本文章是 RAPIDS 生態系統系列文章的第五篇。此系列探討 RAPIDS 的各個層面,讓使用者可以解決 ETL(Extract、Transform、Load,擷取、轉換、載入)問題、建構機器學習和深度學習模型、探索各種圖表、處理訊號和系統紀錄,或透過 BlazingSQL 使用 SQL 語言處理資料。
機器學習一詞出現至今,已超過 60 年。從當時起,它就在電腦科學、統計學與計量經濟學的交會處佔有重要地位。不難想像,現在幾乎每一個擁有智慧型手機的人,每天(甚至每分鐘)都在使用某種形式的機器學習。在上網時,我們會根據偏好建立模型,所以會顯示出更多相關產品,而在玩遊戲時,對手變得更聰明,或智慧型手機可以辨識我們的臉孔,並解鎖手機。
利用 RAPIDS cuML 加快機器學習工作流程
因此,當 RAPIDS 於 2018 年底推出時,已預備了大量的 GPU 加速機器學習演算法,可以解決現今互聯世界中的一些根本問題。之後,cuML(CUDA Machine Learning 的縮寫)提供之演算法的選擇增加了,且其中許多演算法的效能已達到極致的水準。同時能維持熟悉與符合邏輯的 scikit-learn API!
在前幾篇文章中,我們示範了其他領域:
- 在第一篇文章 python pandas 教學中,我們介紹了可以在 NVIDIA GPU 上處理大量資料的 RAPIDS DataFrame 框架:cuDF。
- 第二篇文章是比較 cuDF DataFrame 與 pandas DataFrame 之間的相似性。
- 在第三篇文章使用 SQL 查詢資料中,我們介紹在 GPU 上執行的 SQL 引擎:BlazingSQL。
- 在第四篇文章利用 Dask 進行資料處理中,我們介紹可以協助在 GPU 上執行分散式工作負載的 Python 分散式框架。
在本篇教學中,我們將介紹與示範 RAPIDS cuML 最常見的功能。
使用 cuML 有助於加快機器學習模型訓練速度並與 cuDF 完美整合。由於此緊密的整合,大幅縮短了估計模型需要的端對端時間。進而使我們能使用互動方式,設計特徵和測試新模型及/或最佳化超參數,造就出界限更分明與更準確的模型,並能更頻繁地重新訓練模型。
為了協助熟悉使用 cuML,我們提供了便利的 cuML 備忘單可供下載,以及包含 cuML 示範之所有現有功能的互動式 notebook。
使用 GPU 建立統計模型
總言之,估計統計模型是根據特徵(自變數)和基準真相(或因變數),找出損失函數的最小值或報酬函數的最大值。有許多演算法能協助找出方程式的根,其中一些演算法可以回溯至 17 世紀(請參閱 Newton-Rhapson 演算法),但是所有演算法都有一個共同點:最終,所有的特徵和基準真相都必須由數值表示。
實際上,無論是建立傳統的機器學習模型、嘗試估計最新與最先進的深度學習模型,或處理影像,電腦都會處理大型數字矩陣,並套用一些演算法。具有數千個核心的 GPU 是專為特定用途而打造:將大型矩陣的處理平行化。例如,我們玩遊戲時的畫格渲染速度非常快速,幾乎感覺不到畫面上有任何延遲、無須一天完成套用至影像的濾鏡,或大幅加快估計模型的過程。
GPU 首次進入機器學習領域,加快估計深度學習模型的速度,因為這些模型的資料量和大小需要非常大量的運算。但是,雖然深度學習模型可以解決一些複雜的模型建立問題,對於已具有完善解決方案的其他簡單問題而言通常顯得多餘。
因此,如果資料集較大,而我們希望能將讀取資料到完成迴歸或分類模型估計的時間,從數小時或數天縮短成數分鐘時,RAPIDS 是最適合的工具。
迴歸和分類 – 機器學習的骨幹
迴歸和分類問題密切相關,主要的差異在於推導損失函數的方式。在迴歸模型中,通常想要最小化模型預測值與目標之間的距離(或平方距離),而分類模型的目標,則是最小化分類錯誤觀察值的數量。為了進一步證明迴歸或分類的基礎數學模型幾乎相同,我們擁有一系列模型可以解決兩者,例如支援向量機或整體模型(例如隨機森林或 XGBoost)。
cuML 套件擁有完整的模型組合,可以解決迴歸或分類問題。幾乎所有模型都是採用完全相同的 API 呼叫,可以簡化不同方法的測試。假設需要估計線性迴歸,然後嘗試脊迴歸或套索迴歸:我們僅需要變更建立的物件。
您可以使用兩行程式碼,估計線性迴歸模型:
model = cuml.LinearRegression(fit_intercept=True, normalize=True) model.fit(X_train, y_train).predict(X_test)
估計套索迴歸(提醒一下,它提供係數 L1 正則化)必須變更物件:
model = cuml.Lasso(fit_intercept=False, normalize=True) model.fit(X_train, y_train).predict(X_test)
在嘗試估計分類模型時,可以發現類似的模式:估計邏輯迴歸的方式如下:
model = cuml.LogisticRegression(fit_intercept=True) model.fit(X_train, y_train).predict(X_test)
不同於迴歸模型,某些已估計分類模型也可以輸出屬於特定類別的機率。
model.predict_proba(X_test)
請參考 cuML 備忘單,以進一步探索 RAPIDS 的迴歸和分類模型,或使用 cuML notebook 進行嘗試。
在資料中尋找模式
很多時候,不容易在真實世界之情境下產生的資料集中取得目標變數或標籤。用於機器學習的標記資料集,甚至已成為獨立的商業模式。但是,資料集群化是沒有教師之統計模型建立或非監督式模型建立(不需要基準真相,而是在資料中尋找模式)的範例。
k 平均是最簡單,卻強大的分割模型之一。k 平均可以根據觀察值及其特徵,找出最大化的集群同質性(相同集群中的觀察值相似度),同時最大化集群間之異質性(相異性)的集群。雖然 k 平均演算法非常有效率,且可擴充至相對較大的資料集,但是使用 RAPIDS 估計 k 平均模型可以進一步提升效能。
k_means = cuml.KMeans(n_clusters=4, n_init=3) k_means.fit_transform(X_train)
k 平均的缺點之一是必須明確指出,我們希望在資料中看到的集群數量。DBSCAN 也可以在 cuML 中使用,且無此類要求。
dbscan = cuml.DBSCAN(eps=0.5, min_samples=10) dbscan.fit_predict(X_train)
DBSCAN 是以密度為基礎的集群化模型。不同於 k 平均,DBSCAN 可以讓一些點不會集群化,而能有效率地找出一些不符合任何模式的離群值。
處理高維度資料
在許多現實生活現象方面,我們無法收集足夠的資料,估計具統計顯著性的機器學習模型,或現象的性質,使資料具有極高的維度和稀疏性。例如,某些罕見疾病可以有許多患者特徵的描述,但是,可以供我們收集資料的觀察患者人數較少,使我們實際上陷入統計僵局。另一方面,我們可能有數十億筆紀錄,但是特徵空間的大小可能是數億,而使估計模型變得不切實際。
維度縮減是減少特徵數量,僅保留與目標高度相關或可以解釋大部分目標變異數之特徵的技術之一。主成分分析(Principal Component Analysis,PCA)是最古老的技術之一,可以將高維度特徵空間投射在正交超平面上,以確保每一個特徵彼此獨立,然後僅保留一些可以解釋大部分目標變異數的特徵。cuML 具有快速的 PCA 建置,我們可以使用一行程式碼進行估計。
pca = cuml.PCA(n_components=2)
上方的程式碼取得一個資料集,且僅擷取可以輕易繪製的前兩個主成分。下方的範例是從使用 cuML 建立的資料集中,擷取 2 個主成分。
X, y = cuml.make_blobs(
n_samples=1000
, centers=4
, n_features=50
, cluster_std=[1.0, 5.0, 10.0, 0.5]
, random_state=np.random.randint(1e9)
)
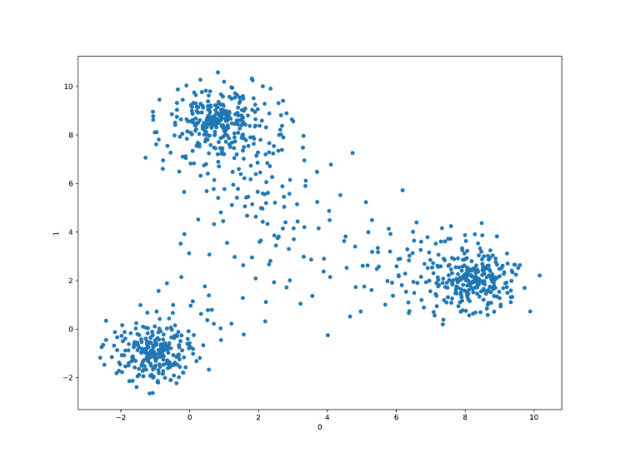
我們有 50 個特徵、1000 個觀察值以及 4 個集群。執行 PCA 以擷取前兩個主成分及繪製結果之後,呈現出下圖。
因此,我們可以僅使用 2 個,而不是 50 個特徵,且可能仍可建立良好的模型。當然,可以找出四個集群的模型不多,但是,其中 3 個之間的分離十分明顯。
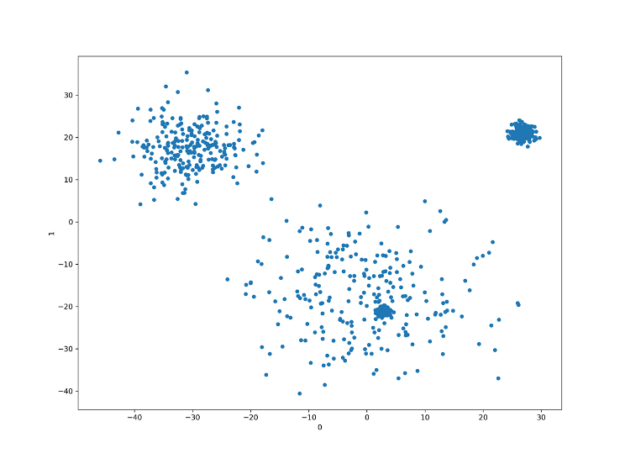
umap = cuml.UMAP(n_neighbors=10, n_components=2) tsne = cuml.TSNE(n_components=2, perplexity=500, learning_rate=200)
UMAP 和 t-SNE 都產生了比 PCA 更好的分離集群,UMAP 是最終贏家,能以接近理想的方式,擷取線性可分離的四個點集群。

t-SNE 產生線性可分離集群,但是與 PCA 一樣,似乎缺少其中之一。