
從製造汽車到協助外科醫師和運送披薩,機器人不僅自動化,且能將人工任務加快數倍。隨著 AI 問世,您可以打造出能更有效地感知周圍環境,並在幾乎不需要人為介入下做出決定之更智慧化的機器人。
以在倉庫中移動裝載物的自主機器人為範例。它必須感知周圍的自由空間、偵測和避開路徑中的任何障礙物,並做出「即時」決定,毫無延遲地挑選出新路徑。
這就是挑戰。表示需要建構由經過訓練和最佳化,可以在該環境中運作之 AI 模型驅動的應用程式。其必須收集大量的高品質資料,並開發出高度準確的 AI 模型以驅動應用程式。這些是將應用程式從實驗室轉移至實際環境時面臨的主要障礙。
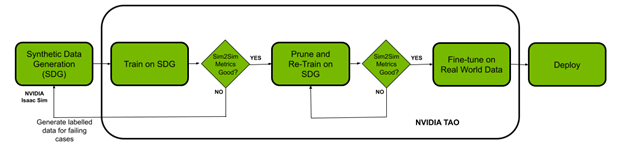
本文說明如何使用 NVIDIA Isaac 平台和 TAO 框架解決資料挑戰和模型建立挑戰。使用機器人模擬應用程式 NVIDIA Isaac Sim 建立虛擬環境,並產生合成資料。NVIDIA TAO 工具套件是具有內建轉移學習的低程式碼 AI 模型開發解決方案,相較於從零開始訓練,可以使用一小部分的資料微調預先訓練模型。最後,使用 NVIDIA Isaac ROS 將最佳化模型部署至機器人上,並在真實世界中啟用。
先決條件
在開始之前必須具備下列資源,才能進行訓練和部署:
- NVIDIA GPU 驅動程式版本:>470
- NVIDIA Docker:2.5.0-1
- 雲端或內部部署 NVIDIA GPU:
- NVIDIA A100
- NVIDIA V100
- NVIDIA T4
- NVIDIA RTX 30×0(NVIDIA Isaac Sim 可支援 NVIDIA RTX 20 系列)
- NVIDIA Jetson Xavier 或 Jetson Xavier NX
- NVIDIA TAO 工具套件:4.22。若需要更多資訊,請參閱 TAO 工具套件快速入門指南
- NVIDIA Isaac Sim 和 Isaac ROS
使用 NVIDIA Isaac Sim 產生合成資料
本節概述在 NVIDIA Isaac Sim 中產生合成資料的步驟。合成資料是電腦模擬或演算法產生的加註資訊。在難以取得真實資料或取得成本昂貴時,合成資料可以協助解決資料挑戰。
NVIDIA Isaac Sim 提供三種產生合成資料的方法:
- Replicator 編譯器
- Python 指令碼
- GUI
於此示範中,我們選擇使用 Python 指令碼,透過領域隨機化(domain randomization)產生資料。領域隨機化會改變在模擬環境中定義場景的參數,包括場景中各種物件的位置、比例,以及模擬環境的光照、物件的色彩和紋理等。
增加領域隨機化以同時改變場景的許多參數,可以提高資料集的品質,並將模型暴露在真實世界中的各種領域參數下,以提升模型的效能。
於此範例中,使用兩種環境訓練資料:倉庫和小房間。後續步驟包括將符合物理定律的物件加入場景中。我們使用來自於 NVIDIA Isaac Sim 的範例物件,包括來自 YCB 資料集的日常物件。

在安裝 NVIDIA Isaac Sim 後,Isaac Sim App Selector 提供了一個在資料夾中開啟的選項,包含 python.sh 指令碼。其可用於執行指令碼以產生資料。
依據列出的步驟產生資料。
選擇環境以及為場景新增攝影機
def add_camera_to_viewport(self):
# Add a camera to the scene and attach it to the viewport
self.camera_rig = UsdGeom.Xformable(create_prim("/Root/CameraRig", "Xform"))
self.camera = create_prim("/Root/CameraRig/Camera", "Camera")
為地板新增語意 ID:
def add_floor_semantics(self):
# Get the floor from the stage and update its semantics
stage = kit.context.get_stage()
floor_prim = stage.GetPrimAtPath("/Root/Towel_Room01_floor_bottom_218")
add_update_semantics(floor_prim, "floor")
透過物理在場景中新增物件:
def load_single_asset(self, object_transform_path, object_path, usd_object):
# Random x, y points for the position of the USD object
translate_x , translate_y = 150 * random.random(), 150 * random.random()
# Load the USD Object
try:
asset = create_prim(object_transform_path, "Xform",
position=np.array([150 + translate_x, 175 + translate_y, -55]),
orientation=euler_angles_to_quat(np.array([0, 0.0, 0]),
usd_path=object_path)
# Set the object with correct physics
utils.setRigidBody(asset, "convexHull", False)
將領域隨機化元件初始化:
def create_camera_randomization(self):
# A range of values to move and rotate the camera
camera_tranlsate_min_range, camera_translate_max_range = (100, 100, -58),
(220, 220, -52)
camera_rotate_min_range, camera_rotate_max_range = (80, 0, 0), (85, 0 ,360)
# Create a Transformation DR Component for the Camera
self.camera_transform = self.dr.commands.CreateTransformComponentCommand(
prim_paths=[self.camera.GetPath()],
translate_min_range=camera_tranlsate_min_range,
translate_max_range=camera_translate_max_range,
rotate_min_range=camera_rotate_min_range,
rotate_max_range=camera_rotate_max_range,
duration=0,5).do()
確保模擬中的攝影機位置和屬性與真實世界的屬性類似。必須為地板新增語意 ID,才能產生正確的自由空間分割遮罩。如前所述套用領域隨機化,以提高模型的 sim2real 效能。
我們的指令碼是以 NVIDIA Isaac Sim 文件中提供的離線資料產生範例為起點。此使用案例已進行變更,包括透過物理將物件新增至場景、更新領域隨機化,以及為地板新增語意。我們為資料集產生了將近 30,000 張影像及其對應的分割遮罩。
使用 TAO 工具套件進行訓練、調整和最佳化
在本節中,將使用 TAO 工具套件,透過產生的合成資料微調模型。在此任務中,我們選擇使用 NGC 提供的 UNET 模型進行實驗。
!ngc registry model list nvidia/tao/pretrained_semantic_segmentation:*
設定資料、規格檔案(TAO 規格)和實驗目錄:
%set_env KEY=tlt_encode %set_env GPU_INDEX=0 %set_env USER_EXPERIMENT_DIR=/workspace/experiments %set_env DATA_DOWNLOAD_DIR=/workspace/freespace_data %set_env SPECS_DIR=/workspace/specs
下一步是挑選模型。
挑選適合的預先訓練模型
預先訓練 AI 和深度學習模型是已在代表性資料集上進行訓練,並透過權重和偏差進行微調的模型。相較於從零開始訓練,您可以透過僅使用一小部分資料的套用轉移學習,輕鬆快速地微調預先訓練模型。
在預先訓練模型的領域中,部分模型將執行特定任務,例如偵測人、汽車、車牌等。
首先,我們選擇具有 ResNet10 和 ResNet18 骨幹的 U-Net 模型。從模型獲得的結果顯示在真實世界資料中,牆壁和地板是合併為單一實體,而不是兩個單獨的實體。即使模型呈現出高準確度的模擬影像效能,情況也是如此。
| BackBone | 已修剪 | 資料集大小 | 影像大小 | 訓練評估 | |||
| 訓練 | Val | F1 分數 | mIoU (%) | 期數 | |||
| RN10 | NO | 25K | 4.5K | 512×512 | 89.2 | 80.1 | 50 |
| RN18 | NO | 25K | 4.5K | 512×512 | 91.1 | 83.0 | 50 |
我們使用不同的骨幹和影像大小進行實驗,以觀察延遲(FPS)與準確度之間的取捨。表中的所有模型都相同(UNET),僅骨幹不同。

根據結果顯然,我們需要更適合使用案例的不同模型。我們選擇 NGC 目錄中 PeopleSemSeg 模型。該模型已針對「人」類別,在五百萬個物件上進行預先訓練,資料集是由攝影機高度、人群密度和視野(FOV)組成。此模型也可以將背景和自由空間分割為兩個單獨的實體。
此模型在使用同一個資料集進行訓練後,平均 IOU 提高了超過 10%,產生的影像清楚呈現出地板與牆壁之間更理想的分割。
| BackBone | 已修剪 | 資料集大小 | 影像大小 | 訓練評估 | |||
| 訓練 | Val | F1 分數 | mIoU (%) | 期數 | |||
| PeopleSemSegNet | 否 | 25K | 4.5K | 512×512 | 98.1 | 96.4 | 50 |
| PeopleSemSegNet | 否 | 25K | 4.5K | 960×544 | 99.0 | 98.1 | 50 |

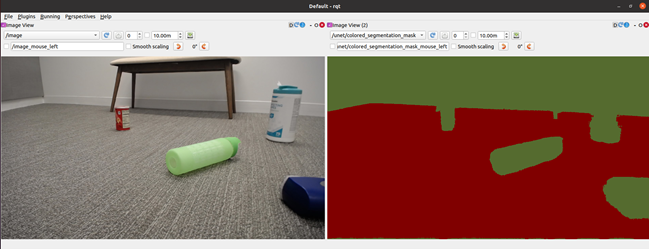
圖 4 呈現在使用真實世界資料微調 PeopleSemSeg 模型之前,從機器人的觀點,識別模擬影像和真實世界影像的自由空間。意即使用純 NVIDIA Isaac Sim 資料訓練的模型。
主要的重點在於,雖然可能有許多預先訓練模型可以完成任務,但是重要的是挑選最接近目前應用程式的模型。於此情形下,可以使用TAO 的專用模型。
!tao unet train --gpus=1 --gpu_index=$GPU_INDEX \
-e $SPECS_DIR/spec_vanilla_unet.txt \
-r $USER_EXPERIMENT_DIR/semseg_experiment_unpruned \
-m $USER_EXPERIMENT_DIR/peoplesemsegnet.tlt \
-n model_freespace \
-k $KEY
在訓練模型後,於驗證資料上評估模型效能:
!tao unet evaluate --gpu_index=$GPU_INDEX -e$SPECS_DIR/spec_vanilla_unet.txt \
-m $USER_EXPERIMENT_DIR/semseg_experiment_unpruned/weights/model_freespace.tlt \
-o $USER_EXPERIMENT_DIR/semseg_experiment_unpruned/ \
-k $KEY
對於 NVIDIA Isaac Sim 資料上的模型效能和 Sim2Sim 驗證效能感到滿意之後,請修剪模型。
為了能以最小延遲執行此模型,請將模型最佳化,以便在目標 GPU 上執行。有兩種方式可以達成此目的:
- 修剪:TAO 工具套件中的修剪功能可以自動移除不需要的層和神經元,有效縮減模型大小。必須重新訓練模型,才能恢復修剪期間損失的準確度。
- 訓練後量化:TAO 工具套件中的另一項功能可以進一步縮減模型大小。可以將精度從 FP32 變更為 INT8,以提升效能,不會犧牲準確度。
首先,修剪模型:
!tao unet prune \
-e $SPECS_DIR/spec_vanilla_unet.txt \
-m $USER_EXPERIMENT_DIR/semseg_experiment_unpruned/weights/model_freespace.tlt \
-o $USER_EXPERIMENT_DIR/unet_experiment_pruned/model_unet_pruned.tlt \
-eq union \
-pth 0.1 \
-k $KEY
重新訓練和修剪模型:
!tao unet train --gpus=1 --gpu_index=$GPU_INDEX \
-e $SPECS_DIR/spec_vanilla_unet_retrain.txt \
-r $USER_EXPERIMENT_DIR/unet_experiment_retrain \
-m $USER_EXPERIMENT_DIR/unet_experiment_pruned/model_unet_pruned.tlt \
-n model_unet_retrained \
-k $KEY
對於已修剪模型的 Sim2Sim 驗證效能感到滿意之後,請進入下一步,微調真實世界資料。
!tao unet train --gpus=1 --gpu_index=$GPU_INDEX \
-e $SPECS_DIR/spec_vanilla_unet_domain_adpt.txt \
-r $USER_EXPERIMENT_DIR/semseg_experiment_domain_adpt \
-m $USER_EXPERIMENT_DIR/semseg_experiment_retrain/model_unet_pruned.tlt\
-n model_domain_adapt \
-k $KEY
結果
表 1 所示為未修剪模型與已修剪模型之間的結果摘要。根據在 NVIDIA Jetson Xavier NX 上測量的結果,相較於原始模型,選擇用於部署的最終修剪和量化模型縮小了 17 倍,推論效能加快了 5 倍。
| 模型 | 資料集 | 訓練評估 | 推論效能 | ||||
| 已修剪 | 微調真實世界資料 | 訓練集 | 驗證集 | F1 分數 (%) | mIoU (%) | 精度 | FPS |
| 否 | 否 | 模擬 | 模擬 | 0.990 | 0.981 | FP16 | 3.9 |
| 是 | 否 | 模擬 | 模擬 | 0.991 | 0.982 | FP16 | 15.29 |
| 是 | 否 | 模擬 | 真實 | 0.680 | 0.515 | FP16 | 15.29 |
| 是 | 是 | Real | 真實 | 0.979 | 0.960 | FP16 | 15.29 |
| 是 | 是 | 真實 | 真實 | 0.974 | 0.959 | INT8 | 20.25 |
模擬資料的訓練資料集包含 25K 張影像,用於微調的真實世界影像訓練資料僅包含 44 張影像。真實影像的驗證資料集僅包含 56 張影像。在真實世界資料方面,我們是在三種不同的室內場景中收集資料集。模型的輸入影像大小為 960×544。使用 NVIDIA TensorRT trtexec 工具測量推論效能。

使用 NVIDIA Isaac ROS 進行部署
本節說明使用 NVIDIA Isaac ROS 將經過訓練和最佳化的模型,部署在搭載 Jetson Xavier NX 之 iRobot Create 3 機器人上的步驟。Create 3 和 NVIDIA Isaac ROS 影像分割節點都是在 ROS2 上執行。
此範例使用 /isaac_ros_image_segmentation/isaac_ros_unet GitHub 儲存庫,部署自由空間分割。
請從 /NVIDIA-ISAAC-ROS/isaac_ros_image_segmentation GitHub 儲存庫執行下述步驟,以使用自由空間分割模型。
建立 Docker 互動式工作空間:
$isaac_ros_common/scripts/run_dev.sh your_ws
複製所有套件相依性:
- isaac_ros_dnn_encoders
- isaac_ros_nvengine_interfaces
- 推論套件(您可以挑選任何一個)
- isaac_ros_tensor_rt
- isaac_ros_triton
建立與取得工作空間:
$cd /workspaces/isaac_ros-dev $colcon build && . install/setup.bash
從工作機器下載經過訓練的自由空間識別(.etlt)模型:
$scp <your_machine_ip>:<etlt_model_file_path> <ros2_ws_path>
將經過加密的 TLT 模型(.etlt)和格式轉換成 TensorRT 引擎計畫。針對 INT8 模型執行以下命令:
tao converter -k tlt_encode \
-e trt.fp16.freespace.engine \
-p input_1,1x3x544x960,1x3x544x960,1x3x544x960 \
unet_freespace.etlt
依據 Isaac ROS 影像分割的解說操作:
- 將 TensorRT 模型引擎檔案保存在正確的目錄中。
- 建立 config.pbtxt。
- 更新 isaac_ros_unet 啟動檔案中的模型引擎路徑和名稱。
- 重建與執行以下命令:
$ colcon build --packages-up-to isaac_ros_unet && . install/setup.bash $ ros2 launch isaac_ros_unet isaac_ros_unet_triton.launch.py
總結
本文示範從在 NVIDIA Isaac Sim 中產生合成資料開始,使用 TAO 工具套件進行微調,然後使用 NVIDIA Isaac ROS 部署模型的端對端工作流程。
NVIDIA Isaac Sim 和 TAO 工具套件都是排除 AI 框架複雜性的解決方案,讓您可以在生產中建立和部署 AI 機器人應用程式,無須具備任何 AI 專業知識。