相較於當前的 Maxwell 處理器,NVIDIA 預計於明年推出的 Pascal 架構 GPU 將使深度學習應用程式的運算速度加快十倍。
NVIDIA 執行長暨共同創辦人黃仁勳先生在於矽谷舉辦的 GPU 科技大會開幕主題演講活動上,對四千名與會嘉賓揭露 Pascal 架構的細節與處理器的最新發展藍圖。
他對聽眾們說:「研發部門在過去三年裡不斷精鍊、讓我們從中受惠十億美元。」
電腦開始使用深度學習技術的神經網路來教導自己,這個趨勢的興起讓 NVIDIA 又調整了原本在去年 GTC 即公布的 Pascal 架構設計內容。
Pascal 架構 GPU 的三大設計特色將大幅加快訓練速度,更精準地訓練更豐富的深度神經網路,猶如人類大腦皮層的資料結構將成為深度學習研究的基礎。
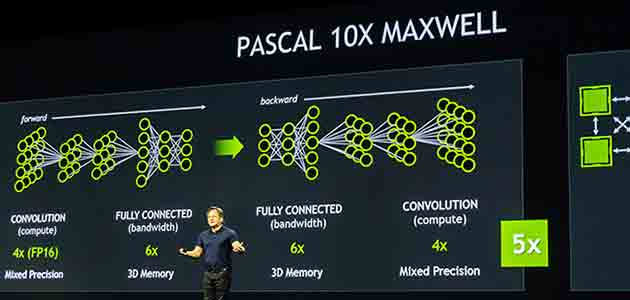
再加上 32GB 的記憶體(是剛發表 NVIDIA 旗艦級繪圖卡 GeForce GTX TITAN X 的 2.7 倍),Pascal 架構可進行混合精密的運算作業。它將配備 3D 記憶體,提升深度學習應用程式的速度效能多達5倍;另搭配 NVIDIA 的高速互連技術 NVLink 來連接兩個以上的 GPU,可將深度學習的速度效能提升達十倍。

在關鍵深度學習的作業方面,Pascal 架構的效能表現優於 Maxwell 架構。
混合精密運算技術 – 達到更精準的結果
混合精密運算技術讓採用 Pascal 架構的 GPU 能以16位元浮點運算兩倍精準度的32位元浮點運算精準度進行運算。
更佳的浮點運算效能特別提高了深度學習兩大活動:分類和摺積的效能,同時又達到所需的精準度。
3D 記憶體 – 更快的資料傳遞速度和優秀的省電表現
記憶體頻寬方面的限制侷限了將資料傳到 GPU 的速度。採用 3D 記憶體將可提高比 Maxwell 架構高出三倍的頻寬和近三倍的記憶體容量,讓開發人員能建立更大的神經網路,加快深度學習訓練需使用大量頻寬部分的運算速度。
Pascal 架構將相疊的記憶體晶片放在 GPU 旁邊,而非放在處理器機板下方,如此就能把資料在記憶體與 GPU 間往返的距離從幾英吋減縮到幾公釐,大幅加快傳遞速度和擁有更佳的省電表現。
NVLink – 加快資料移動速度
Pascal 架構加入 NVLink 技術的舉動將使得 GPU 與 CPU 間資料移動的速度,較現有的 PCI-Express 標準加快5到12倍,對於深度學習這些需要更高 GPU 間傳遞速度的應用程式來說是一大福音。
NVLink 可將系統裡的 GPU 數量增加一倍,以共同用於深度學習運算作業上;還能以新的方式連接 CPU 與 GPU,在伺服器設計方面提供較 PCI-E 規格更佳的彈性和省電表現。