuMemcpyHtoDAsync 需要 void*。因此,XX.ctypes.get_data 會擷取與 XX 有關的指標值。
err, dXclass = cuda.cuMemAlloc(bufferSize) err, dYclass = cuda.cuMemAlloc(bufferSize) err, dOutclass = cuda.cuMemAlloc(bufferSize) err, stream = cuda.cuStreamCreate(0) err, = cuda.cuMemcpyHtoDAsync( dXclass, hX.ctypes.get_data(), bufferSize, stream ) err, = cuda.cuMemcpyHtoDAsync( dYclass, hY.ctypes.get_data(), bufferSize, stream )
在完成資料準備和資源分配之後,即可啟動核心。想要將裝置上的資料位置傳遞至核心執行配置時,必須擷取裝置指標。在以下程式碼範例中,int(dXclass) 會重試 dXclass 的指標值,即 CUdeviceptr,並使用 np.array 分配記憶體大小,以儲存該值。
如同 cuMemcpyHtoDAsync,cuLaunchKernel 在引數清單中需要 void**。在先前的程式碼範例中,建立 void** 的方式是取得各個引數的 void* 值,並將其放入各自的連續記憶體中。
# The following code example is not intuitive # Subject to change in a future release dX = np.array([int(dXclass)], dtype=np.uint64) dY = np.array([int(dYclass)], dtype=np.uint64) dOut = np.array([int(dOutclass)], dtype=np.uint64) args = [a, dX, dY, dOut, n] args = np.array([arg.ctypes.get_data() for arg in args], dtype=np.uint64)
現在可以啟動核心:
err, = cuda.cuLaunchKernel( kernel, NUM_BLOCKS, # grid x dim 1, # grid y dim 1, # grid z dim NUM_THREADS, # block x dim 1, # block y dim 1, # block z dim 0, # dynamic shared memory stream, # stream args.ctypes.get_data(), # kernel arguments 0, # extra (ignore) ) err, = cuda.cuMemcpyDtoHAsync( hOut.ctypes.get_data(), dOutclass, bufferSize, stream ) err, = cuda.cuStreamSynchronize(stream)
cuLaunchKernel 函式取得已編譯的模組核心和執行配置參數。在與資料傳輸相同的資料流中啟動裝置程式碼。可以確保僅會在完成資料傳輸後,執行核心運算,因為資料流中的所有 API 呼叫及核心啟動都已經序列化。在將資料傳回主機的呼叫之後,使用 cuStreamSynchronize 暫停 CPU 執行,直至完成指定資料流中的所有運算。
# Assert values are same after running kernel
hZ = a * hX + hY
if not np.allclose(hOut, hZ):
raise ValueError("Error outside tolerance for host-device vectors")
執行資料驗證以確保正確性,並透過記憶體清理完成程式碼。
err, = cuda.cuStreamDestroy(stream) err, = cuda.cuMemFree(dXclass) err, = cuda.cuMemFree(dYclass) err, = cuda.cuMemFree(dOutclass) err, = cuda.cuModuleUnload(module) err, = cuda.cuCtxDestroy(context)
效能
效能是在應用程式中,以 GPU 為目標的主要驅動力。因此,相較於 C++ 版本,上述程式碼如何呢?如表 1 所示,結果幾乎相同。NVIDIA NSight Systems 是使用於擷取核心效能,以及 CUDA Events 是使用於應用程式效能。
使用以下命令剖析應用程式:
nsys profile -s none -t cuda --stats=true <executable>
C++
Python
核心執行
352µs
352µs
應用程式執行
1076ms
1080ms
CUDA Python 與用於 CUDA 應用程式的互動式核心剖析工具 NVIDIA Nsight Compute 也相容。它讓您可以詳細瞭解核心效能。這在嘗試將效能最大化時很實用(圖 1)。
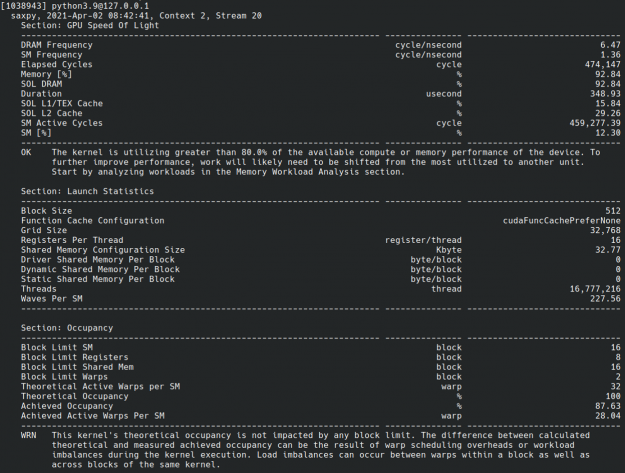
CUDA Python 入門
CUDA Python 即將推出,並隨附 API 的詳細說明、安裝注意事項、新功能和範例。若需要更多資訊,請參閱下列文章:
- Nsight Systems Exposes New GPU Optimization Opportunities
- Using Nsight Compute to Inspect your Kernels
NVIDIA 深度學習機構(DLI)也提供 CUDA Python 等多種平行運算實作課程。透過實作讓開發者更容易理解其概念,以實際程式編寫加強平行運算的活用,利用 GPU 加速你的應用程式。查看課程,請造訪 DLI 官方網站。