隨著摩爾定律的減緩,在同一個技術製程節點開發其他可提高晶片效能的技術,已變得越來越重要。我們的方法是使用 AI 設計更小、更快、更有效率的電路,進而為每一代晶片提供更高的效能。
大量的算術電路驅動 NVIDIA GPU,可為 AI、高效能運算和電腦圖形實現前所未有的加速。因此,改進這些算術電路的設計,將是提高 GPU 效能和效率的關鍵。
如果 AI 可以學習設計這些電路時,會如何呢?在 PrefixRL:Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning 中,我們證明了 AI 不僅可以學習從零開始設計這些電路,且 AI 設計的電路比最先進的電子設計自動化(EDA)工具設計的電路更小、更快。最新的 NVIDIA Hopper GPU 架構擁有將近 13,000 個 AI 設計電路執行個體。

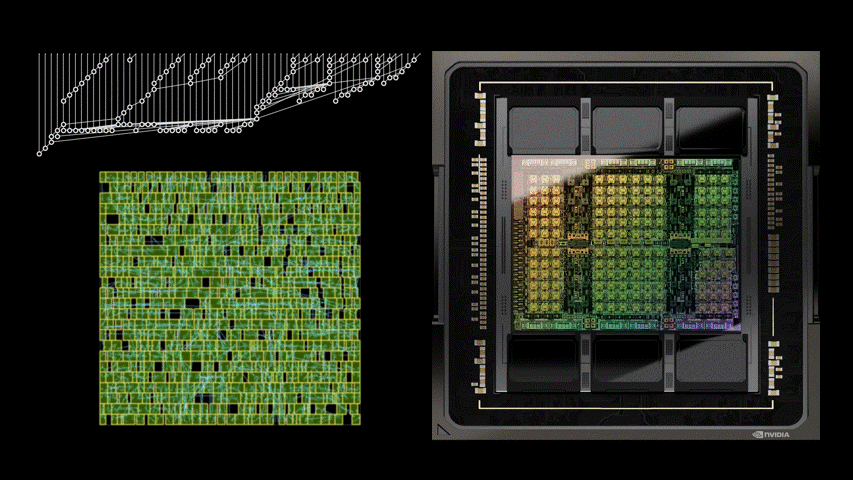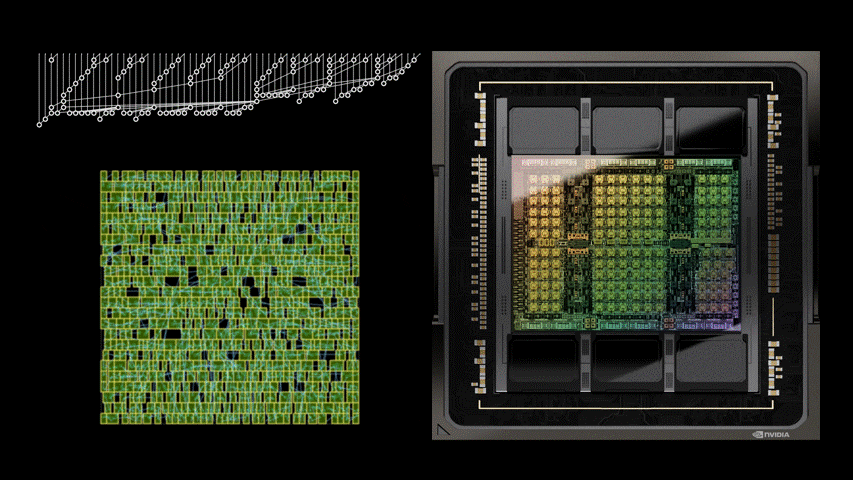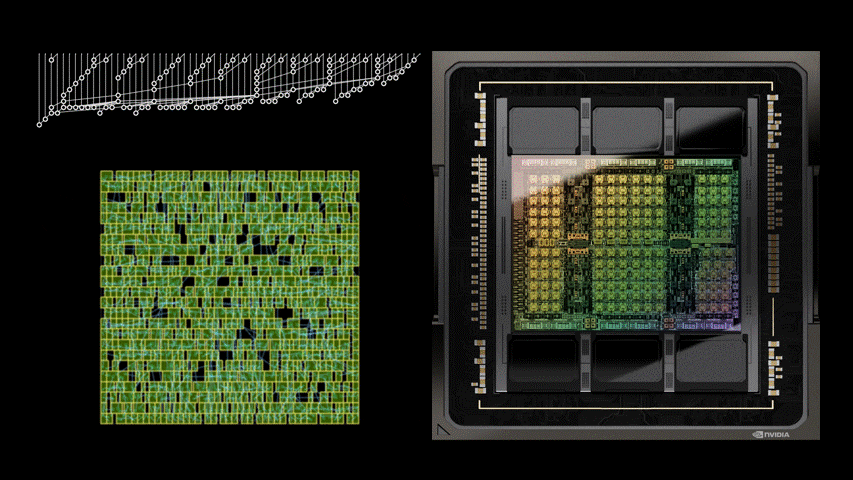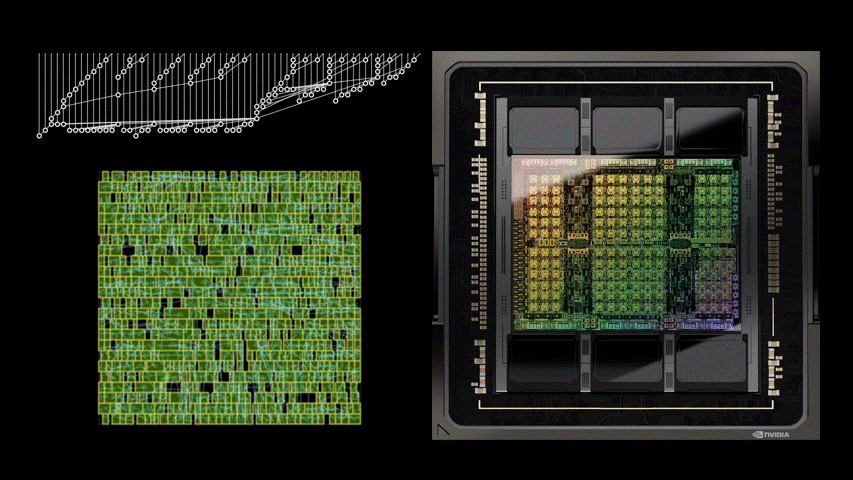
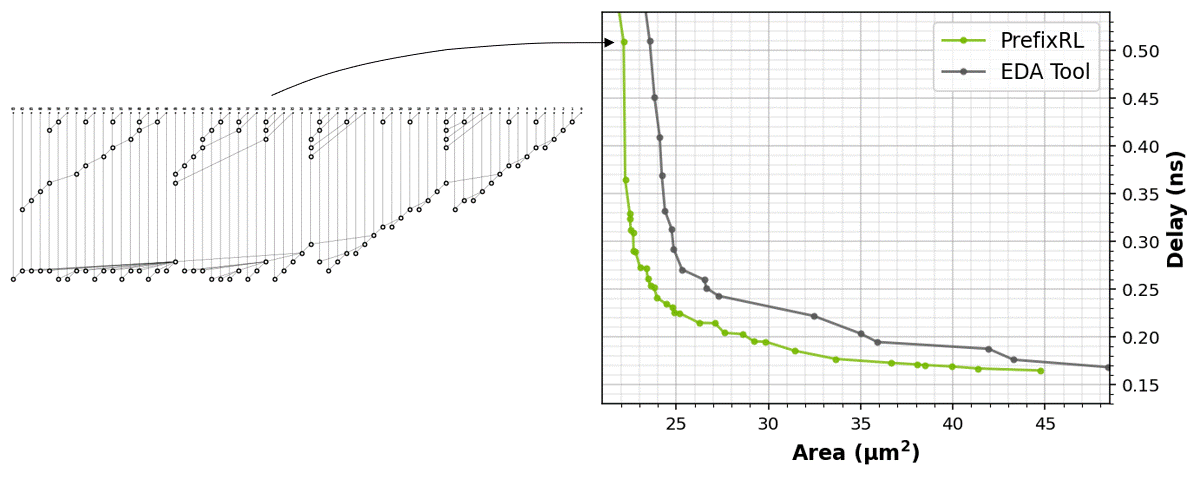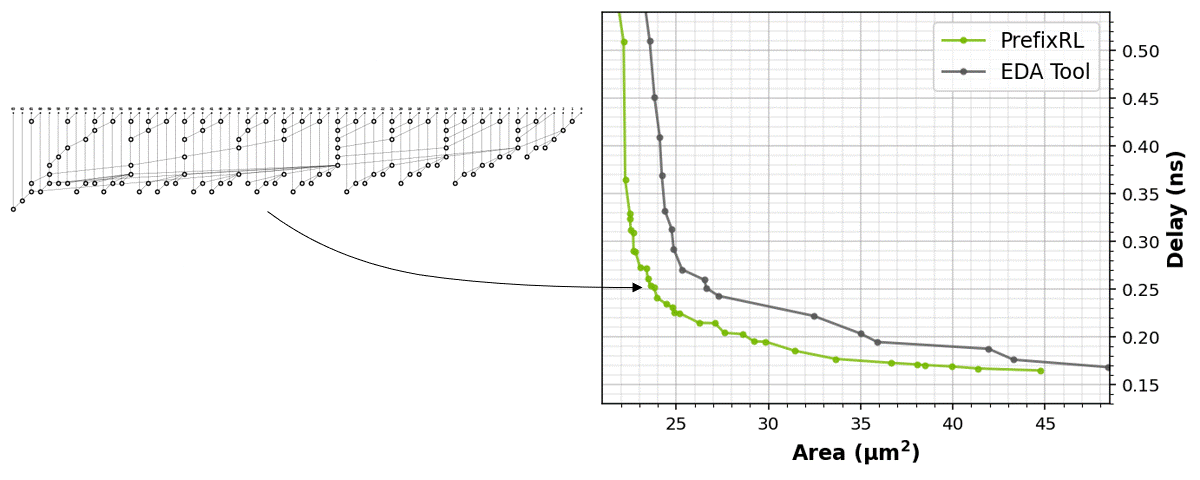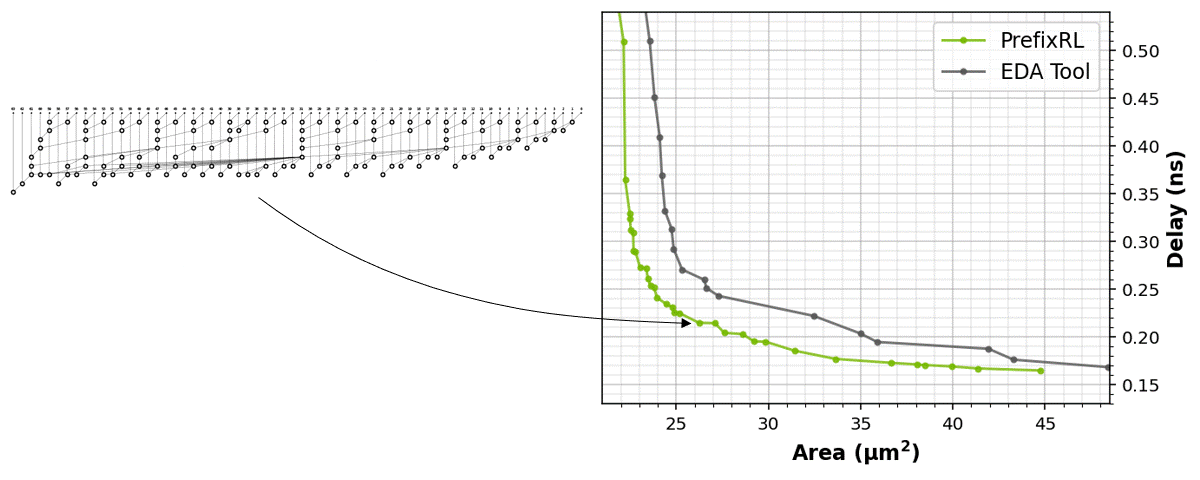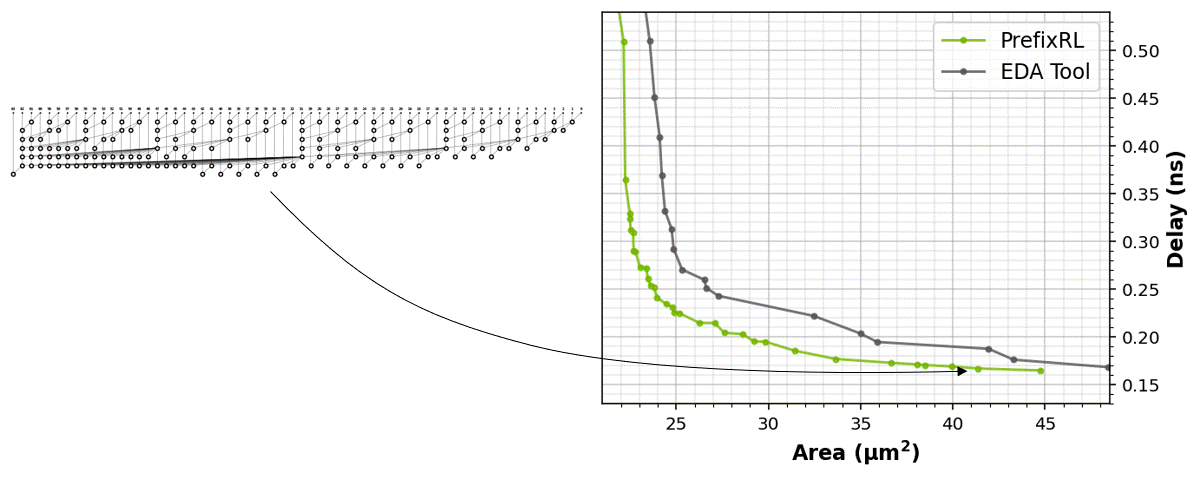
圖 1 中的電路對應圖 5 之 PrefixRL 曲線中的(31.4µm², 0.186ns)點。
電路設計比賽
電腦晶片中的算術電路是使用邏輯閘網路例如 NAND、NOR、XOR,和電線進行建構。理想的電路應具有下列特性:
- 小:較小的面積,使晶片上可以安裝更多電路。
- 快速:較低的延遲,以提高晶片效能。
- 消耗較少功率:較低的晶片功耗。
本文著重於電路面積和延遲。我們發現功耗與目標電路的面積密切相關。電路面積與延遲通常為互競屬性,所以我們希望能找出設計的 Pareto 邊界,以有效取捨這些屬性。簡言之,我們需要任何延遲下的最小面積電路。
在 PrefixRL 中,我們著重於稱為(平行)前綴電路(prefix circuit)的常見算術電路類別。GPU 中的加法器、增量器、編碼器等各種重要電路都是屬於前綴電路,在更高層級可以定義為前綴圖。
在本文中特別提出的問題是:AI 代理程式是否可以設計出良好的前綴圖?所有前綴圖的狀態空間都很大的 O(2^n^n),且無法使用蠻力法進行探索。
使用電路產生器,將前綴圖轉換成具有電線和邏輯閘的電路。之後,物理合成工具會使用閘門大小調整、複製、緩衝器插入等物理合成最佳化,進一步最佳化產生的電路。
由於這些物理合成最佳化,使最終電路屬性如延遲、面積和功率不會直接從位準、節點計數等原始前綴圖屬性轉譯。因此,AI 代理程式可以學習設計前綴圖,但是會針對從前綴圖產生之最終電路的屬性進行最佳化。
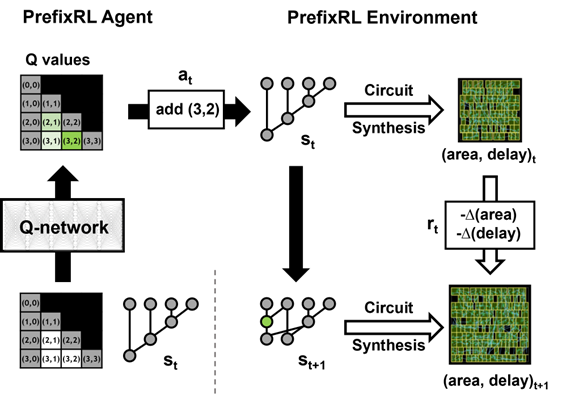
我們將算術電路設計視為強化學習(reinforcement learning)任務,以訓練代理程式,最佳化算術電路的面積和延遲屬性。在前綴電路方面,我們設計出一個可以讓強化學習代理程式在前綴圖中新增或移除節點的環境,之後進行下述步驟:
- 將前綴圖合法化,以隨時維持正確的前綴和計算。
- 從合法化的前綴圖產生電路。
- 使用物理合成工具,針對電路進行物理合成最佳化。
- 測量電路的面積和延遲屬性。
在一期中,強化學習代理程式透過新增或移除節點,逐步建立前綴圖。在每一個步驟,代理程式都會收到對應於電路面積和延遲的改進,以做為回報。
狀態和動作表示以及深度強化學習模型
我們使用 Q-learning 演算法訓練電路設計代理程式。我們針對前綴圖使用網格表示,網格中的每個元素唯一對映至前綴節點。在 Q 網路的輸入和輸出使用此網格表示。輸入網格中的每一個元素是表示節點是否存在。輸出網格中的每一個元素是表示新增或移除節點的 Q 值。
我們針對代理程式使用全卷積神經網路架構,因為 Q 學習代理程式的輸入和輸出是網格表示。代理程式會分別預測面積和延遲屬性的 Q 值,因為在訓練過程中可以分別觀察面積和延遲的回報。
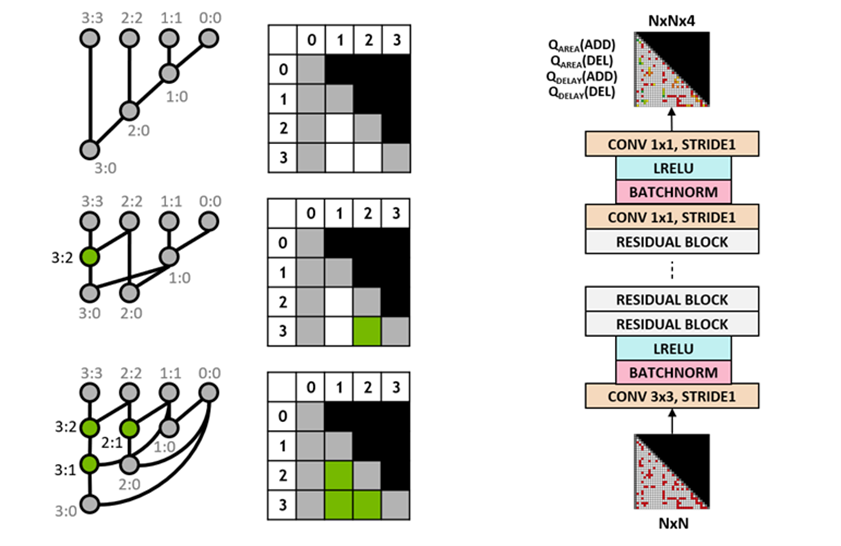
圖 3:特定 4B 前綴圖(左)和全卷積 Q 學習代理程式架構(右)的表示
使用 Raptor 進行分散式訓練
PrefixRL 是一項運算要求嚴苛的任務:物理模擬的每一個 GPU 需要 256 個 CPU,而訓練 64b 案例需要的 GPU 時數超過 32,000。
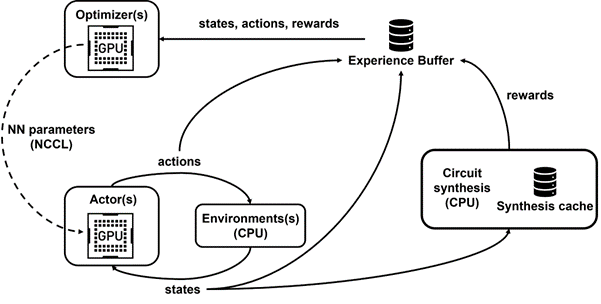
我們開發的內部分散式強化學習平台 Raptor,特別利用 NVIDIA 硬體進行此類工業強化學習(圖 4)。
Raptor 具有多項可以提高擴充性和訓練速度的功能,例如工作排程、自訂網路和 GPU 感知資料結構。在 PrefixRL 的脈絡中,Raptor 使可以跨 CPU、GPU 與 Spot 執行個體的組合分配工作成為可能。
此強化學習應用程式中的網路具有多樣性,並受益於下列幾點。
- Raptor 可以在 NCCL 之間切換,以進行點對點傳輸,將模型參數從學習器 GPU 直接傳輸至推論 GPU。
- Redis 是用於非同步和較小的消息,例如回報或統計。
- JIT 編譯的 RPC 可以處理高容量和低延遲要求,例如上傳經驗資料。
最後,Raptor 提供的 GPU 感知資料結構,例如具有多執行緒伺服器的重放緩衝區,可以從多個工作節點接收經驗,同時針對資料進行批次處理以及預先擷取至 GPU 上。
如圖 4 所示,我們的框架可以支援同時訓練和資料收集,並利用 NCCL 將最新參數有效地傳送給執行器。
回報計算
我們使用 [0,1] 中的取捨權重 w 結合面積和延遲目標。我們以不同的權重訓練各種代理程式,取得設計的 Pareto 邊界,以平衡面積與延遲之間的取捨。
強化學習環境中的物理合成最佳化可以產生各種解法,在面積與延遲之間取捨。我們應使用與訓練特定代理程式相同的取捨權重,驅動物理合成工具。
在回報計算的迴圈中執行物理合成最佳化,具有幾項優點。
- 強化學習代理程式學習直接將目標技術節點和函式庫的最終電路屬性最佳化。
- 強化學習代理程式可以在物理合成過程中加入周圍邏輯,同時最佳化目標算術電路及其周圍邏輯的屬性。
但是,執行物理合成是一個緩慢的過程(64b 加法器十大約為 35 秒),可能會大幅減緩強化學習訓練和探索。
我們將會回報計算與狀態更新解耦,因為代理程式僅需要目前之前綴圖狀態即可採取行動,而無須電路合成或先前的回報。因為擁有 Raptor,使我們可以將冗長的回報計算卸載至 CPU 工作節點集區,以平行執行物理合成,而執行代理程式無須等待,即可逐步穿越環境。
當 CPU 工作節點回傳回報時,即可在之後將轉換插入至重放緩衝區。針對合成回報進行快取,以避免於再次遭遇狀態時進行多餘計算。
結果
強化學習代理程式是完全透過合成電路屬性的回饋,學習設計電路白板。圖 5 為使用 PrefixRL 設計的 64b 加法器電路、來自最先進 EDA 工具的 Pareto 主導加法器電路之面積和延遲的最新結果*。
最佳之 PrefixRL 加法器在相同的延遲下,達到比 EDA 工具加法器低 25% 的面積。這些在物理合成最佳化之後,對映至 Pareto 最佳加法器電路的前綴圖具有不規則結構。
結論
據我們所知,這是第一種使用深度強化學習代理程式設計算術電路的方法。希望此方法可以成為藍圖,以應用 AI 解決真實世界電路設計問題:建構行動空間、狀態表示、強化學習代理程式模型、最佳化多個互競目標,以及克服物理合成等緩慢的回報計算過程。
若需要更多資訊以及與其他方法的比較,請參閱 PrefixRL:Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning(預印本)。