Windows PC 上的人工智慧(AI)標誌著科技史上的關鍵時刻,它將徹底改變玩家、創作者、直播主、上班族、學生乃至普通 PC 用戶的體驗。
AI 為 1 億多台採用 RTX GPU 的 Windows PC 和工作站提高生產力,帶來前所未有的機會。NVIDIA RTX 技術使開發者更輕鬆地創建 AI 應用,從而改變人們使用電腦的方式。
在微軟 Ignite 大會上發布的全新最佳化、模型和資源,將讓開發者可以更快提供新的終端使用者體驗。
TensorRT-LLM 是一款提升 AI 推論效能的開源軟體,它即將發布的更新版將支持更多大型語言模型,可在 RTX GPU 8GB VRAM 以上的 PC 和筆記型電腦上,使要求嚴苛的 AI 工作負載更容易完成。
Tensor RT-LLM for Windows 即將透過全新封裝介面與 OpenAI 廣受歡迎的聊天 API 相容。這將使數以百計的開發者專案和應用能在 RTX PC 的本地運行,而非雲端運行,因此用戶可以在 PC 上保留私人和專有資料。
客製的生成式 AI 需要時間和精力來維護專案。特別是跨多個環境和平臺進行協作和部署時,該過程可能會異常複雜和耗時。
NVIDIA 資料科學工作台(AI Workbench) 是一個統一、易用的工具包,允許開發者在 PC 或工作站上快速建立、測試和客製預先訓練的生成式 AI 模型和 LLM。它為開發者提供一個單一平臺,用於組織他們的 AI 專案,並根據特定使用者需求來調整模型。
這使開發者能夠進行無縫協作和部署,快速創建具有成本效益、可擴展的生成式 AI 模型。歡迎加入搶先體驗名單,成為首批用戶以率先瞭解不斷更新的功能,並接收更新資訊。
為支援 AI 開發者,NVIDIA 與微軟共同發布 DirectML 增強功能以加速 Llama 2,時下最熱門的基礎 AI 模型之一。除了制定一個全新的效能標準,開發者現在亦有更多跨供應商部署可選擇。
可攜式 AI
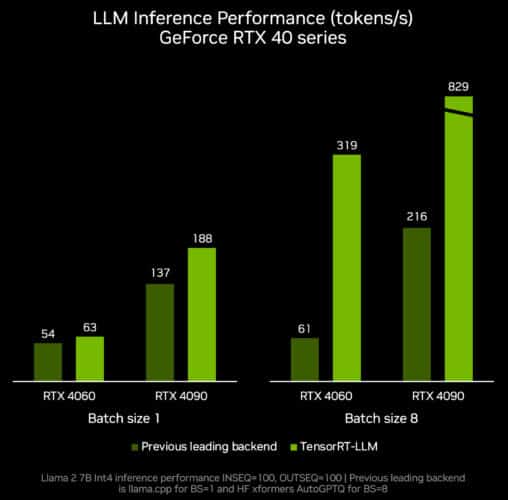
NVIDIA 於 10 月發布了用於加速大型語言模型(LLM)推理的函式庫 TensorRT-LLM for Windows。
本月底發布的 TensorRT-LLM v0.6.0 更新將帶來高達 5 倍的推論效能提升,並支援更多熱門的 LLM,包括全新 Mistral 7B 和 Nemotron-3 8B。這些 LLM 版本將可在所有採用 8GB 記憶體以上的 GeForce RTX 30 系列和 40 系列 GPU 上運行,從而使最輕便的 Windows PC 設備也能具備於本地快速且準確運行 LLM 的功能。
新發布的 TensorRT-LLM 可在 /NVIDIA/TensorRT-LLM GitHub 儲存庫中下載安裝,全新最佳化的模型將提供於 ngc.nvidia.com。
實現從容對話
世界各地的開發者和愛好者將 OpenAI 的聊天 API 廣泛用於各種應用,包括總結網頁內容、起擬文件草稿和電子郵件、分析並視覺化資料、製作簡報等。
這類以雲端為基礎的 AI 面臨的一大挑戰在於它們需要使用者上傳輸入資料,因此對於私人或專有資料或處理大型資料集而言並不實用。
為應對這一挑戰,NVIDIA 即將啟用 TensorRT-LLM for Windows,藉由全新封裝器提供與 OpenAI 廣受歡迎的 ChatAPI 類似的 API 介面,為開發者帶來類似的工作流程,無論他們設計的模型和應用要在 RTX PC 的本地運行、在雲端運行,只需修改一到兩行代碼,數百個 AI 驅動的開發者專案和應用現在就能從快速的本地 AI 中受益。使用者可將資料保存在 PC 上,不必擔心將資料上傳到雲端。
此外,最重要的一點是這些項目和應用中有很多都是開源的,開發者可以輕鬆利用和擴展它們的功能,從而加速生成式 AI 在 RTX 驅動的 Windows PC 上的應用。
該封裝器可與所有對 TensorRT-LLM 進行最佳化的 LLM(如:Llama 2、Mistral 和 NV LLM)配合使用,並作為參考專案在 GitHub 上發布,同步也將發布可以在 RTX 上使用 LLM 的其他開發者資源。
模型加速
開發者現可利用尖端的 AI 模型,並透過跨供應商 API 進行部署。NVIDIA 和微軟一直致力於增強開發者能力,透過 DirectML API 在 RTX 上加速 Llama。
在 10 月已宣布,在為這些模型提供最快推論效能的基礎上,此項跨供應商部署的全新選項將使 AI 功能導入 PC 變得前所未有的簡單。
開發者和愛好者可下載最新的 ONNX 執行時間、依照微軟的安裝說明進行操作,並安裝最新 NVIDIA 驅動程式(將於 11 月 21 日發佈),以獲得最新的最佳化體驗。
這些全新的最佳化、模型和資源將加速 AI 功能和應用在全球 1 億台 RTX PC 上的開發和部署,同時加入了 400 多個合作夥伴的行列,這些夥伴皆已推出由 RTX GPU 加速的 AI 驅動的應用和遊戲。
隨著模型易用性的提高,而開發者將更多生成式 AI 功能帶到 RTX 驅動的 Windows PC 上,RTX GPU 將成為用戶採用這一強大技術的關鍵。