
漫長又繁瑣的資料採購工作阻礙了人工智慧的創新,尤其是在電腦視覺領域,它依賴於有加上標記的圖片及影片進行訓練。但現在您可通過使用 AI.Reverie 快速生成合成資料以啟動機器學習過程。
有了 AI.Reverie 合成資料平台,便能在短時間內尋找和標記正確真實影像做為訓練所需的精準資料。在 AI.Reverie 的逼真 3D 環境中可為所有可能的場景生成資料,包括難以到達的地方、不尋常的環境條件,以及罕見或獨特的事件。
生成訓練資料包括標籤。選擇需要的類型,如 2D 或 3D 邊界框、深度遮罩等。在您測試完模型後,可回到平台上快速生成額外資料以提高精確度。在快速、反覆運算的循環中測試和重複這個動作。
我們想在 NVIDIA TAO 工具套件 3.0 中測試 AI.Reverie 合成資料的效能。一開始我們打算複製研究論文《RarePlanes: Synthetic Data Takes Flight》中的結果,該論文是使用合成影像來建立物體偵測模型。我們在 TAO 工具套件中發現了一些新的工具,讓我們有可能建立更多的羽量級模型;這些模型與原始論文中的模型一樣精確,但速度更快。
我們將透過本文介紹如何使用 TAO 工具套件的量化感知訓練和模型修剪來達到這個目標,以及如何自行複製這個結果。我們介紹如何建立一個飛機偵測器,但您應能為您自己的各種衛星探測情境來微調模型。

存取衛星探測模型
如要複製打造這些成果可複製 GitHub 資源庫,按照隨附的 Jupyter notebook 一同執行。
複製以下 repo:
git clone git@github.com:aireveries/rareplanes-tao.git ~/Code/rareplanes-tao
建立一個 conda 環境:
conda create -f env.yaml
啟動模型:
source activate rareplanes-tao
啟動 Jupyter:
jupyter notebook
學習目標
- 使用Reverie 平台生成合成資料,且搭配 TAO 工具套件一同使用。
- 使用合成資料訓練高精度的模型。
- 使用工具套件最佳化推論模型。
先決條件
我們用 Python 3.8.8 來測試程式碼,用 Anaconda 4.9.2 來管理依賴項和虛擬環境。該程式碼可能適用於不同版本的 Python 和其他虛擬環境解決方案,但我們未測試那些配置。我們使用了 Ubuntu 18.04.5 LTS 和 NVIDIA 驅動程式 460.32.03,以及 CUDA 11.2 版本。TAO 工具套件需要使用驅動程式 455.xx 或更新版本。
- 設定 NVIDIA Container Toolkit/nvidia-docker2。如需更多資訊,請見《NVIDIA容器工具包安裝指南》。
- 設定 NGC,使其能下載 NVIDIA Docker 容器。按照《TAO 工具套件使用指南》中的步驟 4 和 5 進行操作。更多關於 NGC CLI 工具的資訊,請見《CLI 安裝》。
- 準備至少 250GB 的硬碟空間儲存資料集和模型權重。
下載資料集
更多關於 RarePlanes 資料集內容的資訊,請見《RarePlanes 公共使用者指南》。
在本教程中,您只需要下載資料的一個子集合。下面的程式碼範例是要在 Jupyter notebook 中執行。首先建立資料夾:
!mkdir -p data/real/tarballs/{train,test}
!mkdir -p data/synthetic
現在用這個函數從 Amazon S3 下載資料集,解壓縮它們並進行驗證。
def download(s3_path, out_folder, out_file_count):
rel_file_path = Path('data') / Path(s3_path.replace('s3://rareplanes-public/', ''))
rel_folder = rel_file_path.parent / out_folder
num_files = !ls $rel_folder | wc -l
try:
if int(num_files[0]) == out_file_count:
print(f'{s3_path} already downloaded and extracted')
else:
raise Exception
except:
if not rel_file_path.exists():
print('Starting download')
!aws s3 cp $s3_path $rel_file_path;
else:
print(f'{s3_path} already downloaded')
print('Extracting...')
!cd {rel_folder.parent}; pv {rel_file_path.name} | tar xz;
print('Removing compressed file.')
!rm $rel_file_path
接著下載資料集:
download('s3://rareplanes-public/real/tarballs/metadata_annotations.tar.gz',
'metadata_annotations', 9)
download('s3://rareplanes-public/real/tarballs/train/RarePlanes_train_PS-RGB_tiled.tar.gz',
'PS-RGB_tiled', 11630)
download('s3://rareplanes-public/real/tarballs/test/RarePlanes_test_PS-RGB_tiled.tar.gz',
'PS-RGB_tiled', 5420)
!aws s3 cp --recursive s3://rareplanes-public/synthetic/ data/synthetic
從 COCO 格式轉換為 KITTI 格式
TAO 工具套件使用 KITTI 格式進行物體偵測模型訓練。RarePlanes 採用的是 COCO 格式,所以必須在 Jupyter notebook 中運行一個轉換腳本。這將轉換實體訓練/測試和合成訓練/測試資料集。
%run convert_coco_to_kitti.py
現在應在 data/kitti 中為每個資料集建立一個資料夾,其中包含 KITTI 格式的註釋文字檔和原始影像的符號連結。
設定 TAO 工具套件掛載
Jupyter notebook 有一個腳本,用於生成 ~/.tao_mounts.json 檔案。更多關於各種設定值的資訊,見《運行啟動器》。
{
"Mounts": [
{
"source": "/home/patrick.rodriguez/Code/rareplanes-tao",
"destination": "/workspace/tao-experiments"
}
],
"Envs": [
{
"variable": "CUDA_VISIBLE_DEVICES",
"value": "0"
}
],
"DockerOptions": {
"shm_size": "16G",
"ulimits": {
"memlock": -1,
"stack": 67108864
},
"user": "1001:1001"
}
}
將資料集處理成 TFRecords
您必須把 KITTI 標籤變成 TAO 工具套件使用的 TFRecord 格式。Jupyter notebook 中的 convert_split 函數可協助您批量轉換所有資料集。
def convert_split(name):
!tao detectnet_v2 dataset_convert --gpu_index 0 \
-d /workspace/tao-experiments/specs/detectnet_v2_tfrecords_{name}.txt \
-o /workspace/tao-experiments/data/tfrecords/{name}/{name}
You can then run the conversions:
convert_split('kitti_real_train')
convert_split('kitti_real_test')
convert_split('kitti_synthetic_train')
convert_split('kitti_synthetic_test')
下載 ResNet18 卷積神經網路骨架
使用您的 NGC 帳戶和命令列工具,現在可以下載該模型:
!ngc registry model download-version nvidia/tao_pretrained_detectnet_v2:resnet18
該模型現在位於以下路徑:
./tao_pretrained_detectnet_v2_vresnet18/resnet18.hdf5
使用真實資料運行一個基準實驗
下面的命令開始訓練,並且將結果記錄到一個您可以追蹤的檔案中。
!tao detectnet_v2 train --key tao --gpu_index 0 \
-e /workspace/tao-experiments/specs/detectnet_v2_train_resnet18_kitti_real.txt \
-r /workspace/tao-experiments/detectnet_v2_outputs/resnet18_real_amp16 \
-n resnet18_real_amp16 \
--use_amp > out_resnet18_real_amp16.log
按照以下命令進行操作:
tail -f ./out_resnet18_real_amp16.log
訓練完成後,您可以使用 Jupyter notebook 中定義的函數獲得與您的模型有關的統計資料。
get_model_param_counts('./out_resnet18_real_amp16.log')
best_epoch = get_best_epoch('./out_resnet18_real_amp16.log')
best_epoch
您會得到類似以下的輸出內容:
Total params: 11,197,893 Trainable params: 11,188,165 Non-trainable params: 9,728 Best epoch and map50 metric: (79, 94.2296)
如要使用您的測試集或其他資料集再次評估訓練模型,請運行以下內容:
!tao detectnet_v2 evaluate --gpu_index 0 \
-e /workspace/tao-experiments/specs/detectnet_v2_evaluate_real.txt \
-m /workspace/tao-experiments/{best_checkpoint} \
-k tao
輸出內容應該看起來像這樣:
Validation cost: 0.001133 Mean average_precision (in %): 94.2563 class name average precision (in %) ------------ -------------------------- aircraft 94.2563 Median Inference Time: 0.003877 2021-04-06 05:47:00,323 [INFO] __main__: Evaluation complete. Time taken to run __main__:main: 0:00:27.031500. 2021-04-06 05:47:02,466 [INFO] tao.components.docker_handler.docker_handler: Stopping container.
使用合成資料運行實驗
!tao detectnet_v2 train --key tao --gpu_index 0 \
-e /workspace/tao-experiments/specs/detectnet_v2_train_resnet18_kitti_synth.txt \
-r /workspace/tao-experiments/detectnet_v2_outputs/resnet18_synth_amp16 \
-n resnet18_synth_amp16 \
--use_amp > out_resnet18_synth_amp16.log
可以運行 !cat out_resnet18_synth_amp16.log | grep -i aircraft 來查看每個 epoch 的結果。
範例輸出:
aircraft 58.1444 aircraft 65.1423 aircraft 64.3203 aircraft 68.1934 aircraft 71.5754 aircraft 68.5568
用真實資料來微調合成訓練的模型
現在用 10% 的真實資料對您表現最好的合成資料訓練模型進行微調。如要做到這一點,您必須先建立 10% 的分割。
%run ./create_train_split.py
convert_split('kitti_real_train_10')
然後,您用這個函數將範本規格中的檢查點,換成只進行合成訓練的最佳效能模型。
with open('./specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10.txt', 'r') as f_in:
with open('./specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_replaced.txt', 'w') as f_out:
out = f_in.read().replace('REPLACE', best_checkpoint)
f_out.write(out)
現在您可以開始進行 TAO 工具套件的訓練。從上一節中僅使用合成資料進行訓練之模型中表現最好的 epoch 開始進行微調。
!tao detectnet_v2 train --key tao --gpu_index 0 \
-e /workspace/tao-experiments/specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_replaced.txt \
-r /workspace/tao-experiments/detectnet_v2_outputs/resnet18_synth_finetune_10_amp16 \
-n resnet18_synth_finetune_10_amp16 \
--use_amp > out_resnet18_synth_finetune_10_amp16.log
完成訓練後,您應該看到 mAP50 介於 91-93% 的最佳 epoch,這讓您使用只有 10% 的真實資料,達到接近僅使用真實資料的模型效能。
在 Jupyter notebook 中,有一條命令可以評估測試集上表現最好的模型檢查點。
!tao detectnet_v2 evaluate --gpu_index 0 \
-e /workspace/tao-experiments/specs/detectnet_v2_evaluate_real.txt \
-m /workspace/tao-experiments/{best_checkpoint} \
-k tao
您會看到類似以下的輸出內容:
2021-04-06 18:05:28,342 [INFO] iva.detectnet_v2.evaluation.evaluation: step 330 / 339, 0.05s/step Matching predictions to ground truth, class 1/1.: 100%|█| 14719/14719 [00:00<00:00, 15814.87it/s] Validation cost: 0.001368 Mean average_precision (in %): 91.8094 class name average precision (in %) ------------ -------------------------- aircraft 91.8094 Median Inference Time: 0.004137 2021-04-06 18:05:30,327 [INFO] __main__: Evaluation complete. Time taken to run __main__:main: 0:00:30.677440. 2021-04-06 18:05:32,469 [INFO] tao.components.docker_handler.docker_handler: Stopping container.
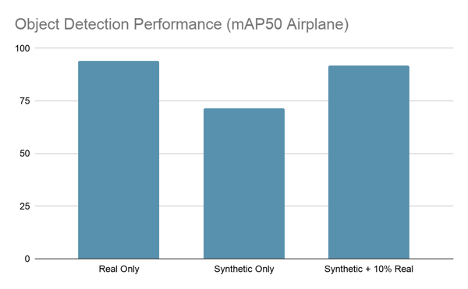
資料增強是對使用 AI.Reverie 的合成資料進行訓練的模型進行微調,只使用 10% 的原始真實資料集。正如您所看到的,這項技術產生的模型,與只使用真實資料進行訓練的模型一樣準確。這代表可以省下 90% 使用真實標記過的資料進行訓練的成本,又使您不必忍受漫長的手工標記和品管過程。
修剪模型
在訓練出一個效能優秀的模型後現在可減少權重的數量,以減少檔案大小和推論時間。TAO 工具套件內有一個可輕鬆使用的修剪工具。
需要使用 -pth 這個參數,它設定了要修剪的神經元的閾值。設定的越高修剪的參數就越多,但在一定程度上準確度指標可能會下降得太低。我們發現 0.5 這個值對這些實驗是有效的,但可能會在其他資料集上發現不同的結果。
!mkdir -p detectnet_v2_outputs/pruned
!tao detectnet_v2 prune \
-m /workspace/tao-experiments/{best_checkpoint} \
-o /workspace/tao-experiments/detectnet_v2_outputs/pruned/pruned-model.tao \
-eq union \
-pth 0.5 \
-k tao
您現在可以評估修剪後的模型:
!tao detectnet_v2 evaluate --gpu_index 0 \
-e /workspace/tao-experiments/specs/detectnet_v2_evaluate_real.txt \
-m /workspace/tao-experiments/detectnet_v2_outputs/pruned/pruned-model.tao \
-k tao > out_pruned.txt
現在您可以看到還剩下多少個參數。
get_model_param_counts('./out_pruned.txt')
您會看到類似以下的輸出內容:
Total params: 3,372,973 Trainable params: 3,366,573 Non-trainable params: 6,400
這比原來的模型小了 70%,而原來的模型有 1,120 萬個參數!當然,您修剪掉了這麼多的參數就失去了效能,這一點您可以驗證:
!cat out_pruned.txt | grep -i aircraft aircraft 68.8865
還好可以再次訓練修剪後的模型來恢復幾乎所有的效能。
重新訓練模型
和以前一樣,有一個範本規格來運行這個實驗,只要填入修剪後模型的位置即可:
with open('./specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain.txt', 'r') as f_in:
with open('./specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain_replaced.txt', 'w') as f_out:
out = f_in.read().replace('REPLACE', 'detectnet_v2_outputs/pruned/pruned-model.tao')
f_out.write(out)
現在可以重新訓練已修剪的模型:
!tao detectnet_v2 train --key tao --gpu_index 0 \
-e /workspace/tao-experiments/specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain_replaced.txt \
-r /workspace/tao-experiments/detectnet_v2_outputs/resnet18_synth_finetune_10_pruned_retrain_amp16 \
-n resnet18_synth_finetune_10_pruned_retrain_amp16 \
--use_amp > out_resnet18_synth_finetune_10_pruned_retrain_amp16.log
在運行這個實驗的過程中表現最好的 epoch 達到了 91.925 mAP50,這與原來未修剪的實驗差不多。
2021-04-06 19:33:39,360 [INFO] iva.detectnet_v2.evaluation.evaluation: step 330 / 339, 0.05s/step Matching predictions to ground truth, class 1/1.: 100%|█| 17403/17403 [00:01<00:00, 15748.62it/s] Validation cost: 0.001442 Mean average_precision (in %): 91.9849 class name average precision (in %) ------------ -------------------------- aircraft 91.9849 Median Inference Time: 0.003635 2021-04-06 19:33:41,479 [INFO] __main__: Evaluation complete. Time taken to run __main__:main: 0:00:31.869671. 2021-04-06 19:33:43,607 [INFO] tao.components.docker_handler.docker_handler: Stopping container.
對模型進行量化
這個過程的最後一步是對修剪後的模型進行量化,這樣就能用 TensorRT 達到更高水準的推論速度。我們有一個量化意識訓練(quantization aware training,QAT)的規格範本:
with open('./specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain_qat.txt', 'r') as f_in:
with open('./specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain_qat_replaced.txt', 'w') as f_out:
out = f_in.read().replace('REPLACE', 'detectnet_v2_outputs/pruned/pruned-model.tao')
f_out.write(out)
執行 QAT 訓練:
!tao detectnet_v2 train --key tao --gpu_index 0 \
-e /workspace/tao-experiments/specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain_qat_replaced.txt \
-r /workspace/tao-experiments/detectnet_v2_outputs/resnet18_synth_finetune_10_pruned_retrain_qat_amp16 \
-n resnet18_synth_finetune_10_pruned_retrain_qat_amp16 \
--use_amp > out_resnet18_synth_finetune_10_pruned_retrain_qat_amp16.log
使用 TAO 工具套件的匯出工具,匯出為 INT8 量化的 TensorRT 格式:
!tao detectnet_v2 export \
-m /workspace/tao-experiments/{best_checkpoint} \
-o /workspace/tao-experiments/detectnet_v2_outputs/qat/resnet18_detector_qat.etao \
-k tao \
--data_type int8 \
--batch_size 64 \
--max_batch_size 64\
--engine_file /workspace/tao-experiments/detectnet_v2_outputs/qat/resnet18_detector_qat.trt.int8 \
--cal_cache_file /workspace/tao-experiments/detectnet_v2_outputs/qat/calibration_qat.bin \
--verbose
此時可使用 TensorRT 評估您的量化模型:
!tao detectnet_v2 evaluate -e /workspace/tao-experiments/specs/detectnet_v2_train_resnet18_kitti_synth_finetune_10_pruned_retrain_qat_replaced.txt \
-m /workspace/tao-experiments/detectnet_v2_outputs/qat/resnet18_detector_qat.trt.int8 \
-f tensorrt
看一下輸出內容:
2021-04-06 23:08:28,471 [INFO] iva.detectnet_v2.evaluation.tensorrt_evaluator: step 330 / 339, 0.33s/step Matching predictions to ground truth, class 1/1.: 100%|█| 21973/21973 [00:01<00:00, 16161.54it/s] Validation cost: 0.549463 Mean average_precision (in %): 91.5516 class name average precision (in %) ------------ -------------------------- aircraft 91.5516 Median Inference Time: 0.000840 2021-04-06 23:08:33,182 [INFO] __main__: Evaluation complete. Time taken to run __main__:main: 0:02:13.453132. 2021-04-06 23:08:34,768 [INFO] tao.components.docker_handler.docker_handler: Stopping container.
結論
我們對這些結果感到非常驚艷。AI.Reverie 的合成資料平台只用了真實資料集的 10%,就達到了跟使用全部真實資料集來訓練一樣的效能。這代表可以省下大約 90% 的成本,更不用說還能省下採購時間。現在生成所需的合成資料只需要幾天,無需用上幾個月的時間。
TAO 工具套件還讓參數數量減少 25.2 倍、檔案大小減少 33.6 倍、性能(QPS)增加 174.7 倍,同時保留了 95% 的原始效能。TAO 工具套件的功能對修剪和量化特別有價值。