近年來,Transformer 已成為強大的深度神經網路架構,且經證實在許多應用領域中已超越最先進的技術,例如自然語言處理(natural language processing,NLP)和電腦視覺。
本文會揭露如何在微調 Transformer 時,以最快的訓練時間達到最高準確度。我們將證明來自 RAPIDS 機器學習函式庫的 cuML 支援向量機(support vector machine,SVM)演算法,可以大幅加快此過程。GPU 上的 CuML SVM 比以 CPU 為基礎的建置快 500 倍。 此方法是使用 SVM 取代傳統的多層感知(multi-layer perceptron,MLP),可以精準且輕鬆地進行微調。
何謂微調?為何需要進行微調?
Transformer 是一種由多數多頭、自我注意力和前饋全連接層組成的深度學習模型。主要用於序列對序列任務,包括機器翻譯、問題回答等 NLP 任務,以及物件偵測等電腦視覺任務。
從零開始訓練 Transformer 是一種運算密集型過程,通常需要幾天甚至幾週的時間。實際上,微調是將經過預先訓練之 Transformer 應用微調於新的任務,進而縮短訓練時間之最有效率的方式。
使用多層感知(MLP)微調 Transformer
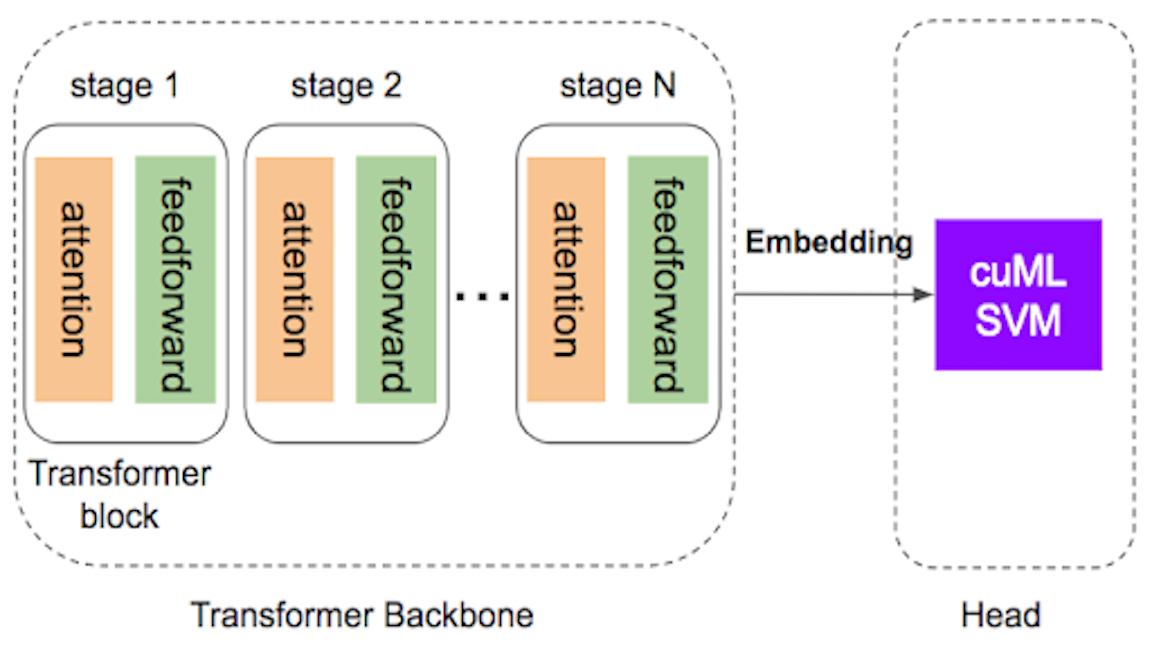
如圖 1 所示,Transformer 具有兩個不同的元件:
- 骨幹,包含多個自我注意力和前饋層區塊。
- 頭部,針對分類或迴歸任務進行最終預測。
在微調過程中,凍結 Transformer 的骨幹網路,僅會訓練輕量頭部模組執行新的任務。在分類和迴歸任務方面,頭部模組最常見的選擇是多層感知(MLP)。
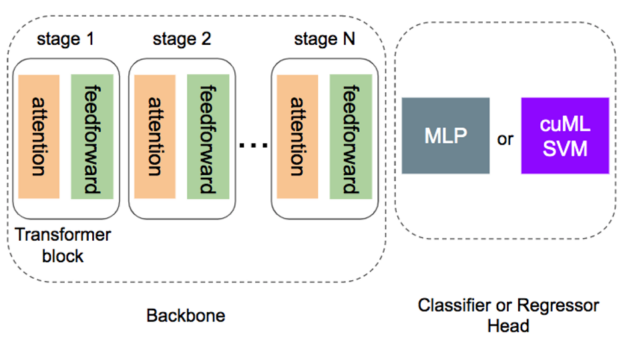
事實證明,建置和調整 MLP 可能比想像中困難許多。為什麼?
- 需要調整多個超參數:層數、丟棄、學習率、正則化、最佳化器類型等。選擇需要調整的超參數,是取決於需要解決的問題。例如,丟棄、批次正規化等標準技術可能會導致降低迴歸問題的效能。
- 必須付出更多努力以防止過度適配(Overfitting)。Transformer 的輸出通常是一種很長的嵌入向量,長度從數百到數千不等。訓練資料的大小不足時,很常見過度適配。
- 執行時間方面的效能通常未進行最佳化。使用者必須編寫資料處理和訓練的樣板程式碼。批次產生以及從 CPU 到 GPU 的資料移動也可能會成為效能瓶頸。
使用支援向量機(SVM)微調 Transformer 的優勢
支援向量機(SVM)是最熱門的監督式學習方法之一,在有可用之有意義的預測功能時最有效。尤其是高維度資料,因為 SVM 可以有效防止過度適配。
但是,有時候資料科學家會對於嘗試 SVM 感到猶豫,原因如下:
- 需要很難執行的手工特徵工程。
- SVM 通常很慢。
RAPIDS cuML 在 GPU 上提供高達 500 倍的加速,激發人們重新探索此傳統模型的興趣。在擁有 RAPIDS cuML 之後,SVM 於資料科學界中再次流行。
例如,在幾個 Kaggle 競賽中經常使用到 RAPIDS cuML SVM notebook:
由於 Transformer 已經學會以長嵌入向量之形式擷取有意義的表示,因此 cuML SVM 是頭部分類器或迴歸器的理想選擇。
相較於 MLP 頭部,cuML SVM 的優勢如下:
- 易於調整。事實上,我們發現在大多數情況下,對於 SVM 而言,調整一個參數 C 已經足夠。
- 速度。cuML 可以一次將所有的資料移動至 GPU,然後在 GPU 上處理。
- 多樣性。在統計上,SVM 的預測與 MLP 預測不同,因此在整體中很實用。
- API 簡單。cuML SVM API 提供 scikit-learn 樣式的適配和預測功能。
案例研究:PetFinder.my Pawpularity Contest
此種採用 SVM 頭部的建議微調方法,適用於 NLP 和電腦視覺任務。為了進行證明,我們研究了 PetFinder.my Pawpularity Contest,這是一項根據相片預測收容所寵物之受歡迎度的 Kaggle 資料科學競賽。
此專案的資料集是由 10,000 張手動標籤化影像組成,每一張影像都具有我們將要預測的目標 pawpularity。pawpularity 值從 0 到 100 不等,我們是使用迴歸解決此問題。由於僅有 10,000 張標籤化影像,因此,從零開始訓練深度神經網路以達到高準確度是不切實際的方式。我們改採使用經過預先訓練的 swin transformer 骨幹,然後使用標籤化寵物影像進行微調的方法。
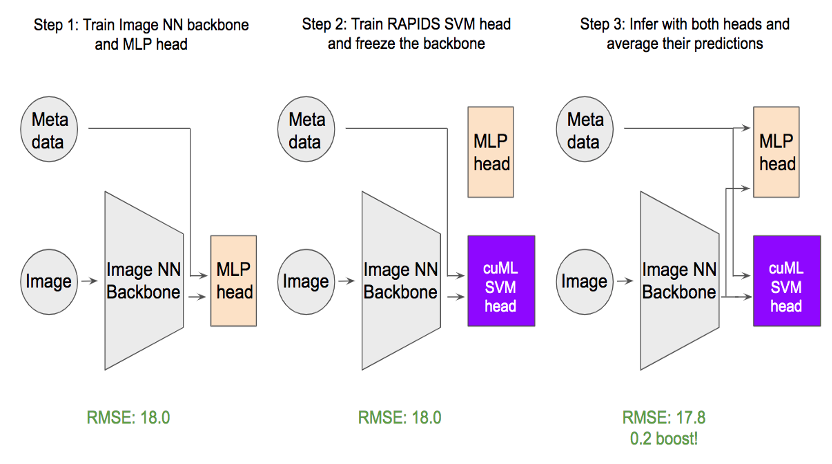
如圖 2 所示,我們的方法需要三個步驟:
- 首先,將使用 MLP 的迴歸頭部新增至骨幹 swin transformer,然後微調骨幹和頭部。有趣的是,由於目標分布,使二元交叉熵損失優於常見的均方誤差損失(mean squared error,MSE)。
- 之後,凍結骨幹,並將 MLP 頭部換成 cuML SVM 頭部。然後以標準的 MSE 損失訓練 SVM 頭部。
- 為了達到最佳的預測準確度,我們計算了平均的 MLP 頭部與 SVM 頭部。評估度量根表示平方誤差從 18 最佳化至 17.8,對於此資料集而言很重要。
值得一提的是步驟 1 和 3 為可選的,且已在此處執行,以最佳化模型在此競賽中的得分。步驟 2 是最常見的微調情境。因此,我們測量步驟 2 的執行階段,並比較了三個選項:cuML SVM (GPU)、sklearn SVM (CPU) 與 PyTorchMLP (GPU)。結果如圖 3 所示。
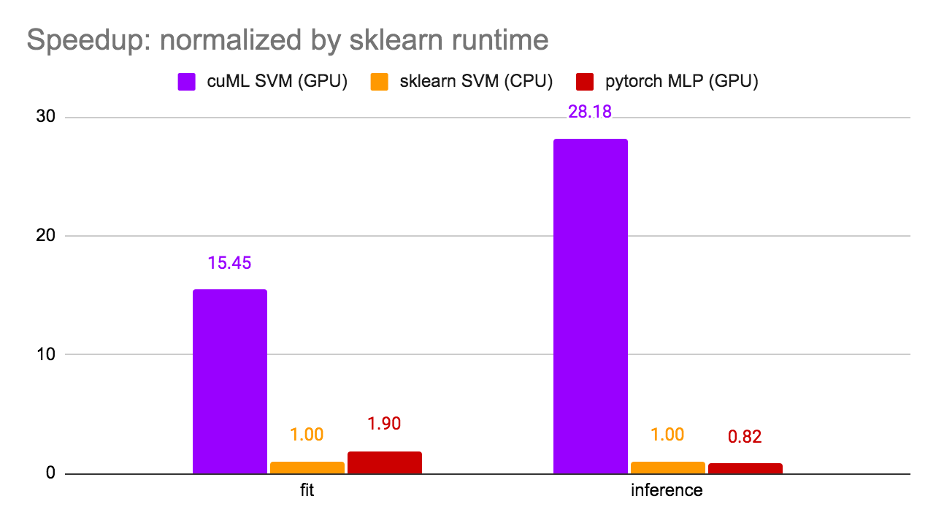
sklearn SVM 和 cuML SVM 執行階段正規化,使訓練加快 15 倍,使推論加快 28.18 倍。值得一提的是,由於 GPU 的利用率高,使cuML SVM 比 PyTorch MLP 更快。在 Kaggle 上可以找到相關筆記。
Transformer 微調的主要重點
Transformer 是革命性的深度學習模型,但是需要長時間訓練。在 GPU 上快速微調 Transformer 可以提供明顯的加速效果,以使許多應用程式受益。同時可以直接使用 RAPIDS cuML SVM 取代傳統的 MLP 頭部,因為它更快速及更準確。
GPU 加速可以為 SVM 等傳統機器學習模型注入新能量。利用 RAPIDS,可以結合兩者的優點:傳統的機器學習模型與最先進的深度學習模型。在 RAPIDS cuML 中,有更多快如閃電及易於使用的模型。
後記
在撰寫和編輯此文章時,PetFinder.my Pawpularity Contest 已經結束。NVIDIA KGMON Gilberto Titericz 使用 RAPIDS SVM 贏得第一名。他獲勝的解決方案,是將來自 Transformer 及其他深度 CNN 的嵌入集中,並使用 RAPIDS SVM 做為迴歸頭部。若需更多資訊,請參閱他的獲勝解決方案寫法。