
根據今天發布的 MLPerf 基準測試結果,NVIDIA (輝達) 與其合作夥伴持續提供最佳的整體人工智慧 (AI) 訓練成果,且在所有測試項目中提交最多結果,高達 90% 的參賽者來自 NVIDIA 的生態系。
NVIDIA AI 平台完成了 MLPerf 訓練 2.0 中八個完整的測試項目,突顯出其頂尖的多功能性。
沒有其他的加速器能夠完成所有基準測試,這些測試代表業界廣泛採用的 AI 應用,包括語音辨識、自然語言處理、推薦系統、物件偵測、圖像分類等。而 NVIDIA 自 2018 年 12 月第一次向 MLPerf 這個業界標準的 AI 基準測試提交成果以來,始終都是完成所有測試的參賽者。
頂尖基準測試結果及可用性
在連續四年提交的 MLPerf 基準測試中, 基於 NVIDIA Ampere 架構的 NVIDIA A100 Tensor 核心 GPU 持續締造優異的表現。
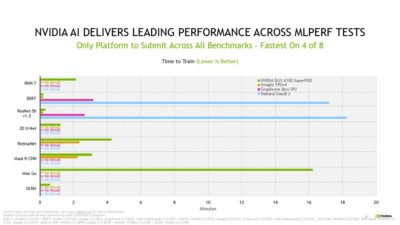
Selene 以最快的速度完成了八項訓練測試中的其中四項。Selene 是 NVIDIA 內部的 AI 超級電腦,基於模組化 NVIDIA DGX SuperPOD 建置而成,並由 NVIDIA A100 GPU、NVIDIA 的軟體堆疊和 NVIDIA InfiniBand 網路技術互連。
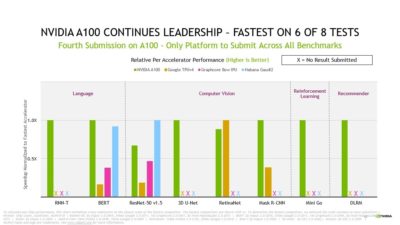
NVIDIA A100 GPU 也持續引領在單一晶片的領導地位,在八項測試中奪得六項冠軍。
總計有十六家合作夥伴提出了使用 NVIDIA AI 平台進行測試的結果,包括華碩 (ASUS)、百度 (Baidu)、中國科學院自動化研究所 (CASIA;Institute of Automation, Chinese Academy of Sciences)、戴爾科技 (Dell Technologies)、富士通 (Fujitsu)、技嘉科技 (GIGABYTE)、新華三 (New H3C Information Technologies)、慧與科技 (Hewlett Packard Enterprise)、浪潮 (Inspur Electronic Information)、聯想 (Lenovo)、寧暢 (Nettrix) 與美超微 (Supermicro) 等。
我們的大多數 OEM 合作夥伴使用 NVIDIA 認證系統提交結果,這些伺服器經 NVIDIA 認證,可為企業部署提供出色的效能、可管理性、安全性和可擴展性。
許多模型驅動著應用於真實世界的 AI 應用程式
AI 應用程式可能需要理解用戶的語音請求內容、對圖片進行分類、提出建議,並以語音訊息的方式做出回應。
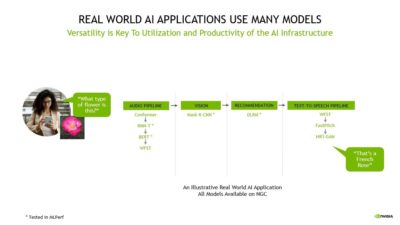
這些工作需要透過多種 AI 模型按照順序運行,也稱之為工作流程,用戶需要快速靈活地設計、訓練、部署和最佳化這些模型。
這也是多功能性 (能夠在 MLPerf 及更多任務中運行每一種模型的能力) 和頂尖效能對於將真實世界中的 AI 投入生產而言至關重要的原因。
藉由 AI 提供投資報酬率
對於客戶而言,他們的資料科學和工程團隊是最寶貴的資源,他們的生產力決定 AI 基礎設施的投資報酬率。客戶必須考量資料科學團隊衍生的高昂成本,這通常在部署 AI 的總成本中占很大一部分,同時也須考慮成本相對較低的 AI 基礎設施部署。
AI 研究人員的生產力取決於快速測試新想法的能力,除了需要能夠訓練任何模型的多功能性,也需要大規模訓練這些模型所提供的速度。這就是組織以每一美元單位生產力來決定最佳 AI 平台的原因,讓他們得以用更綜觀全局的方式、更準確地體現部署 AI 的真實成本。
此外,AI 基礎設施的運用仰賴於它的可替代性,或在單一平台上加速整個 AI 工作流程 (從資料準備、訓練到推論) 的能力。
借助 NVIDIA AI,客戶可以為整個 AI 流程使用相同的基礎架構、重新調整其用途,以滿足資料準備、訓練和推論之間的不同需求,從而帶來極高的投資報酬率。
而且,隨著研究人員發現新的 AI 突破,支援最新模型的創新是極大化 AI 基礎設施運用的關鍵。
NVIDIA AI 提供最高的每一美元單位生產力,因為它對每個模型都具有通用性和高效能,可擴展至任何規模,並可從端到端加速 AI,無論是資料準備、訓練與推論皆然。
今天公布的最新測試結果證明,NVIDIA 在迄今的每一次 MLPerf 訓練、推論及高效能運算測試項目中,均具備廣泛且深入的 AI 技術。
三年半提高了 23 倍的效能
自 A100 首次參與 MLPerf 測試以來的兩年中,我們的平台提升了 6 倍以上的效能,而持續進行軟體堆疊最佳化則有助於推動這些效益。
自 MLPerf 基準測試推出以來,NVIDIA AI 平台 3.5 年內在此測試中提高了 23 倍的效能,這是橫跨 GPU、軟體和大規模改善的全方位創新的成果。正是這種對創新的長期承諾推動並支撐著最頂尖的技術,確保客戶今日對於 AI 平台的投資得以延續 3 到 5 年之久。
此外,今年三月宣布推出的 NVIDIA Hopper 架構有望在未來的 MLPerf 測試中展現更優異的效能。
我們是如何寫下如此亮眼的成績
軟體的創新繼續釋放 NVIDIA Ampere 架構的更多效能。
以 CUDA Graphs 為例,它是一款能幫助在許多加速器上運行的作業負載降至最低的軟體,該軟體在此次的提交成果中被廣泛使用。我們函式庫中的最佳核心,如 cuDNN 和 DALI 中的預處理,提供額外的加速功能。我們也針對如 NVIDIA Magnum IO 和 SHARP 等硬體、軟體和網路進行全方位的改善,將一些 AI 功能卸載到網路,推動更大規模的優異效能。
所有人都能從 MLPerf 資源庫取得 NVIDIA 使用的各種軟體以獲得世界級的成果。我們不斷將這些最佳化結果放入 NGC (我們的 GPU 應用軟體中樞) 的容器內,並提供 NVIDIA AI 企業級的優化軟體,並由 NVIDIA 提供全方位的支援。
A100 首次亮相的兩年後,NVIDIA AI 平台持續締造 MLPerf 2.0 中的最高效能成果,也是唯一一個提交所有基準測試項目的平台。我們的新一代 Hopper 架構有望在未來的 MLPerf 測試中又一次創造更卓越的成績。
NVIDIA 的平台適用於任何規模的所有模型和框架,並提供處理 AI 作業負載各個環節的可替代性,它在各個雲端服務中皆可使用,且可向所有的主要伺服器製造商取得。