
推論,在應用上使用 AI 的工作成為主流,並且以前所未有的速度運行。
NVIDIA GPUs 在業界唯一以聯盟基礎和同行認定的最新一輪 MLPerf 基準測試中,贏得了所有資料中心和邊緣運算系統的 AI 推論測試。
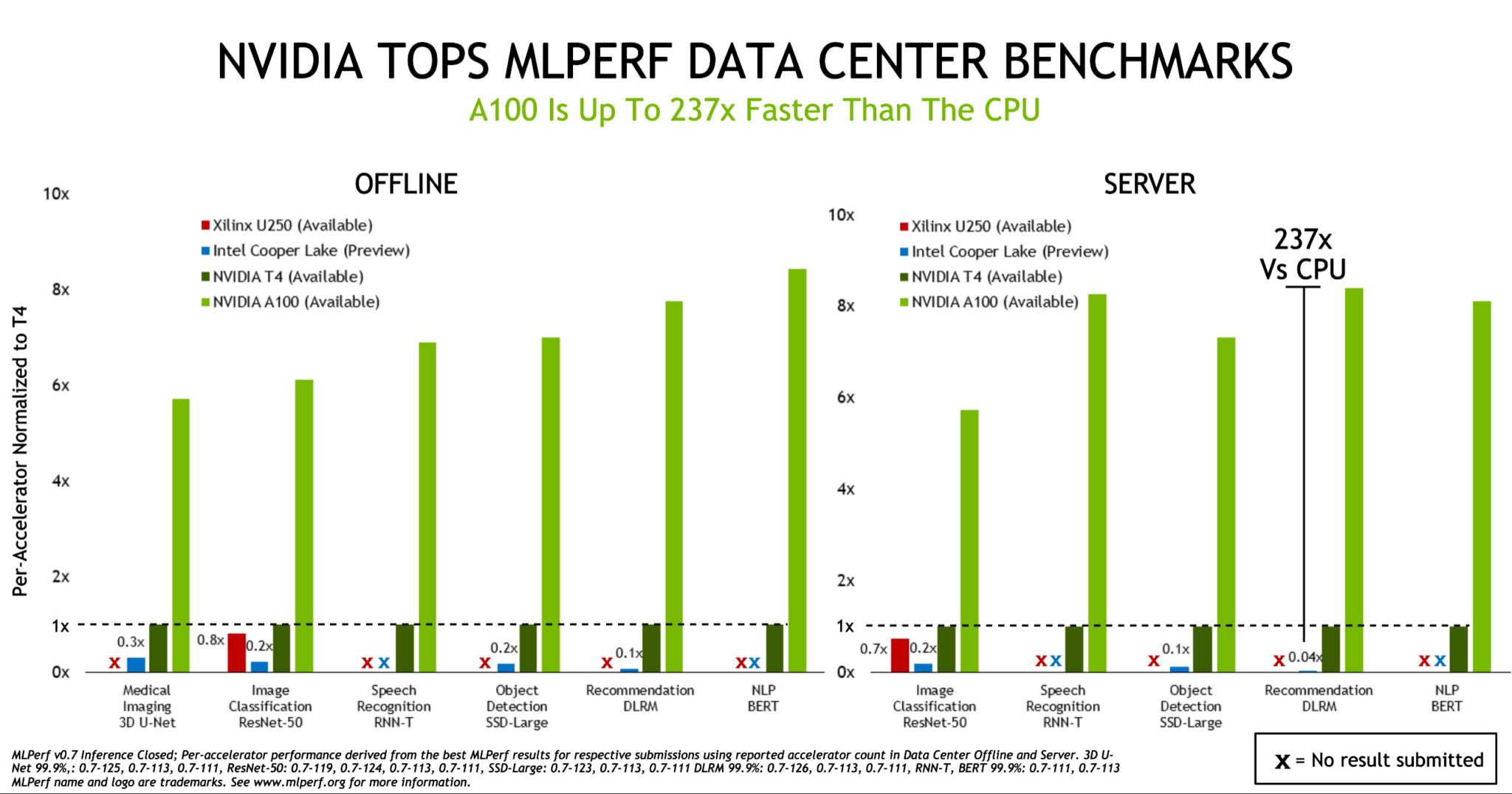
於 2018 年 5 月成立的 MLPerf 行業基準測試聯盟在去年舉行了首次 AI 推論測試 ,NVIDIA A100 Tensor Core GPUs展示了我們擴張的效能領導地位。
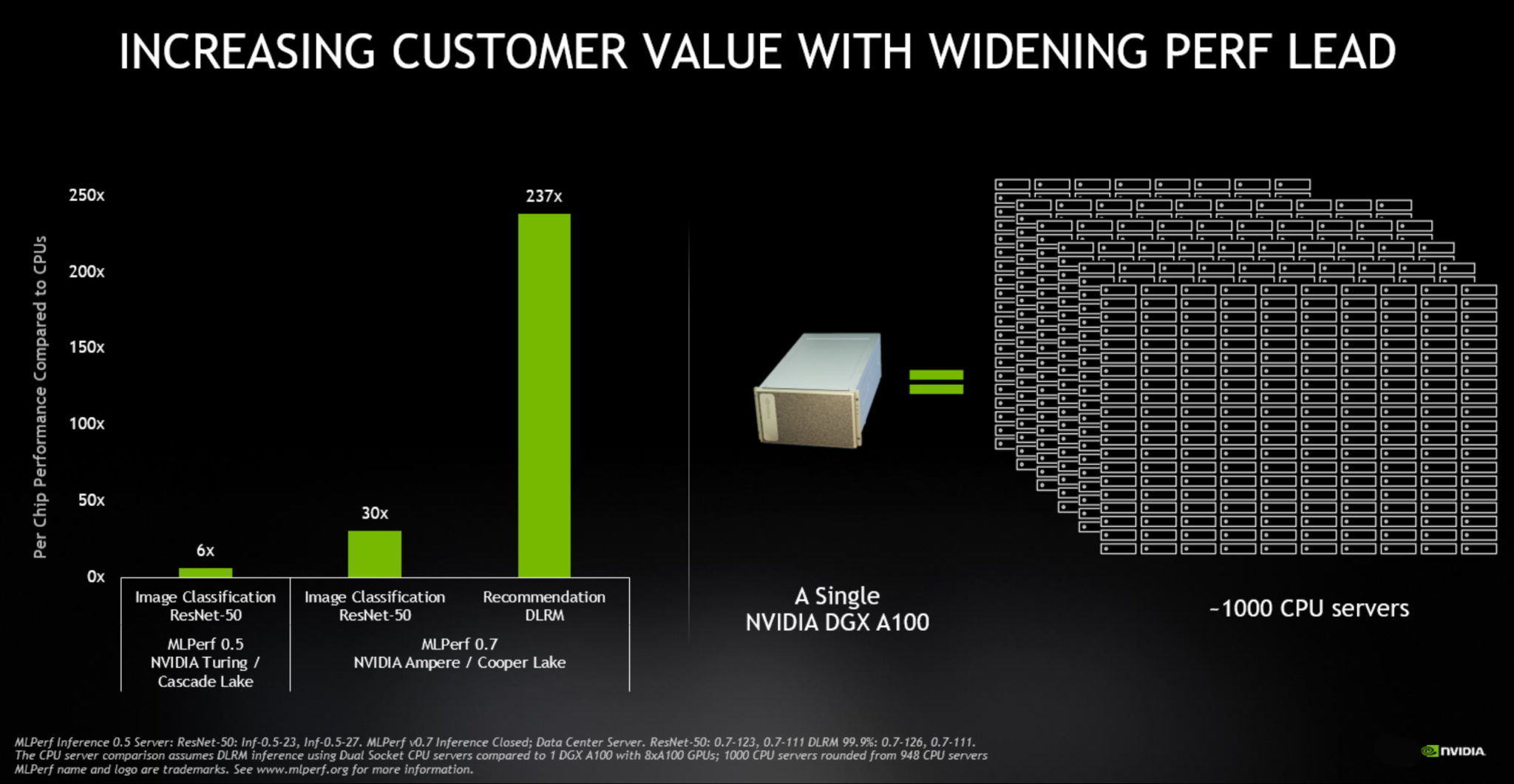
根據 MLPerf Inference 0.7 基準測試,5 月份推出的 A100 的資料中心推論效能比 CPU 高出 237 倍。在相同的測試中,封裝精巧 、更高能效的 NVIDIA T4 GPU 比 CPU 高出 28 倍。
從一個角度來看,一個帶有八個 A100 GPU 的 NVIDIA DGX A100 系統現在可以提供與某些AI應用程式中近 1,000 個雙插槽 CPU 服務器相同的效能。
與上一輪中有 12 個參賽者相比,這一輪基準測試參賽者也增加了,共有 23 個組織提交了該報告,並且 NVIDIA 合作夥伴使用 NVIDIA AI 平台提供了超過 85% 的提交文件。
NVIDIA A100 GPU,Jetson AGX Xavier 將效能帶到邊緣
雖然 A100 將 AI 推論效能提升到新的高度,但基準測試表明 T4 仍然是主流企業,邊緣伺服器和具有成本效益的雲端執行個體的可靠推論平台。此外,NVIDIA Jetson AGX Xavier 透過支援所有的使用案例,進一步鞏固了其在功耗受限、以單晶片為主的邊緣設備領導地位。
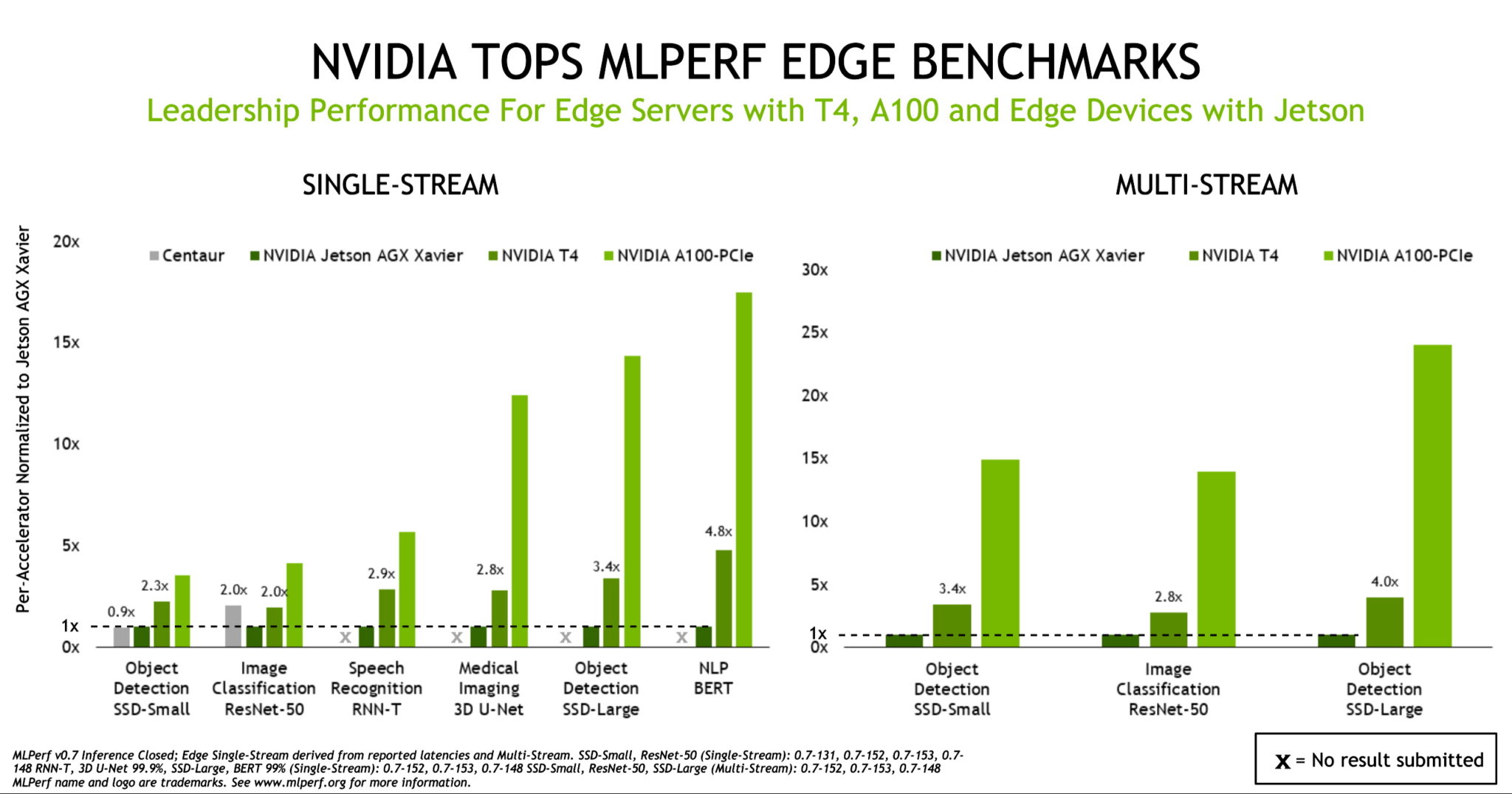
結果還劍指我們蓬勃發展的 AI 生態系統,使用 NVIDIA GPU 的生態圈夥伴提交了 871 個結果,佔資料中心和邊緣類別提交總數的 85% 以上。提交結果更展示我們合作夥伴在各個系統提供的穩定效能,包括 Altos,Atos,Cisco,Dell EMC,Dividiti,Fujitsu,技嘉,浪潮,聯想,Nettrix 和雲達科技。
擴展使用案例將 AI 帶入日常生活
在各行業和學術界的廣泛支持下,MLPerf 基準不斷發展代表著落實到業界使用案例。支持 MLPerf 的組織包括 Arm,百度,Facebook,Google,哈佛,Intel,聯想,微軟,史丹佛大學,多倫多大學和 NVIDIA。
最新的基準測試引入了四個新測試,突顯了 AI 不斷擴展的格局。該套件現在在自然語言處理,醫學影像,推薦系統和語音識別以及電腦視覺中的AI使用案例方面得分很高。
您只需要用搜索引擎就可以了解自然語言處理對日常生活的影響。
“最近在自然語言理解方面的 AI 突破使 Bing 等越來越多的 AI 服務可以更自然地互動,並在不到一秒鐘的時間內提供了準確,有用的結果,答案和建議,” 微軟的搜索引擎和人工智慧副總裁 Rangan Majumder 說道。
他說:“業界標準的 MLPerf 基準測試提供了廣泛使用的 AI 網路上的相關效能資料,並有助於做出明智的 AI 平台購買決策。”
人工智慧幫助挽救新冠肆虐下的生命
人工智慧在醫學成像中的影響甚至更大。例如,新創公司 Caption Health 使用 AI 簡化了獲取超聲心動圖的工作,該功能有助於在新冠大流行初期美國醫院的挽救生命工作。
這就是為什麼醫療保健 AI 的思想領袖將像 3D U-Net 這樣的模型用作最新的 MLPerf 基準測試的原因。
“我們與 NVIDIA 緊密合作,將 3D U-Net 等創新技術導入醫療保健市場,”德國癌症研究中心 DKFZ 的醫學圖像運算主管 Klaus Maier-Hein 說。
“電腦視覺和影像技術是 AI 研究的核心,推動了科學發現並代表了醫療保健的核心組成。業界標準的 MLPerf 基準提供了相關的效能資料,可幫助 IT 組織和開發人員加速其特定專案和應用程式。”
在商業上,像推薦系統這樣的 AI 應用,也是最新 MLPerf 測試的一部分,已經產生了巨大影響。去年 11 月,阿里巴巴使用推薦系統在“光棍節”這一年最大的購物日實現了 380 億美元的網購銷售額。
NVIDIA AI 推論的採用通過了臨界點
AI 推論在今年突破了一個里程碑。
在過去的 12 個月中,NVIDIA GPU 在公有雲中總共提供了超過 100 exaflops 的 AI 推論效能,首次超過了雲端 CPU 所提供的服務。每兩年,雲端 GPU上 的推論吞吐量大約增長了十倍。
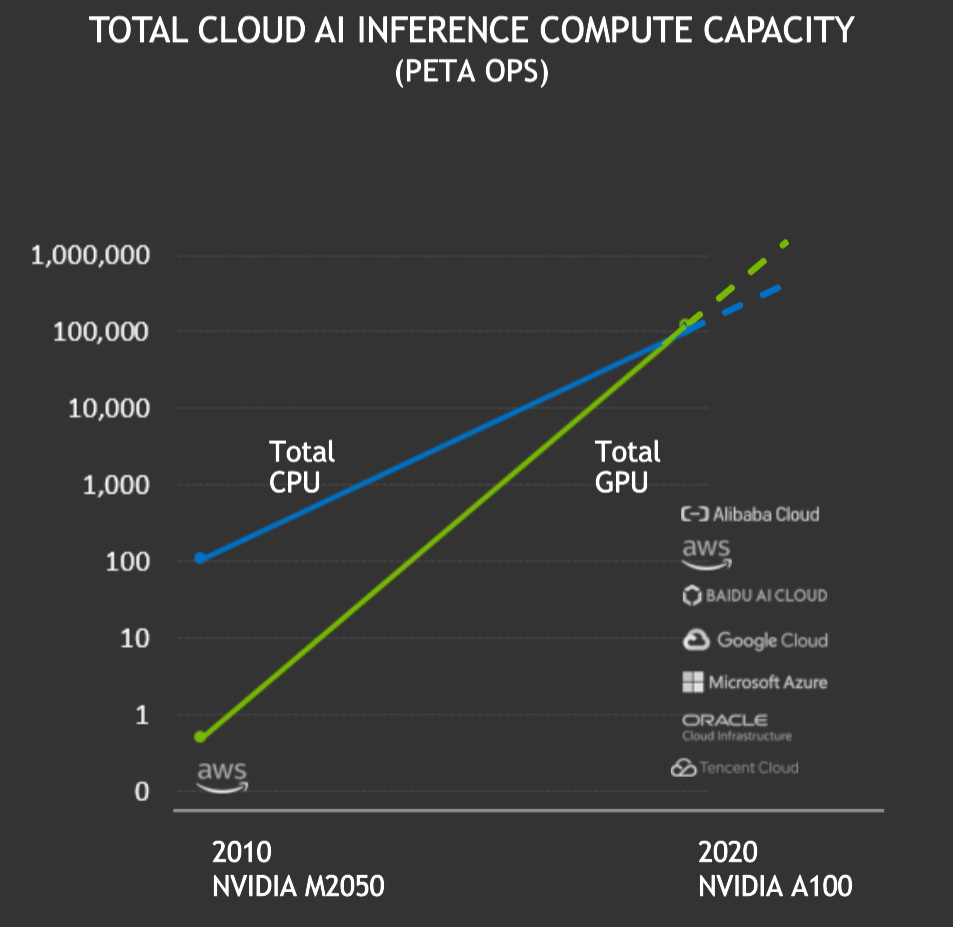
憑藉 NVIDIA GPU 的高效能運算,易用性和可用性,汽車,雲端,機器人,醫療保健,零售,金融服務和製造等行業中越來越多的公司現在都依賴 NVIDIA GPU 進行 AI 推論。它們包括美國運通、BMW、Capital One、達美樂、福特、GE Healthcare、克羅格、微軟、三星和豐田。

為什麼 AI 推論很難
AI 的使用案例顯然正在擴展,但是由於許多原因,AI 推論很難。
像用於生成對抗網路的新案例產生的新型神經網路不斷湧現,並且模型都呈現指數型的增長。使用 AI 的最佳語言模型包含數十億個參數,但該領域的研究仍處於起步階段。
這些模型需要在雲端,在企業資料中心和在網路邊緣中運行。這意味著運行它們的系統必須是高度可編程的,並且在許多方面都必需具備出色的執行力。
NVIDIA 創辦人暨執行長黃仁勳將種種複雜性壓縮成一個詞:PLASTER。現代 AI 推論需要出色的可編程性、延遲性、準確性,規模、處理量、用電能效與學習速度。
為了在各方面表現突出,我們專注於不斷發展我們的端到端AI平台,以處理要求苛刻的推論工作。
人工智慧需要高效能和易用性
像 A100 一樣的加速器,具有其第三代 Tensor Cores 和其多執行個體 GPU 架構的靈活性,僅僅是個開始。要達成優異的效能表現需要完整的軟體堆疊。
NVIDIA 的 AI 軟體從各種預先訓練好的模型開始,可以運行 AI 推論。我們的 TAO Toolkit 使用者可以針對其特定使用案例和資料集優化這些模型。
NVIDIA TensorRT 優化了已訓練的推論模型。進行了 2,000 次優化,已被 16,000 個組織下載了 130 萬次。
最後,NVIDIA Triton Inference Server 提供了經過優化的環境,可以運行支援多個 GPU 和框架的這些 AI 模型。應用程式只發送查詢和約束-例如它們所需的回應時間或吞吐量以擴展到成千上萬的用戶,而 Triton 負責執行這些作業。
這些元素運行在 CUDA-X AI之上,CUDA-X AI 是基於我們廣泛普及的加速運算平台的一套成熟的軟體函式庫。
快速啟動應用程式框架
最後,我們的應用程式框架可促進跨不同行業和使用案例的企業快速導入 AI。
我們的框架包括用於推薦系統的 NVIDIA Merlin,用於對話式 AI 的 NVIDIA Riva,用於視訊會議的 NVIDIA Maxine,用於醫療保健的 NVIDIA Clara,以及許多其他產品。
這些框架以及我們對最新 MLPerf 基準的優化,可在我們的GPU 加速軟體中心 NGC 及所有 NVIDIA 認證的 OEM 系統和雲端服務上取得。
通過這些方式,我們所有的努力將使整個社區受益。