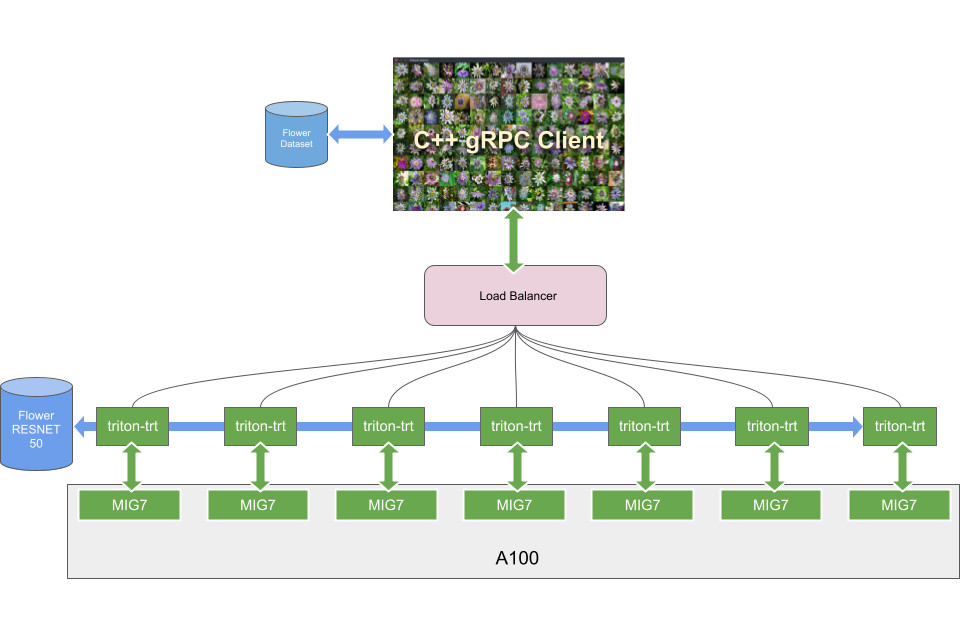
NVIDIA 發表的以 NVIDIA Ampere 架構為基礎的 A100 GPU 模型。Ampere 導入了許多功能,包括在深度學習應用程式中扮演特殊角色的多執行個體 GPU(Multi-Instance GPU,MIG)。MIG 可以將單一 A100 GPU 當成多個較小的 GPU 使用,以最大化深度學習工作負載的利用率,並提供動態擴充性。
在推出 V100 後,我們隨之提供花卉示範,展示 NVIDIA TensorRT 可為典型影像分類推論問題實現優異效能的能力。之後,亦使用該花卉示範,展示在 Kubernetes 叢集中充分利用多 GPU 系統和其擴充性。我們展示了如何使用 Triton,在同一個 GPU 上載入多個模型,以便在任何可用的 GPU 上處理任一模型的推論要求,提升滿足推論需求高峰的能力。
本篇部落格將透過 MIG,進行更進一步的花卉示範:雖然它是為多 GPU 系統而設計,但本次我們將示範如何在同一個 GPU 上(單一 GPU 並使用 MIG),獨立(故障隔離)執行多個影像分類任務。
多執行個體 GPU
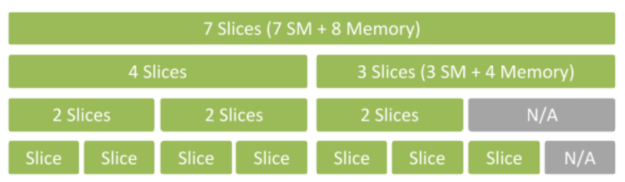
NVIDIA Ampere 架構可讓您使用 MIG 加速運算。MIG 是使用空間切片,將單一 A100 GPU 之實體資源切成至多 7 個獨立的 GPU 執行個體。它們可以同時執行,且分別擁有各自的記憶體、快取和串流多處理器。因此 A100 GPU 可以使用比先前之 GPU 高 7 倍的利用率,提供服務品質保證。
MIG 模式下的 A100 可以執行 2 至 7 個大小不同的獨立人工智慧或高效能運算(HPC)工作負載。此能力對於通常不需要透過現代 GPU 提供所有效能的人工智慧推論工作特別有用。
例如,您可以建立 2 個各有 20 GB 記憶體的 MIG 執行個體、3 個各有 10 GB 的執行個體,或 7 個各有 5 GB 的執行個體。您可以隨意建立適合您的工作負載的組合。
花卉示範
為了示範 MIG 的用法,本文章介紹在花卉資料集上執行分類,以及專為此目的而訓練的典型 ResNet50 網路。
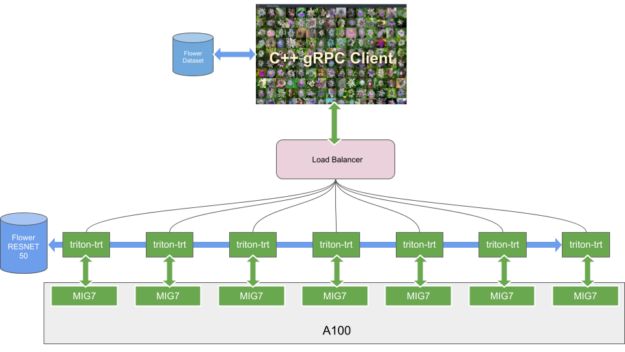
採用 MIG 執行個體之 A100 GPU 的典型推論情境是服務多個模型,並根據傳入要求的數量擴充任一模型。在第一個範例中是執行單一花卉模型,目標為在 7 個 MIG 執行個體上,以批次大小 1 達到最低延遲。此配置的優點,如下所示:
- 平行要求:以真正平行的方式,服務多個要求的能力
- 容錯和故障隔離:每一個執行個體皆維持相同的 QoS,即使任一個執行個體失效,其他執行個體仍可以正常運作;
- 傳輸量和延遲:在批次大小等於 1 的情況下,執行的 MIG 執行個體越多,達到的傳輸量越高及延遲越低。
在伺服器上,每一個 MIG「切片」都由在 Docker 容器中執行的 Triton 提供個體服務。負載平衡器是使用 HTTP 或 gRPC,將傳入要求導向作用中的 MIG。
本文章簡要描述了一些訓練細節,以及伺服器和用戶端配置的步驟。
使用花卉資料集進行訓練
我們將花卉資料集整理成 ImageNet 格式。每一個類別都有一個資料夾,所以訓練和驗證資料集各有 102 個資料夾。我們是在 PyTorch 中訓練 ResNet-50 模型。若需要更多與原始模型有關的資訊,請參閱 NVIDIA/DeepLearningExamples/ GitHub 儲存庫。
我們自訂 ResNet-50 模型的輸出層,為 102 個花卉類別進行分類,以及新增 softmax 層做為最後一層。我們在完成訓練之後,從檢查點產生 ONNX 模型,以在 Triton 上進行推論。為了最佳化效能,我們透過以下命令,使用 TensorRT Docker 容器 nvcr.io/nvidia/tensorrt:20.11-py3 產生 TensorRT 引擎檔案:
trtexec --onnx=flower_resnet50.onnx --fp16 --saveEngine=flower_resnet50.plan --verbose --explicitBatch
之後,我們使用產生的檔案做為 Triton 中的推論模型。
花卉伺服器
確定搭載 A100 GPU 的伺服器上已啟用 MIG 模式,才能建立 MIG 執行個體。執行以下命令,需要 sudo 權限:
$ sudo nvidia-smi -mig 1
Enabled MIG Mode for GPU 00000000:65:00.0
在啟用 MIG 模式時,GPU 會經歷重設流程。下一步是列出適用於 GPU 執行個體的設定檔:
$ sudo nvidia-smi mig --list-gpu-instance-profiles
+--------------------------------------------------------------------------+
| GPU instance profiles: |
| GPU Name ID Instances Memory P2P SM DEC ENC |
| Free/Total GiB CE JPEG OFA |
|==========================================================================|
| 0 MIG 1g.5gb 19 7/7 4.95 No 14 0 0 |
| 1 0 0 |
+--------------------------------------------------------------------------+
| 0 MIG 2g.10gb 14 3/3 9.90 No 28 1 0 |
| 2 0 0 |
+--------------------------------------------------------------------------+
| 0 MIG 3g.20gb 9 2/2 19.79 No 42 2 0 |
| 3 0 0 |
+--------------------------------------------------------------------------+
| 0 MIG 4g.20gb 5 1/1 19.79 No 56 2 0 |
| 4 0 0 |
+--------------------------------------------------------------------------+
| 0 MIG 7g.40gb 0 1/1 39.59 No 98 5 0 |
| 7 1 1 |
+--------------------------------------------------------------------------+
設定檔 ID=19 (1g.5gb) 是我們建立的設定檔:它是最小的 MIG 執行個體,在 A100 上可以具有最多 7 個。在每一個執行個體上可擬合 1 個複本的花卉模型,總計為最多 7 個。
透過以下命令,建立 GPU 執行個體:
$ sudo nvidia-smi mig --create-gpu-instance <profileId>
於此情況下,會變成以下命令:
$ sudo nvidia-smi mig --create-gpu-instance 19
必須多次執行該命令(7 次),才能建立所有的執行個體。
列出剛才建立的 GPU 執行個體:
$ sudo nvidia-smi mig --list-gpu-instances
+----------------------------------------------------+
| GPU instances: |
| GPU Name Profile Instance Placement |
| ID ID Start:Size |
|====================================================|
| 0 MIG 1g.5gb 19 7 4:1 |
+----------------------------------------------------+
| 0 MIG 1g.5gb 19 8 5:1 |
+----------------------------------------------------+
| 0 MIG 1g.5gb 19 9 6:1 |
+----------------------------------------------------+
| 0 MIG 1g.5gb 19 11 0:1 |
+----------------------------------------------------+
| 0 MIG 1g.5gb 19 12 1:1 |
+----------------------------------------------------+
| 0 MIG 1g.5gb 19 13 2:1 |
+----------------------------------------------------+
| 0 MIG 1g.5gb 19 14 3:1 |
+----------------------------------------------------+
現在已具有建立運算執行個體需要的 GPU 執行個體,已可透過以下命令,列出所有可用的配置:
$ sudo nvidia-smi mig --list-compute-instance-profiles
+--------------------------------------------------------------------------------------+
| Compute instance profiles: |
| GPU GPU Name Profile Instances Exclusive Shared |
| Instance ID Free/Total SM DEC ENC OFA |
| ID CE JPEG |
|======================================================================================|
| 0 7 MIG 1g.5gb 0* 1/1 14 0 0 0 |
| 1 0 |
+--------------------------------------------------------------------------------------+
| 0 8 MIG 1g.5gb 0* 1/1 14 0 0 0 |
| 1 0 |
+--------------------------------------------------------------------------------------+
| 0 9 MIG 1g.5gb 0* 1/1 14 0 0 0 |
| 1 0 |
+--------------------------------------------------------------------------------------+
| 0 11 MIG 1g.5gb 0* 1/1 14 0 0 0 |
| 1 0 |
+--------------------------------------------------------------------------------------+
| 0 12 MIG 1g.5gb 0* 1/1 14 0 0 0 |
| 1 0 |
+--------------------------------------------------------------------------------------+
| 0 13 MIG 1g.5gb 0* 1/1 14 0 0 0 |
| 1 0 |
+--------------------------------------------------------------------------------------+
| 0 14 MIG 1g.5gb 0* 1/1 14 0 0 0 |
| 1 0 |
+--------------------------------------------------------------------------------------+
如果執行以下命令,則找不到 MIG 裝置:
$ nvidia-smi
...
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| No MIG devices found |
+-----------------------------------------------------------------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
請執行以下命令,建立運算執行個體,以使用 MIG:
$ sudo nvidia-smi mig --gpu-instance-id <gpuInstanceId> –-create-compute-instance <computInstanceProfileId>
如果執行以下 2 個命令,則會建立前 2 個運算執行個體:
$ sudo nvidia-smi mig --gpu-instance-id 7 --create-compute-instance 0
$ sudo nvidia-smi mig --gpu-instance-id 8 --create-compute-instance 0
$ nvidia-smi
...
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| 0 7 0 0 | 3MiB / 4888MiB | 14 0 | 1 0 0 0 0 |
+------------------+----------------------+-----------+-----------------------+
| 0 8 0 1 | 3MiB / 4888MiB | 14 0 | 1 0 0 0 0 |
+------------------+----------------------+-----------+-----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
現在列出剛才建立之執行個體的 UUID:
$ sudo nvidia-smi -L
GPU 0: Graphics Device (UUID: GPU-6e89a967-292d-f5fc-2af0-a2e2f2ccc326)
MIG 1g.5gb Device 0: (UUID: MIG-GPU-6e89a967-292d-f5fc-2af0-a2e2f2ccc326/7/0)
MIG 1g.5gb Device 1: (UUID: MIG-GPU-6e89a967-292d-f5fc-2af0-a2e2f2ccc326/8/0)
於此範例中,是為各個 GPU 執行個體建立 1 個運算執行個體,所以必須另外建立 5 個運算執行個體:
$ sudo nvidia-smi mig --gpu-instance-id 9 --create-compute-instance 0
$ sudo nvidia-smi mig --gpu-instance-id 11 --create-compute-instance 0
$ sudo nvidia-smi mig --gpu-instance-id 12 --create-compute-instance 0
$ sudo nvidia-smi mig --gpu-instance-id 13 --create-compute-instance 0
$ sudo nvidia-smi mig --gpu-instance-id 14 --create-compute-instance 0
現在已配置硬體,可以在執行 CUDA 容器時,測試一切是否正常運作。請安裝最新的 nvidia-docker 版本,僅啟用一個 MIG,然後查看 nvidia-smi -L 命令顯示的結果。您應該只會看到已啟用的 MIG:
$ sudo docker run \
--gpus '"device=0:0"' \
nvidia/cuda:9.0-base nvidia-smi -L
前一個命令的結果,如下所示:
GPU 0: Graphics Device (UUID: GPU-6e89a967-292d-f5fc-2af0-a2e2f2ccc326)
MIG 1g.5gb Device 0: (UUID: MIG-GPU-6e89a967-292d-f5fc-2af0-a2e2f2ccc326/7/0)
現在,可以在建立的運算執行個體上執行 Triton 推論伺服器(Triton Inference Server)。從 NGC 提取 20.07-py3 of the Triton Docker container:
$ sudo docker pull nvcr.io/nvidia/tritonserver:20.07-py3
您可以透過以下命令,在各個運算執行個體上執行推論伺服器:
$ sudo docker run -d -p 8000:8000 -p 8001:8001 -v '/home/user/flower_model:/models' --gpus '"device=0:0"' \
nvcr.io/nvidia/tritonserver:20.07-py3 --model-repository=/models --allow-gpu-metrics=false
…
$ sudo docker run -d -p 8010:8000 -p 8011:8001 -v '/home/user/flower_model:/models' --gpus '"device=0:1"' \
nvcr.io/nvidia/tritonserver:20.07-py3 --model-repository=/models --allow-gpu-metrics=false
…
$ sudo docker run -d -p 8020:8000 -p 8021:8001 -v '/home/user/flower_model:/models' --gpus '"device=0:2"' \
nvcr.io/nvidia/tritonserver:20.07-py3 --model-repository=/models --allow-gpu-metrics=false
…
$ sudo docker run -d -p 8030:8000 -p 8031:8001 -v '/home/user/flower_model:/models' --gpus '"device=0:3"' \
nvcr.io/nvidia/tritonserver:20.07-py3 --model-repository=/models --allow-gpu-metrics=false
…
$ sudo docker run -d -p 8040:8000 -p 8041:8001 -v '/home/user/flower_model:/models' --gpus '"device=0:4"' \
nvcr.io/nvidia/tritonserver:20.07-py3 --model-repository=/models --allow-gpu-metrics=false
…
$ sudo docker run -d -p 8050:8000 -p 8051:8001 -v '/home/user/flower_model:/models' --gpus '"device=0:5"' \
nvcr.io/nvidia/tritonserver:20.07-py3 --model-repository=/models --allow-gpu-metrics=false
…
$ sudo docker run -d -p 8060:8000 -p 8061:8001 -v '/home/user/flower_model:/models' --gpus '"device=0:6"' \
nvcr.io/nvidia/tritonserver:20.07-py3 --model-repository=/models --allow-gpu-metrics=false
參數 –allow-gpu-metrics=false 指示 Triton 停用的 GPU 指標,通常可以在連接埠 8002 上使用。
先前命令的預期輸出,如以下程式碼範例所示:
=============================
== Triton Inference Server ==
=============================
NVIDIA Release 20.07
….
tensorflow/core/common_runtime/gpu/gpu_device.cc:1639] Found device 0 with properties:
name: Graphics Device MIG 1g.6gb major: 8 minor: 0 memoryClockRate(GHz): 1.005
pciBusID: 0000:65:00.0
2020-06-04 21:17:26.436662: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully
…
GPU (device: 0, name: Graphics Device MIG 1g.5gb, pci bus id: 0000:65:00.0, compute capability: 8.0)
2020-06-04 21:17:28.159864: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7f638234b7a0 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
2020-06-04 21:17:28.159887: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Graphics Device MIG 1g.5gb, Compute Capability 8.0
I0604 21:17:28.162996 1 model_repository_manager.cc:888] successfully loaded 'simple' version 1
Starting endpoints, 'inference:0' listening on
I0604 21:17:28.166764 1 grpc_server.cc:1942] Started GRPCService at 0.0.0.0:8001
I0604 21:17:28.166817 1 http_server.cc:1428] Starting HTTPService at 0.0.0.0:8000
I0604 21:17:28.210177 1 http_server.cc:1443] Starting Metrics Service at 0.0.0.0:8002
從紀錄中可見,每一個 Triton 執行個體都找到了一個運算能力為 8.0 的 MIG (1g.5gb)。
此時,總共有 7 個 Triton 執行個體,分別在不同的 MIG 上執行。
花卉伺服器的最後一步是安裝與執行負載平衡器,將傳入的推論要求,重新導向對應的 Triton 執行個體。在本文章中是使用已開放原始碼,且容易配置的 Envoy 負載平衡器。
透過以下命令,提取 Envoy Docker 容器:
$ docker pull envoyproxy/envoy:v1.14.1
您可以使用 HTTP 或 gRPC 協定執行推論。針對 GRPC,使用以下 lb-envoy-grpc.yaml 配置:
static_resources:
listeners:
- address:
socket_address:
address: 0.0.0.0
port_value: 50050
filter_chains:
- filters:
- name: envoy.http_connection_manager
config:
codec_type: auto
stat_prefix: ingress_http
route_config:
name: local_route
virtual_hosts:
- name: backend
domains:
- "*"
routes:
- match:
prefix: "/"
headers:
- name: content-type
prefix_match: application/grpc
route:
cluster: inference
http_filters:
- name: envoy.router
config: {}
clusters:
- name: inference
connect_timeout: 10.00s
type: strict_dns
lb_policy: round_robin
http2_protocol_options: {}
hosts:
- socket_address:
address: 127.0.0.1
port_value: 8001
- socket_address:
address: 127.0.0.1
port_value: 8011
- socket_address:
address: 127.0.0.1
port_value: 8021
- socket_address:
address: 127.0.0.1
port_value: 8031
- socket_address:
address: 127.0.0.1
port_value: 8041
- socket_address:
address: 127.0.0.1
port_value: 8051
- socket_address:
address: 127.0.0.1
port_value: 8061
admin:
access_log_path: "/workspace/envoy.log"
address:
socket_address:
address: 0.0.0.0
port_value: 9001
HTTP 的配置相似。使用的 Triton 連接埠為 8000、8010、8020、8030、8040、8050、8060。您可以註解排除先前配置中與 socket_address 有關的部分,以啟用或停用一或多個 MIG 執行個體。
最後,使用以下命令,執行負載平衡器:
$ docker run -it --net host -v $PWD:/workspace envoyproxy/envoy:v1.14.1 envoy -c /workspace/lb-envoy.yaml
現在,伺服器正在等待傳入的推論要求。請下載安裝和執行伺服器需要的檔案。
花卉分類用戶端
現在已啟用伺服器,可以傳送花卉分類要求至伺服器。用戶端是以 C++ 建置,以及利用 Triton 用戶端函式庫。它可以載入花卉影像的網格,並使用兩種方式進行推論:
- 互動模式:使用者選擇一張花卉影像,並從伺服器接收推論結果時,將會以非同步方式顯示。
- 自動模式:自動將一定數量的非同步推論要求保持於作用中。在每一次伺服器接收回覆時,都會建立新的要求。
此方式可以方便地從視覺上比較不同系統的延遲。如果設定固定的延遲預算,則會導致較快之系統、未完成要求的數量成比例增加。在指定的延遲預算中,可以有更多的要求在佇列中等待處理。

以下程式碼範例是顯示非同步 GRPC 推論要求建置的主要步驟。已省略某些程式碼,以突顯主要的操作。若需要更多資訊,請參閱 triton-inference-server/server GitHub 儲存庫。
#include "src/clients/c++/library/grpc_client.h"
#include "src/clients/c++/library/http_client.h"
#include "src/core/model_config.pb.h"
// Variable initialization
...
// Create the inference client for the server. From it,
// extract and validate that the model meets the requirements for
// image classification.
TritonClient triton_client;
nic::Error err;
err = nic::InferenceServerGrpcClient::Create(&triton_client.grpc_client_, url, verbose);
ModelInfo model_info;
ni::ModelMetadataResponse model_metadata;
err = triton_client.grpc_client_->ModelMetadata(&model_metadata, model_name, model_version, http_headers);
ni::ModelConfigResponse model_config;
err = triton_client.grpc_client_->ModelConfig(&model_config, model_name, model_version, http_headers);
// Preprocess the images into input data according to model requirements
std::vector <std::vector<uint8_t>> image_data;
...
// Initialize the inputs with the data.
nic::InferInput *input;
err = nic::InferInput::Create(&input, model_info.input_name_, shape, model_info.input_datatype_);
std::shared_ptr <nic::InferInput> input_ptr(input);
nic::InferRequestedOutput *output;
// Set the number of classifications expected
err = nic::InferRequestedOutput::Create(&output, model_info.output_name_, topk);
std::shared_ptr <nic::InferRequestedOutput> output_ptr(output);
std::vector < nic::InferInput * > inputs = {input_ptr.get()};
std::vector<const nic::InferRequestedOutput *> outputs = {output_ptr.get()};
// Configure context for 'batch_size' and 'topk'
nic::InferOptions options(model_name);
options.model_version_ = model_version;
// Send requests of 'batch_size' images. If the number of images
// isn't an exact multiple of 'batch_size' then just start over with
// the first images until the batch is filled.
//
// Number of requests sent = ceil(number of images / batch_size)
...
auto callback_func = ...
while (!last_request) {
// Reset the input for new request.
err = input_ptr->Reset();
// Set input to be the next 'batch_size' images (preprocessed).
std::vector <std::string> input_filenames;
for (int idx = 0; idx < batch_size; ++idx) {
input_filenames.push_back(image_filenames[image_idx]);
...
}
result_filenames.emplace_back(std::move(input_filenames));
options.request_id_ = std::to_string(sent_count);
err = triton_client.grpc_client_->AsyncInfer(
callback_func, options, inputs, outputs, http_headers);
sent_count++;
}
// Wait until all callbacks are invoked
...
// Post-process the results to make prediction(s)
...
請從 Docker Hub 下載已編譯的用戶端 GUI 容器。在下載容器執行用戶端之後,請從終端機輸入:
xhost +
docker run -it \
-v /tmp/.X11-unix:/tmp/.X11-unix:rw \
--privileged \
-e DISPLAY -e XAUTHORITY -e NVIDIA_DRIVER_CAPABILITIES=all \
-v $PWD:/workspace \
--device /dev/dri \
--net host dltme/triton_flower \ /workspace/build/FlowerDemo server_url server_grpc_port
將以開放原始碼形式發布至用戶端。
效能圖表
效能數據是透過執行 Triton perf_client 的方式取得。它可以產生對花卉模型的隨機資料推論要求,並測量傳輸量和延遲。若需要更多資訊,請參閱 perf_client。
perf_client 應用程式是使用模型上的最低負載,測量延遲和傳輸量,方式是傳送一個推論要求至 Triton,並等待回應。perf_client 在收到該回應之後,會立即傳送另一個要求,然後在測量視窗中重複此流程。預設並行,即未完成的推論要求數量為 1。
使用 –concurrency-range 選項,您可以同時開啟多個要求。Triton 會在伺服器端將已傳送,但是未立即執行的要求排入佇列。
perf_client 會針對各個要求並行層級,報告從用戶端看見的延遲和傳輸量。由於同時報告了基本組成部分,例如在佇列中花費的時間、運算推論需要的時間,因此可以進一步分析延遲。
透過增加並行要求的數量,將能發現伺服器至少在初始階段可以滿足升高的分類需求,進而提升整體傳輸量。超過閾值(這取決於伺服器上的許多因素,例如 GPU 類型和使用的 GPU 數量等)之後,傳輸量會達到最大值,因此被要求排入佇列,導致增加延遲。
請執行以下命令,以啟動 perf_client:
$ perf_client -m flower -u 127.0.0.1:50050 -i http --concurrency-range 1:100 -f results.csv
所有要求都會傳送至負責在可用之 Triton 執行個體之間進行最終分配的負載平衡器。gRPC 和 HTTP 要求都有可能。在本文章中,是針對 HTTP 要求取得基準。
圖 4 所示為使用不同數量之 MIG 1g.6gb 執行個體取得的傳輸量-並行曲線:
- A100-MIG7x1 僅呈現 1 個 MIG 1g.5gb 的傳輸量。
- A100-MIG7x7 呈現 7 個 MIG 1g.5gb 的傳輸量。
- V100 呈現在 V100 16Gb 上執行單一 Triton 執行個體時的傳輸量。
- T4 是 T4 的傳輸量曲線。
從圖中可見,增加更多 MIG 時,各個 MIG 的傳輸量提升幅度皆相同,且僅使用 2 個 MIG 即已超越 V100 或 T4 GPU。
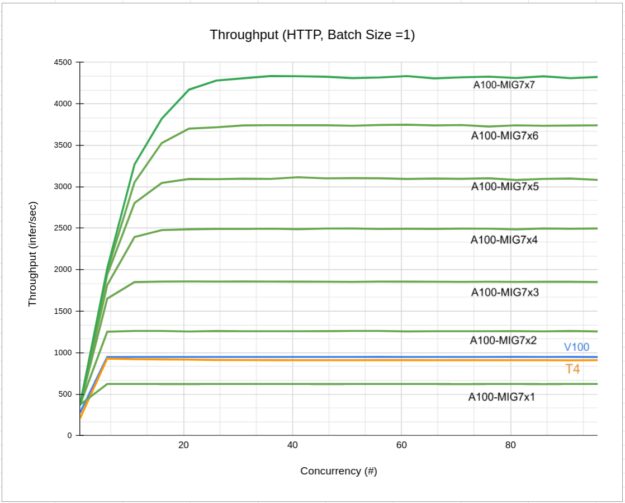
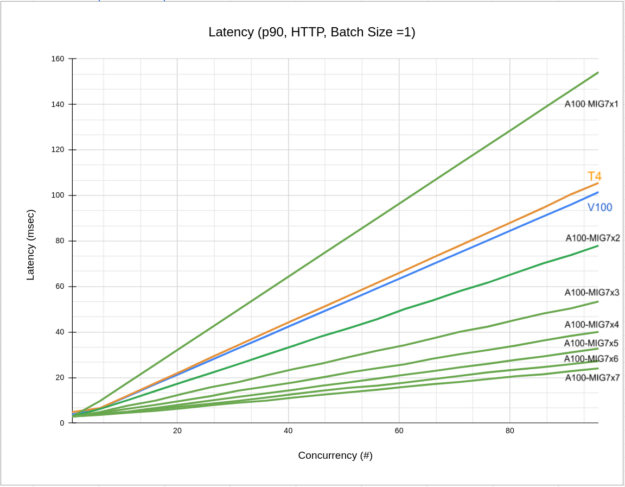
圖 5 所示為相同配置的延遲-並行關係。如圖表所示,使用的 MIG 執行個體數量增加時,延遲會降低。
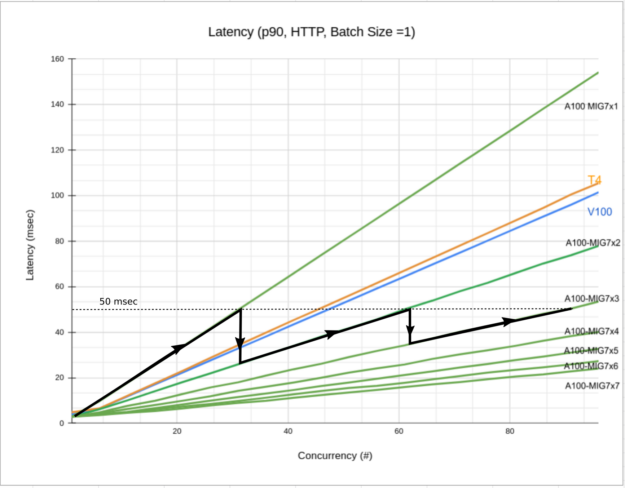
如圖 6 所示,延遲預算為 50 msec(水平虛線),從 1 個 MIG 開始逐漸增加並行要求數量時,延遲會提高(黑色實線)。未來,為了滿足您的需求,應增加 MIG 執行個體的數量。隨著執行個體數量的增加,系統延遲會下降,且將能夠滿足您的推論需求,同時將延遲維持在預算內。
結論
本文章介紹在 A100 上執行的花卉示範新版本。我們將系統部署在同類型(1g.5gb)的多個 MIG 執行個體上,以及說明傳輸量和延遲如何受影響,並與 V100 和 T4 結果比較。所述之系統為案例研究,說明在啟用 MIG 之 A100 上部署推論的基本原理。若需要更多資訊,請參閱 Getting the Most Out of the NVIDIA A100 GPU with Multi-Instance GPU。
您可以進一步利用 MIG 的靈活性,根據推論需求,自動增減花卉模型使用的執行個體數量。將可最佳化資源,且可能會釋放 MIG,以供其他應用程式或模型使用。在 Kubernetes 系統中輕鬆獲得自動擴充。