
NVIDIA 視覺編程介面(Vision Programming Interface,VPI)是提供電腦視覺和影像處理演算法集合的軟體函式庫。這些演算法的建置,可在 NVIDIA Jetson 嵌入式電腦或獨立 GPU 提供的不同硬體引擎上獲得加速。
本文說明了如何在 Jetson 產品系列上,執行抑制時序雜訊(Temporal Noise Reduction,TNR)範例應用程式。若需要更多資訊,請參閱 VPI – Vision Programming Interface 文件。
在 Jetson 裝置上設定 VPI
在透過 SDK Manager 設定 Jetson 裝置時,請務必勾選 Jetson SDK 元件方塊。VPI 將會於刷新裝置時完成安裝。若需要更多與安裝有關的資訊,請參閱 NVIDIA SDK Manager。
在完成安裝之後,可以在以下路徑找到 VPI:
/opt/nvidia/vpi1/
想要驗證是否已正確設定環境時,請將 VPI 範例應用程式複製到主目錄中,然後建構 TNR 範例。
$ vpi1_install_samples.sh $HOME $ cd $HOME/NVIDIA_VPI–samples/09-tnr $ cmake . $ make
在執行獨立 GPU 的 x86 機器上也可以支援 VPI。若需要更多資訊,請參閱 VPI – Vision Programming Interface 文件中的安裝。
抑制時序雜訊(TNR)範例應用程式
VPI 提供的電腦視覺演算法集合是利用多個後端,有效率地使用裝置的可用運算資源。TNR 是在 Jetson 裝置上執行電腦視覺應用程式,常用的雜訊抑制方法。本文是使用 TNR 範例應用程式,示範如何使用 VPI 中的一些主要概念和元件,建置自己的應用程式。
本文涵蓋下列主題:
- 建立必要的元件,以建構 VPI 工作流程
- 理解與 OpenCV 的互通性如何運作
- 將處理任務提交至資料流
- 將資料流中的任務同步
- 鎖定影像緩衝區,以便從 CPU 存取
在以下路徑中可以找到 TNR 範例:
$HOME/NVIDIA_VPI–samples/09-tnr/main.cpp
欲深入瞭解範例應用程式和演算法,請參閱下列資源:
演算法版本和後端支援
硬體引擎在 VPI 中稱為後端。這些後端可以利用 Jetson 裝置固有的系統層級平行性,卸載可平行化處理階段,並加快應用程式。後端包括 CPU、CUDA (GPU)、PVA 和 VIC。特定後端引擎之確切可用性,是取決於部署應用程式的 Jetson 平台。欲深入瞭解特定平台上的可用演算法、後端支援和後端可用性,請參閱演算法。
目前 VPI 可為 TNR 提供兩種不同的建置,分別適合不同的場景和要求。這些版本是採用雙邊濾波的組合將平坦區域平順化,同時保留邊緣,以及使用時序無限脈衝響應(infinite impulse response,IIR)濾波搭配動態偵測器,處理畫格中的時序雜訊。
- VPI_TNR_V2 – 此版本提供比 VPI_TNR_V3 弱的雜訊抑制,以及一定程度的可配置性,亦即可調整光照條件,以更適合特定場景。此版本的運算需求較低,而轉化成速度。它適合執行時序比抑制雜訊品質更重要的使用案例。
- VPI_TNR_V3 – 適合需要更佳之抑制雜訊品質的使用案例。此版本的運算需求比 VPI_TNR_V2 高。此外,可以進一步延伸可配置性。建議使用於具有挑戰性的低光源場景。
- VPI_TNR_DEFAULT – 您可以使用預設值,選擇特定後端支援的最高雜訊抑制強度版本,而不是指定確切的版本。
在判斷哪一個演算法版本適合您的使用案例時,應同時考量不同的後端和裝置是否支援該版本。下表列出 TNR 支援。
| 後端/裝置 | Jetson Nano 系列 | Jetson TX2 系列 | Jetson Xavier 系列 |
| CUDA (GPU) | VPI_TNR_V3 | VPI_TNR_V3 | VPI_TNR_V3 |
| VIC | VPI_TNR_V2 | VPI_TNR_V2 | VPI_TNR_V2 和 VPI_TNR_V3 |
| CPU | 尚未支援 | 尚未支援 | 尚未支援 |
| PVA | 無後端 | 無後端 | 不適用 |
VPI_TNR_V2 和 VPI_TNR_V3 都可以支援調整,讓您能明確設定想要擷取之場景的光照條件。對於在以高增益擷取低光源場景或資料流的情況而言很重要,因為其中可能包含較高的雜訊位準,因此需要程度較高的雜訊抑制。
較高的強度可能會影響畫格紋理區域中的細節數量,而使其平順化。另一個副作用是會在具有快速移動物件的場景中出現殘影。支援的場景光照條件會因類型(室內、室外)和強度(低、中、高)而異,如下表所列。
| 場景 | 說明 |
| VPI_TNR_PRESET_OUTDOOR_LOW_LIGHT | 光照條件不佳導致高雜訊的室外場景。 |
| VPI_TNR_PRESET_OUTDOOR_MEDIUM_LIGHT | 光照充足,但是仍具有一些雜訊的室外場景。 |
| VPI_TNR_PRESET_OUTDOOR_HIGH_LIGHT | 光照條件良好,且雜訊較少的室外場景。 |
| VPI_TNR_PRESET_INDOOR_LOW_LIGHT | 光照條件不佳的室內場景。 |
| VPI_TNR_PRESET_INDOOR_MEDIUM_LIGHT | 光照充足的室內場景。 |
| VPI_TNR_PRESET_INDOOR_HIGH_LIGHT | 光照良好的室內場景。 |
預設不同的版本和相關的光照條件後,即可根據使用案例的確切情況,調整 TNR 演算法。您可以透過所謂的強度因數進行進一步的自訂。它是範圍在 0 到 1 之間的浮動參數,值越大,對應的去雜訊強度越高。
VPI 應用程式
VPI 的主要特色為可以有效管理和協調在不同後端之間執行應用程式需要的資源。透過 VPI,可以避免在處理階段之間浪費大量的記憶體複本。VPI 為了高效率之記憶體管理而實施的另一個機制,是在介面進行記憶體包裝。
利用 VPI 的所有記憶體管理功能,是取決於程式碼的結構。最佳做法是將程式碼視為三階段工作流程:
- 初始化
- 處理迴圈
- 清理
大部分的記憶體應在初始化階段進行分配。對於嵌入式應用程式在可用資源有限之裝置上運作的情況而言,特別重要。此外,可以更有效率與更仔細地管理記憶體,以避免可能會導致記憶體流失。
在 VPI 中的良好做法,是指定使用部分記憶體的後端。值得注意的是,僅將 VPI 物件訂閱至需要的後端集合,可以確保管道在這些後端之間流動時,獲得最有效率的記憶體路徑。
處理迴圈是執行處理管道的位置。假設應用程式迭代具有數百個各別畫格的視訊檔案。主迴圈主要負責針對像素資訊執行必要的轉換,以達成特定電腦視覺任務的理想結果。
最後,清理階段是針對任務執行期間使用的資源,進行所有必要的釋放和重新分配。遵循此範式,讓 VPI 可以使用最有效率的處理管道,並協助您遵守良好的編碼做法。
與 OpenCV 介接
VPI 與 OpenCV 的互通性為此函式庫的獨特功能。如果您熟悉 OpenCV,即可輕鬆地將 VPI 與您的工作流程整合,或延伸現有的資料工作中,以充分利用 VPI 提供的硬體加速。
TNR 範例是透過以下公用程式函式,將使用 OpenCV 擷取之輸入視訊畫格包裝成 VPI 影像物件的方式,示範此操作。
69 // Utility function to wrap a cv::Mat into a VPIImage 70 static VPIImage ToVPIImage(VPIImage image, const cv::Mat &frame) 71 { 72 if (image == nullptr) 73 { 74 // Create a VPIImage that wraps the frame 75 CHECK_STATUS(vpiImageCreateOpenCVMatWrapper(frame, 0, &image)); 76 } 77 else 78 { 79 // reuse existing VPIImage wrapper to wrap the new frame. 80 CHECK_STATUS(vpiImageSetWrappedOpenCVMat(image, frame)); 81 } 82 return image; 83 }
首先深入探討先前提到的函式。這是為了將 OpenCV 矩陣(cv::Mat)物件包裝成 VPI 影像物件(VPIImage)。在進行脈絡化時,基本上 VPI 影像是可以使用寬度、高度和格式描述的任何 2D 資料結構。雖然將影像資料視為 VPIImage 物件很直觀,但是,它的用途也可以延伸至其他類型的資料,例如 2D 向量場和熱圖。
公用程式包裝函式調用另外兩個與 VPI OpenCVInterop.hpp 模組有關的函式,其目的是提供實用的基礎架構,將以 OpenCV 為基礎的程式碼與 VPI 整合。
- vpiImageCreateOpenCVMatWrapper – 超載函式,以兩種不同的方式,將
cv:Mat物件包裝成VPIImage。第一種是嘗試直接根據輸入類型(遵循特定規則)推論格式,第二種則是以顯式格式做為引數之一。 - vpiImageSetWrappedOpenCVMat – 重複使用針對特定
cv::Mat物件而定義的包裝函式,以包裝新的傳入cv::Mat物件。此處的重點是直接避免因建立包裝函式而導致記憶體分配,因此更有效率。傳入的 cv::Mat 物件特性(格式和尺寸),必須與建立時使用的原始物件相同。
建立資料流
主要函式記錄與建立 VPI 工作流程以完成工作有關的步驟。工作流程的定義簡單明瞭,且相當直觀。在 VPI 中,工作流程是流過不同處理階段之一或多個資料流的組合。
圖 1 是以概略方式呈現管道及其構件(資料流、緩衝區、演算法等等)。為了能更簡單,已省略了某些元件。
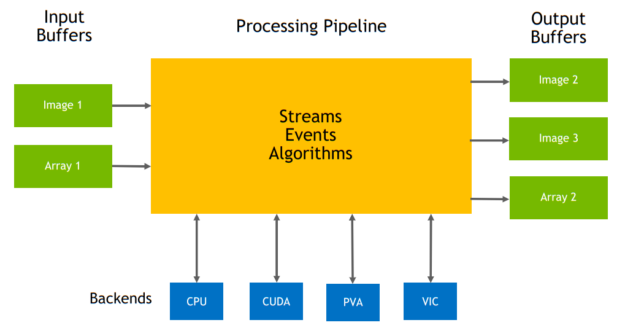
資料流之目的是強制執行資料,以完成特定之電腦視覺任務時必須經歷的一連串步驟。這些步驟可能包括資料預處理或後處理,或甚至是成熟的演算法,例如 TNR。圖 2 為 VPIStream 物件的範例。
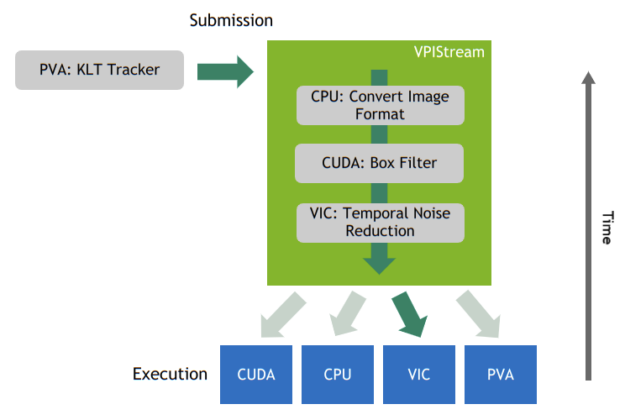
VPI 可適應各種工作流程複雜性。您可以使用單一資料流建置簡單的工作流程,或使用多個平行資料流進行更複雜的建置,將不同階段卸載至不同的運算後端。這是 API 的強大功能,因為它可以進一步控制 Jetson 裝置提供的系統層級平行性。
以下程式碼範例,是示範如何在 TNR 範例中建立資料流。
143 VPIStream stream; 144 // PVA backend doesn't have currently Convert Image Format algorithm. 145 // Use the CUDA backend to do that. 146 CHECK_STATUS(vpiStreamCreate(VPI_BACKEND_CUDA | backend, &stream));
後端選擇傳遞至資料流。這是選擇性步驟。使用零值將啟用所有可用的後端。但是,建議之做法是指派特定的後端集合,以有助於最佳化記憶體分配。
TNR 有效負載
基本上,有效負載是工作流程執行期間需要的臨時資源。例如,有效負載可能是中間記憶體緩衝區,儲存在資料流之後續階段之間進行交換的資料。許多演算法(包括 TNR)都要求明確使用下列方式建立有效負載。
172 // Create a TNR payload configured to process NV12 173 // frames under outdoor low-light scenarios. 174 VPIPayload tnr; 175 CHECK_STATUS(vpiCreateTemporalNoiseReduction(backend, w, h, VPI_IMAGE_FORMAT_NV12_ER, VPI_TNR_DEFAULT, 176 VPI_TNR_PRESET_INDOOR_LOW_LIGHT, 1, &tnr));
為 TNR 有效負載提供下列引數:
- 影像尺寸(寬度和高度)
- 後端
- 影像資料的格式(目前僅支援 NV12)
- TNR 演算法版本
- 光照條件
- 雜訊抑制強度
- 演算法有效負載參考
最終,函式會建立有效負載,並將其繫結至指派的後端。
影像緩衝區
除資料流和建立有效負載外,也必須建立 VPI 演算法需要的影像緩衝區。在 TNR 中是使用雙邊與 IIR 濾波器的組合,所以需要三個不同的緩衝區:即目前和先前的影像輸入與影像輸出。
建立影像緩衝區的方式如下:
167 VPIImage imgPrevious, imgCurrent, imgOutput; 168 CHECK_STATUS(vpiImageCreate(w, h,VPI_IMAGE_FORMAT_NV12_ER, 0, &imgPrevious)); 169 CHECK_STATUS(vpiImageCreate(w, h,VPI_IMAGE_FORMAT_NV12_ER, 0, &imgCurrent)); 170 CHECK_STATUS(vpiImageCreate(w, h,VPI_IMAGE_FORMAT_NV12_ER, 0, &imgOutput));
將會建立具有下列指定特性的空緩衝區:
- 影像尺寸(寬度和高度)
- 格式(根據演算法要求)
- 影像旗標(目前用於指派後端)
- 回傳已建立影像之
VPIImage控點的變數指標
資料流處理
在構件準備就緒之後,即可進入執行雜訊抑制演算法的主要處理迴圈。在 TNR 範例上,迴圈會迭代視訊檔案中的個別畫格,並執行必要的順序步驟,以達成理想的結果。
從視訊收集畫格時,第一步是使用先前提到的公用程式函式,包裝成 VPIImage 物件。
186 frameBGR = ToVPIImage(frameBGR, cvFrame);
在完成包裝後,VPI 已可操作 VPIImage 物件中的像素資料。由於 TNR 要求畫格採用 NV12 格式,因此需要轉換步驟。
188 // First convert it to NV12 189 CHECK_STATUS(vpiSubmitConvertImageFormat(stream,VPI_BACKEND_CUDA, frameBGR, imgCurrent, NULL));
在此階段,轉換影像之特定任務與先前執行個體化的資料流有關。此外,該任務是設定為在 GPU 上執行。輸入畫格的影像緩衝區,以及從 cv::Mat 物件包裝的資料,即適用於此目的。
在完成格式轉換之後,即可將輸入緩衝區傳遞至 TNR 演算法進行處理。
191 // Apply TNR 192 // For first frame, you must pass nullptr as the previous frame, this resets the internal 193 // state. 194 CHECK_STATUS(vpiSubmitTemporalNoiseReduction(stream, 0, tnr, curFrame == 1 ? nullptr : imgPrevious, 195 imgCurrent, imgOutput)); 196
想要調用 TNR 演算法時,請設定下列參數:
- 與演算法有關的資料流
- 後端
- 演算法有效負載,如同先前執行個體化的有效負載
- 影像緩衝區:先前和目前的輸入與輸出
在第一次迭代(curFrame == 1),緩衝區上無有效的先前影像,且是傳遞空指標。針對後續迭代,會視情況填入緩衝區。在執行 TNR 演算法之後,可以將輸出緩衝區,從 NV12 轉換至先前的 BGR 格式。
197 // Convert output back to BGR 198 CHECK_STATUS(vpiSubmitConvertImageFormat(stream,VPI_BACKEND_CUDA, imgOutput, frameBGR, NULL));
此時最重要的是 VPI 針對資料流階段,實施非阻塞非同步範例。此對於順暢與有效率地協調分配後端之不同副處理器之間的工作負載而言,至關重要。針對後續步驟,請確保在繼續之前,完成所有發布至資料流的活動。此時即可使用同步函式。
199 CHECK_STATUS(vpiStreamSync(stream));
VPI 已可確保在進入工作流程的下一階段之前,完成所有與資料流有關的活動。在完成同步之後,畫格已準備就緒,並出現在連線至指定後端的輸出緩衝區中。為了可以將其寫至輸出視訊資料流(在此例中為檔案)中,必須鎖定影像,以使緩衝區可以供 CPU 使用。
此即說明為何在鎖定畫格之前進行同步,是避免處理發生問題的關鍵步驟。由於 VPI 是以非同步的方式運作,因此在未同步的情況下,緩衝區可能會在上一階段完成之前遭到鎖定。結果將無法預測。
201 // Now add it to the output video stream 202 VPIImageData imgdata; 203 CHECK_STATUS(vpiImageLock(frameBGR,VPI_LOCK_READ, &imgdata)); 204 205 cv::Mat outFrame; 206 CHECK_STATUS(vpiImageDataExportOpenCVMat(imgdata, &outFrame)); 207 outVideo << outFrame; 208 209 CHECK_STATUS(vpiImageUnlock(frameBGR));
如您所見,鎖定的緩衝區是由 CPU 處置,做為其他用途。鎖定是設定為唯讀,之後影像緩衝區會對映至 CPU。當鎖定時,VPI 無法處理緩衝區。在 CPU 將輸出畫格提供給視訊編碼器之後,即可解鎖,並讓 VPI 繼續使用緩衝區。
VPI 資料流程
TNR 範例應用程式的資料流程如下。其他次要步驟也是應用程式的組成部分,但是為了能更簡單,圖 3 中僅包含主要步驟。

- 從視訊資料流或檔案中收集輸入畫格。使用 OpenCV 達成此目的。
- 將必要的 VPI 元件執行個體化:單一資料流、TNR 演算法有效負載,以及先前和目前輸入與輸出影像的影像緩衝區。
- 將輸入畫格包裝成
VPIImage緩衝區。 - 將緩衝區上的像素資料轉換成 NV12,以使用 TNR 演算法處理。在完成執行演算法之後,還原成原始格式。
- 鎖定影像緩衝區,以使 CPU 可以存取資料。在將影像提供給視訊輸出之後,即可解鎖,並由 VPI 繼續處理緩衝區。