現代商業智慧領域的興起造就出多項元件,以支援提供企業所需資訊得備有的各種分析功能。
或許商業智慧運動最根本的元件,便是由Tableau、Qlik、Birst、Domo 及 Periscope 等業者提供的眾多傳統前端或視覺化應用程式,基本上它們都有著共同的功能,也就是讓試算表看起來更美觀。部分業者讓自家應用程式的實用性方面與眾不同,而獲得空前勝利。
在商業智慧領域裡另一個不可或缺的要角即是資料庫,同樣有像是 Redshift、Impala、Vertica、Netezza 等表現亮眼的業者,其中某些資料庫是擁有完整功能、相當於紀錄系統的解決方案,而其它資料庫則是著重於串流等特定功能上,同樣有著優異表現。
最後商業智慧與資料庫領域對機器學習、深度學習及人工智慧等技術產生出莫大的興趣,這三個領域也出現爆炸性的發展,誕生出更先進的分析工具。這個市場裡有著 Google、Facebook、Amazon、Microsoft、IBM、百度、Tesla 這些大咖業者,再加上一堆表現出色的新創公司,例如 Sentient、Ayasdi、Bonsai 和 H2O.ai。
一套成功又具備完整功能的商業智慧系統該是面面俱到、各項元素順利運作,但問題是沒有哪套系統是真正順利運作的,原因在於資料成長的速度飛快。
這些秉持著以 CPU 為中心陳腐世界觀的系統,緩慢困難地運轉著,它們在運算上無力滿足海量位元組經濟規模要求的事項,進行查詢、渲染或從資料中學習。
不過總有解決的辦法。答案就在深度學習圈早就開始採用的 GPUs。
在 GPUs 的加持下,系統的運算效能突飛猛進,這可以解釋全球五百大高效能運算名單上為何有這麼多的超級電腦使用 NVIDIA GPUs。因為使用 GPUs 來解決數學計算問題的數量,比起使用傳統 CPU 來處理的數量,還真是多出不少。
不只是深度學習,資料庫和視覺化亦受惠於 GPUs。以 GPUs 為基礎的系統能處理如此大量工作所需的速度和規模,並且提供所需的功能性。

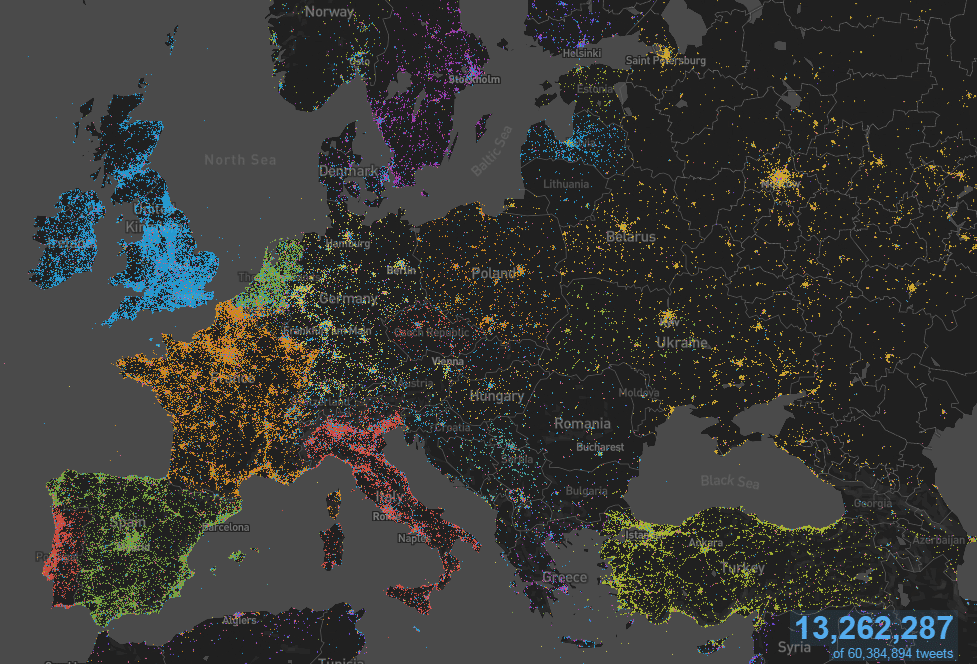
MapD 採用 GPU 運算技術在幾毫秒的時間內,
對數十億筆的紀錄資料提供 SQL
查詢服務和沉浸式視覺分析工具。
對於 GPUs 與整合式分析該瞭解的事情
首先,GPUs 提供超高記憶體頻寬,這裡指的是跨多個 GPU 上每秒 TB(兆位元組)級別的資料量。資料庫查詢作業通常是記憶體頻寬或輸入/輸出限制(I/O bound) 程序,這一點相當重要。 基於記憶體需求量,GPUs 能在較少時間內掃描更多資料,也就更快獲得結果。
在這個背景下,知名資料庫權威 Mark Litwintschik 發現一個採用單顆 GPU 的伺服器在處理11億列資料量時,速度較 Redshift 大型叢集快上74倍。不是快上 74%,而是快上74倍。以 Postgres SQL 伺服器來比較好了,速度快上 3,500 倍,可謂是幾毫秒跟幾十分鐘之間的差距。
工作集隨著資料量大量增加,這個差距就變得十分明顯。數百萬列的資料組過去是天文數字,如今只是滄海一粟。現在的資料組隨便都是幾億到幾十億不等的數量。
第二,GPUs 不只在速度方面有優勢,還能針對特定任務和查詢活動優化其它系統。GPUs 在處理圖形方面表現也十分搶眼。其實 GPUs 本來的渲染管線最適合用在資料視覺化作業上。
這一點顯示出 GPU 不只能製作出更好看的儀表板,還能創作出回應更迅速、處理速度更快的儀表板。理由在於要是你能在進行圖形渲染的同一晶片上執行查詢作業,就不用帶著資料到處跑,只運算幾百萬列資料還算不上是問題,但要是處理十億列或數十億列資料,那可就讓人頭痛囉。
最後,GPUs 提供超級電腦級的運算效能。GPUs 在機器學習與深度學習排行榜上佔有一席之地,矩陣相乘方面有著優異表現。再說一次,能在同一晶片上進行查詢和機器學習活動,便能以超高效率將訓練和推論所需的資料投入機器學習演算法。

MapD 消化超過十億列的計程車數據基準
如何在組織內推行 GPUs
一套整合 GPU 硬體和經過 GPU 調校的資料庫、經過 GPU 調校的前端/視覺化層,以及經過 GPU 調校之機器學習層的系統,會為組織帶來實質效益。
不過只升級一個元件,誕生出的連結關係最為薄弱。投入 CPU 視覺化前端的 GPU 資料庫有著高速的處理能力,但其速度卻仍比不過投入 GPU 視覺化前端的 GPU 資料庫。
任何可能的組合都有著相同問題,CPU 連結關係皆薄弱不振。
最佳的系統處處得益於 GPU 硬體和經過 GPU 調校的軟體。
速度、視覺化、先進的分析工具 — 都是 GPU 導向。使用老舊運算平台設計的硬體或軟體,無疑就是選擇等待、降低取樣、在橫向拓展方面付出過多,甚至在我們所居住這個具有變通性的世界裡也是如此。
目前市面上已經出現整合式系統,也開始納入其它獲益於 GPUs 的重大任務或子任務。整合式 GPU 堆疊對於商業智慧、資訊科技、資料科學及企業的其它領域有著莫大的意義。這正是 MapD 認為如今已邁入 GPU 時代的緣故,我們樂於成為推動革命的一份子。