
NVIDIA GH200 Grace Hopper 超級晶片 首次亮相於 MLPerf 產業基準測試中,在所有人工智慧推論加速器測試中均表現優異,進一步擴展了NVIDIA H100 Tensor Core GPU 的領先效能。
這些結果還展示了 NVIDIA 人工智慧平台在從雲端到網路邊緣的卓越性能和多功能性。
NVIDIA 另外宣布推出推論軟體,能讓使用者在效能、能源效率和總持有成本方面上得到顯著的提升。
GH200 超級晶片在 MLPerf 基準測試中表現優異
GH200 連結Hopper GPU 和 Grace CPU 成為一個超級晶片。這個組合能提供更多記憶體、頻寬,以及能在 CPU 和 GPU 之間自動調節電力,以最佳化表現。
此外,配備 8 個 H100 GPU 的 HGX H100 系統在本輪每個 MLPerf 推論測試中提供了最高的吞吐量。
Grace Hopper 超級晶片和 H100 GPU 在所有 MLPerf 的資料中心測試中處於領先地位,包括電腦視覺推論、語音識別和醫學成像,以及要求更高的推薦系統應用案例和生成式人工智慧中使用的大型語言模型 (LLMs)。
總體來說,這次測試結果延續了 NVIDIA 自 2018 年 MLPerf 基準推出以來,在每輪人工智慧訓練和推論方面效能領先的記錄。
最新的 MLPerf 測試中包括對推薦系統的更新測試,以及首次針對 GPT-J 進行的推論基準測試。GPT-J 是一個具有 60 億參數的大型語言模型,而參數是用來衡量人工智慧模型大小的粗略指標。
TensorRT-LLM 大幅提升推論效能
為了減少各種規模的複雜工作負載,NVIDIA 開發了 TensorRT-LLM,這是一種可最佳化推論的生成式人工智慧軟體。這個開源程式碼在八月向 MLPerf 提交測試結果時尚未完成,能使客戶能夠在無額外成本的情況下,將其已購買的 H100 GPU 的推論效能提高一倍以上。
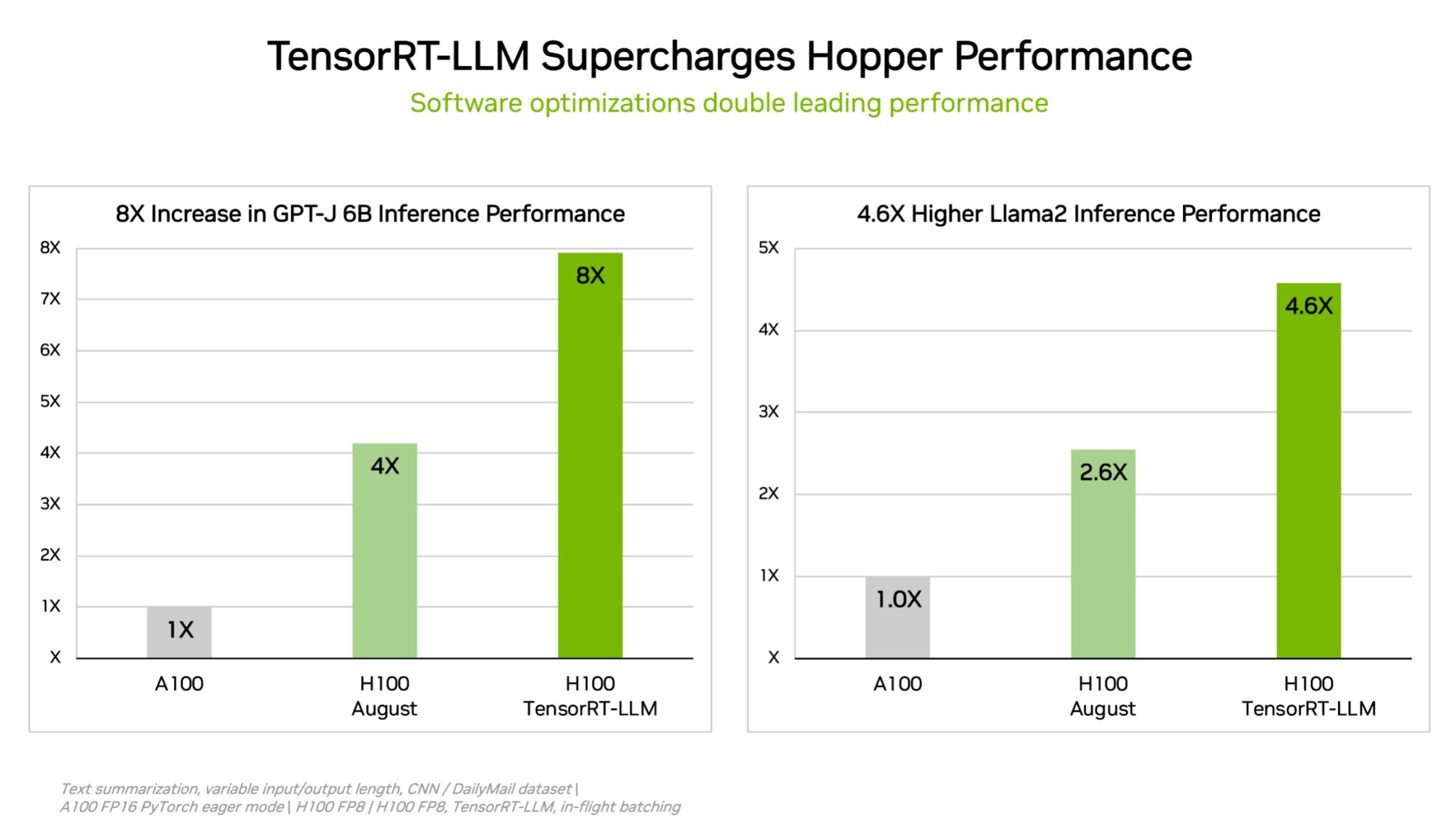
NVIDIA 內部測試顯示,在 H100 GPU 上使用 TensorRT-LLM,與以前的 GPU 運行 GPT-J 6B 相比,效能提升高達 8 倍。
這個軟體源於 NVIDIA 與業界領先公司的合作,包括 Meta、AnyScale、Cohere、Deci、Grammarly、Mistral AI、MosaicML(現為 Databricks 的一部分)、OctoML、Tabnine 和 Together AI,以加速和最佳化大型語言模型推論的過程。
MosaicML 在 TensorRT-LLM 的基礎上增加所需的功能,並將其納入現有的服務堆疊。Databricks 工程部門副總裁 Naveen Rao 指出:「這絕對是一件輕而易舉的事。」
「TensorRT-LLM 簡單易用、功能多樣且相當有效率。它為使用 NVIDIA GPU 的大型語言模型服務提供了最先進的效能,讓我們能夠把省下來的成本回饋給客戶。」Rao 說。
TensorRT-LLM 是 NVIDIA 全端 AI 平台持續不斷創新的最新範例。這些不斷升級的軟體為用戶提供了可隨時間增長的性能,而無需額外成本,並且能適應當今多樣化的人工智慧工作負載。
L4 提升主流伺服器的推論效能
在最新的 MLPerf 基準測試中,NVIDIA L4 GPU 在各種工作負載上表現卓越,提供全面性的出色性能。
例如,L4 GPU 運行在精巧、功耗為 72W 的轉接卡上,與功耗高出近 5 倍的 CPU 相比較,L4 GPU 提供高出 6 倍效能。
除此之外,L4 GPU 內建專屬的媒體引擎,在 NVIDIA 的測試中與 CUDA 軟體合用能加速電腦視覺應用達 120 倍。
目前可以從 Google Cloud 和許多系統製造商端使用 L4 GPU。它們為從消費者網路服務到藥物研發等多個產業的客戶提供服務。
在邊緣環境中效能提升
此外,NVIDIA 應用了新的模型壓縮技術,使在 L4 GPU 上運行 BERT LLM 的效能提升達 4.7 倍。這一結果在 MLPerf 的所謂開放組別(Open Division)中實現,這是用於展示新能力的一個類別。
該技術預計將適用於所有人工智慧工作負載。當在尺寸和功耗受限的邊緣設備上運行模型時,它尤其有價值。
在另一個邊緣運算領先範例中,NVIDIA Jetson Orin 系統模組顯示物件偵測的效能相對前一輪測試提升高達 84%,這是邊緣人工智慧和機器人場景中常見的電腦視覺使用案例。
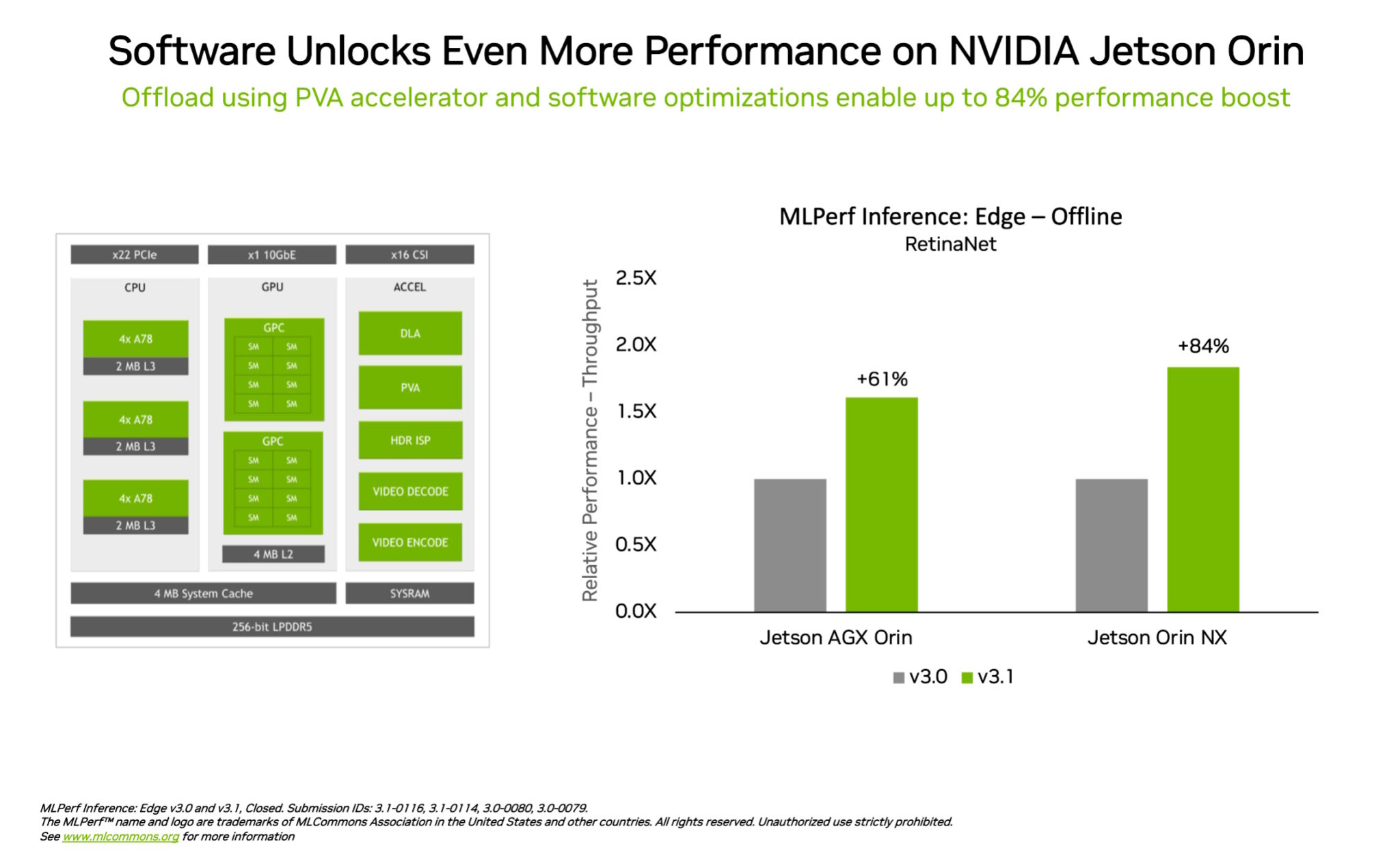
Jetson Orin 的先行產品來自採用最新版晶片核心的軟體,如可程式設計視覺加速器、NVIDIA Ampere 架構 GPU 和專用深度學習加速器。
多功能的效能,廣大的生態系統
MLPerf 基準是透明且客觀的,因此使用者可以依靠其結果做出明智的購買決策。它們涵蓋了廣泛的應用案例和情景,因此使用者知道他們可以獲得可靠且部署靈活的效能。
在本輪測試中參與提交的合作夥伴包括雲端服務供應商Microsoft Azure和Oracle Cloud Infrastructure,以及華碩電腦、Connect Tech、戴爾科技集團、富士通公司、技嘉科技、慧與科技、聯想集團、雲達科技和美超微等系統製造商。
總體來說,MLPerf 得到了超過 70 家組織的支持,包括阿里巴巴、Arm、思科、Google、哈佛大學、英特爾、Meta、微軟和多倫多大學等。
欲瞭解更多詳細資訊以及我們如何獲得這些成果,請閱讀技術部落格文章。
於此次測試中使用的各種軟體公開於 MLPerf 資源庫,每個人都能取得這些世界級的成果。我們不斷將最佳化結果放入 NVIDIA NGC (GPU 加速軟體目錄)的容器中,提供 GPU 應用。