
這是 CUDA 總複習系列的第一篇文章,目的是為初階或中階開發人員複習 CUDA、工具和最佳化的主要概念。
科學探索和商業分析使對運算資源的需求變得永無止境。許多應用程式如天氣預報、運算流體力學模擬、近期的機器學習和深度學習,需要比目前更多的運算能力,以及更複雜且需要更多運算能力才能執行的演算法。
運算產業仰賴各種方式提供所需的效能,例如提高電晶體密度、指令層級平行化、Dennard 縮放比例定律(Dennard scaling)等:
- 根據摩爾定律的預測,增加積體電路上的電晶體數目推動了運算需求,並使晶片電晶體密度每十八個月便會增加一倍。
- 雖然在指令層級的平行技術也有助於提升效能,但從 2001 年左右開始縮減。
- 直到 2005 年電壓調節結束時,Dennard 縮放比例定律還與摩爾定律結合在一起提供了好處。
在 2005 年左右,運算的調節開始下降,產業需要替代方案以滿足運算需求。顯然的,運計算單元進行平行化是未來能夠提高效能的最好方式。
其他的主要因素是功率和通訊技術。研究顯示功率主要是耗費在通訊技術上,更多更複雜的通信技術意味著更高的功耗並限制了可放入機器中的計算量。這表示未來的運算應具備功率效率並首選本地化。
GPGPU 時代
在 90 年代和 2000 年代,圖形硬體是為了滿足特定需求而設計,尤其是圖形產業的工作負載。但圖形工作負載需要的運算能力越來越高。因此,效能以每年約 2.4 倍的幅度提升,然而電晶體倍增所提供的幅度則是每年約 1.8 倍。圖 1 所示為北卡羅來納大學(University of North Carolina,UNC)John Poulton 教授著名的圖形效能軌跡。
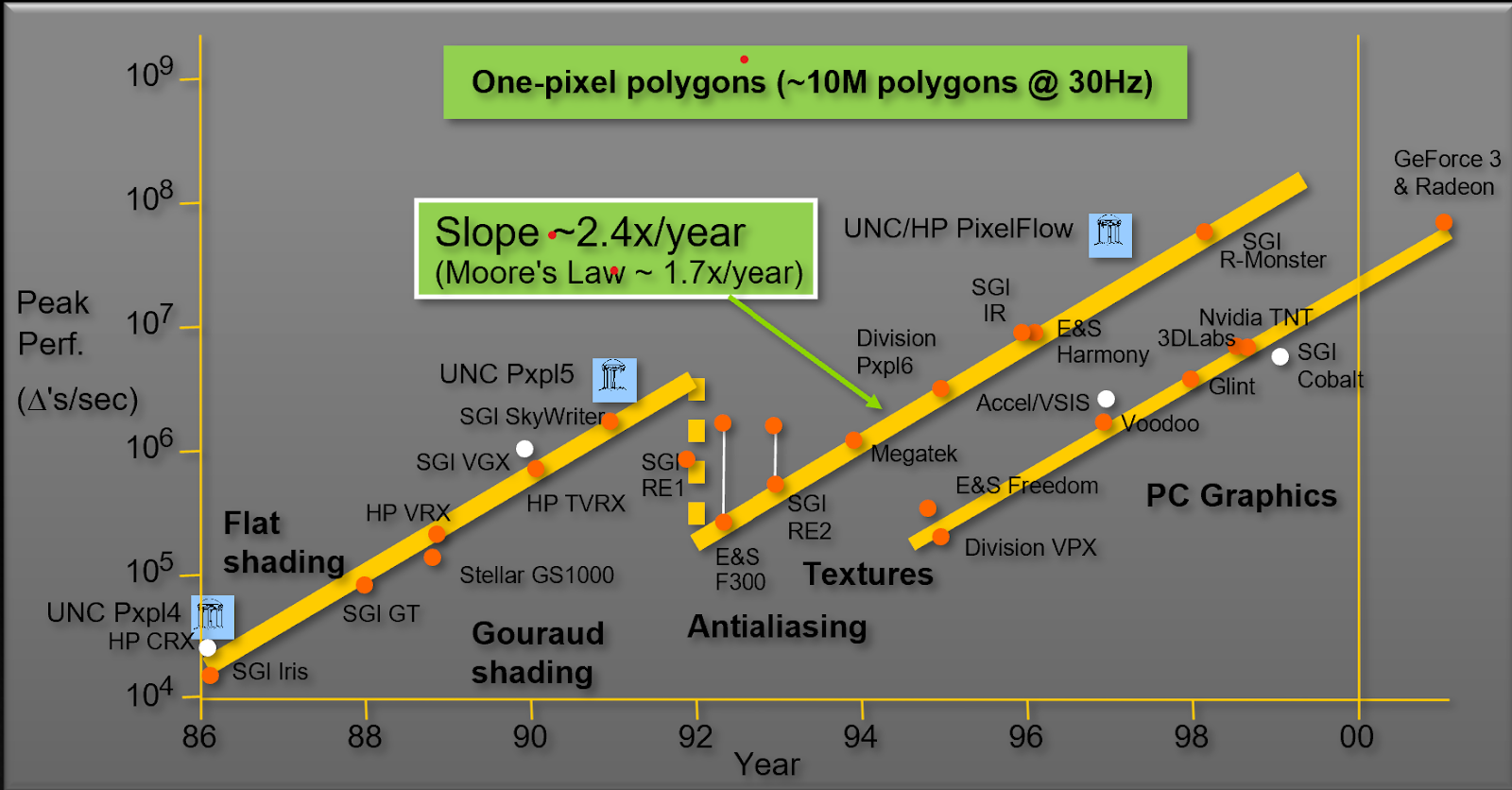
以每秒三角形數為單位,圖形硬體以每年超過 2.4 倍的幅度提高效能,比摩爾定律的預測更快。這是因為電腦圖形運算具有大規模平行性,硬體能加以利用。2001 年,電腦圖形已預告專為圖形而設計的大規模系統的終結。
對開發人員社群而言,這是利用圖形硬體的驚人運算能力並加快醫學影像、電磁學等科學工作負載的動機。
NVIDIA 圖形處理單元(graphics processing units,GPU)最初是為了執行具有高平行性的遊戲和圖形工作負載所設計。由於遊戲和圖形產業對 FLOPS 和記憶體頻寬的需求高,因此 GPU 演變成高度平行的多執行緒多核心處理器,具有強大的運算能力和高記憶體頻寬。這開創了 GPGPU 時代:最初只為了加快遊戲、圖形等特定工作負載所設計的 GPU 通用運算。
混合運算模型
GPU 是為了高度平行運算所設計,又稱為高傳輸量處理器。許多科學和 AI 工作負載的演算法具有固有的大規模平行性,在 CPU 上的執行速度可能非常慢。
GPU 加速應用程式將這些特別耗時的算式和函式(又稱為熱點),利用 GPU 的大規模平行性,將原本複雜的運算平行化。應用程式的其他部分仍將由 CPU 執行。您可以將程式碼運算密集和耗時部分交給 GPU 來運算以加快應用程式,而不必將應用程式完全移動到 GPU。這又稱為混合運算模型。
隨著混合運算興起,兩種處理器共存,但仍有基本差異。圖 2 所示為 CPU 與 GPU 之間的基本差異。
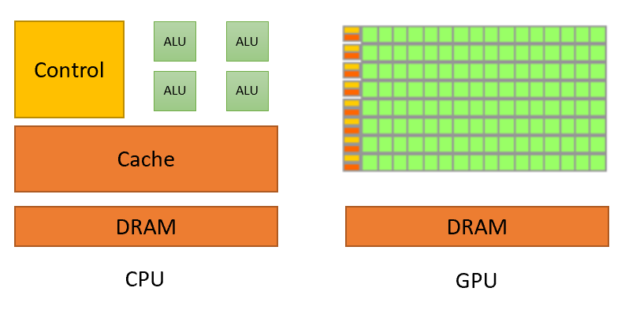
GPU 將大多數的電晶體用於資料處理,而 CPU 也必須為大型快取、控制單元等保留區域。CPU 處理器的運作原理是將每個執行緒中的延遲最小化,GPU 則是透過運算隱藏指令和記憶體延遲。圖 3 所示為運算執行緒的差異。
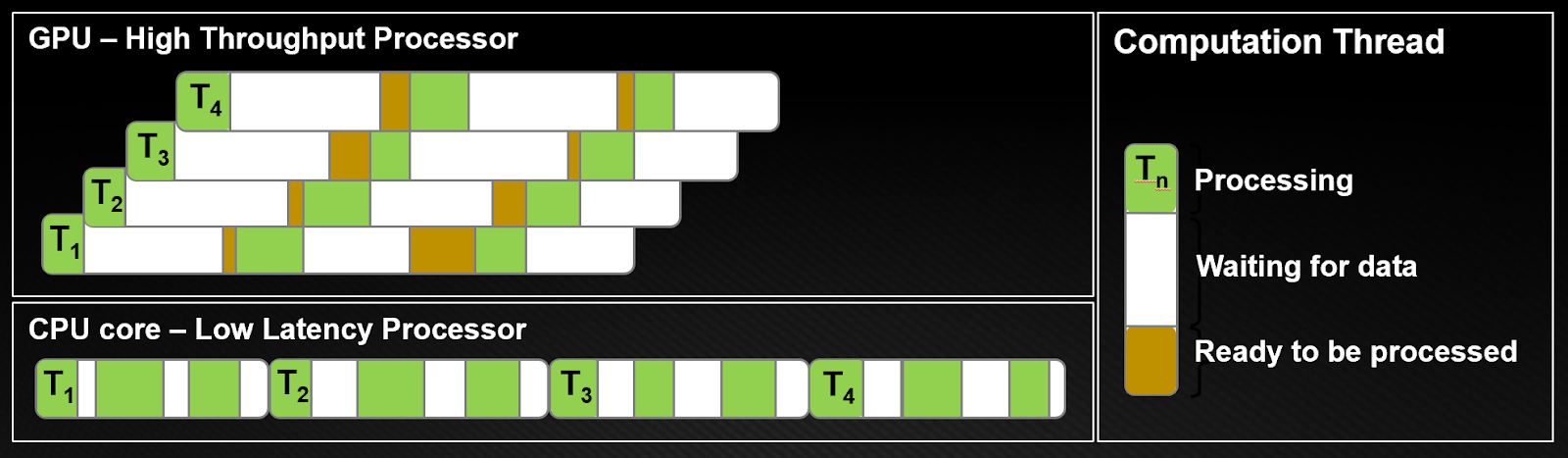
從圖 3 明顯可見,CPU 架構必須將每個執行緒中的延遲最小化。在 CPU 上,每個執行緒都會將資料存取時間最小化(白色長條)。在單一時間片段中,執行緒會盡可能完成工作(綠色長條)。為了達成此目的 CPU 需要低延遲,而這需要大型快取和複雜的控制邏輯。快取在每個核心只有幾個執行緒的情況下效果最佳,因為在執行緒之間進行脈絡切換的代價高昂。
GPU 架構透過運算隱藏指令和記憶體延遲。在 GPU 中執行緒為輕型執行緒,所以 GPU 可像每個時脈週期一樣頻繁的從停滯的執行緒切換到其他執行緒。
如圖 3 所示,執行緒 T1 等待資料時另一個執行緒 T2 開始處理,T3 和 T4 依此類推。同時,T1 最終取得要處理的資料。如此一來即可切換至其他可用工作以隱藏延遲。這表示 GPU 需要眾多重疊的同時執行緒以隱藏延遲。因此,要在 GPU 上執行數千個執行緒。
如需更多資訊,請參閱 CUDA Programming Guide。