
這是 CUDA 總複習系列的第四篇文章,目的是為初階或中階開發人員複習 CUDA、工具和最佳化的主要概念。
CUDA 程式設計模型提供了 GPU 架構抽象化,該架構是應用程式與其在 GPU 硬體之間,可能實現的橋梁。這篇文章概述 CUDA 程式設計模型的主要概念,說明如何用 C/C++ 等通用程式設計語言加以實現。
在此介紹 CUDA 程式設計模型中常用的兩個關鍵字:主機(host)和裝置(device)。
主機是系統中的可用的 CPU。與 CPU 相關的系統記憶體稱為主機記憶體。GPU 則為裝置,因此 GPU 記憶體稱為裝置記憶體。
若要執行任何 CUDA 程式有三個主要步驟:
- 將輸入資料從主機記憶體複製到裝置記憶體,又稱為主機到裝置傳輸。
- 載入 GPU 程式並執行,裝置的晶片從裝置的記憶體上獲取資料以提高效能。
- 將結果從裝置記憶體複製到主機記憶體,又稱為裝置到主機傳輸。
CUDA 核心和執行緒階層
如圖 1 所示,CUDA 核心(kernal)是在 GPU 上執行的函式。應用程式的平行部分是由 K 個不同的 CUDA 執行緒平行(thread)執行 K 次,不像一般 C/C++ 函式僅執行一次。
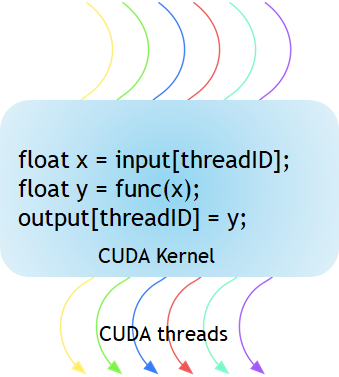
每個 CUDA 核心都是以 __global__ 宣告指定元開頭。程式設計師使用內建變數為每個執行緒提供唯一全域 ID。
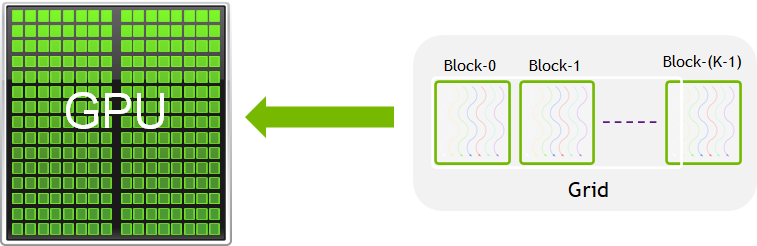
執行緒群組稱為 CUDA 區塊(block)。數個 CUDA 區塊組合成網格(grid)。核心以執行緒區塊網格的形式執行(圖 2)。
每個 CUDA 區塊是由一個串流多重處理器(streaming multiprocessor,SM)執行,無法移轉至 GPU 中的其他 SM(先占、除錯或 CUDA 動態平行期間除外)。一個 SM 可同時執行多個 CUDA 區塊,視 CUDA 區塊所需的資源而定。每個核心都在一個裝置上執行,CUDA 支援一次在裝置上執行多個核心。圖 3 所示為 GPU 可用硬體資源上的核心執行和對映。
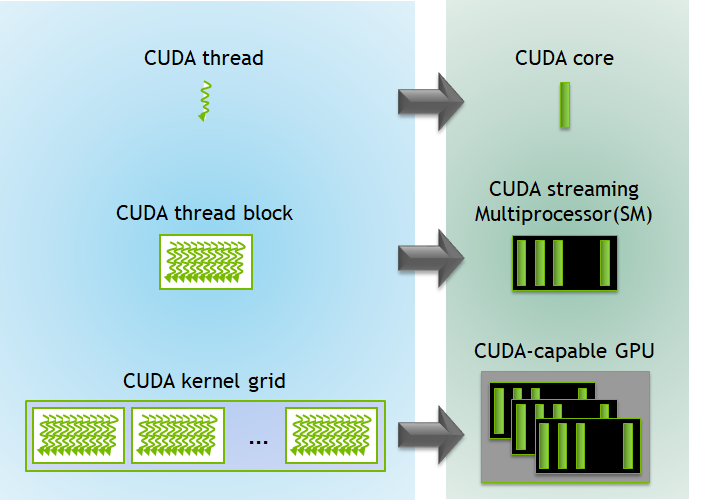
CUDA 為執行緒和區塊定義內建的 3D 變數。使用內建的 3D 變數 threadIdx 為執行緒建立索引。三維索引以自然的方式為向量、矩陣和體積中的元素建立索引,並使 CUDA 程式設計變得更簡單。同樣的,使用內建的 3D 變數 blockIdx 為區塊建立索引。
以下幾點值得注意:
- CUDA 架構限制每個區塊的執行緒數量(每個區塊 1024 個執行緒)。
- 透過內建的 blockDim 變數可在核心中存取執行緒區塊的維度。
- 使用內在函式 __syncthreads 可將區塊中的所有執行緒同步。透過 __syncthreads,區塊中的所有執行緒必須先等待才能繼續。
- 在 <<<…>>> 語法中指定的每個區塊的執行緒數量及每個網格的區塊數量屬於 int 或 dim3 類型。這些三重括號標記從主機程式碼到裝置程式碼的呼叫,又稱為核心啟動。
下方的 CUDA 程式將兩個矩陣相加,包含多維 blockIdx 和 threadIdx 及其他變數,例如 blockDim。在下方的例子中選擇 2D 區塊以便建立索引,每個區塊有 256 個執行緒,在 x 和 y 方向各有 16 個。將資料大小除以每個區塊的大小以計算區塊總數。
// 核心 – 將兩個矩陣 MatA 和 MatB 相加
__global__ void MatAdd(float MatA[N][N], float MatB[N][N],
float MatC[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
MatC[i][j] = MatA[i][j] + MatB[i][j];
}
}
int main()
{
…
// 從主機程式碼啟動矩陣相加核心
dim3 threadsPerBlock(16, 16);
dim3 numBlocks((N + threadsPerBlock.x -1) / threadsPerBlock.x,
(N+threadsPerBlock.y -1) / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(MatA, MatB, MatC);
…
}
記憶體階層
支援 CUDA 的 GPU 記憶體階層如圖 4 所示。
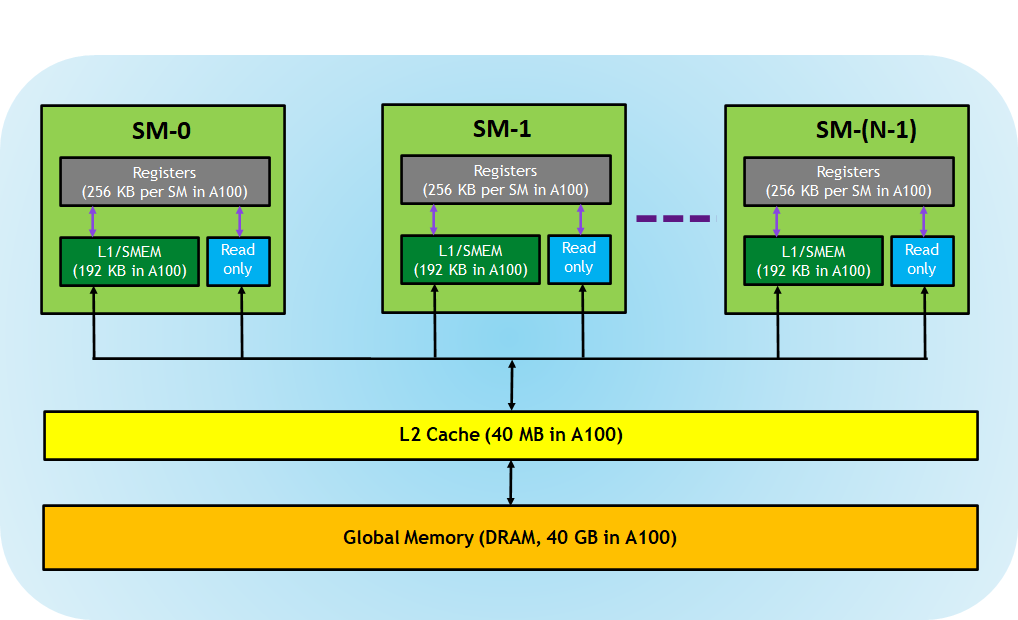
GPU 架構公開以下記憶體:
- 暫存器 – 專屬於每個執行緒,分配給某個執行緒的暫存器對其他執行緒而言為不可見。編譯器做出關於暫存器利用的決定。
- L1/共用記憶體 (SMEM) – 每個 SM 都有的暫存記憶體,可當成 L1 快取和共用記憶體使用。相同 CUDA 區塊中的所有執行緒可使用共用記憶體,在相同 SM 上執行的所有 CUDA 區塊可共用 SM 提供的記憶體資源。
- 唯讀記憶體 – 每個 SM 都有指令快取、常數記憶體、紋理記憶體和 RO 快取,對核心程式碼而言為唯讀。
- L2 快取 – 所有 SM 共用 L2 快取,因此每個 CUDA 區塊中的每個執行緒都可存取此記憶體。NVIDIA A100 GPU 將 L2 快取大小增加到 40 MB,大於 V100 GPU 的 6 MB。
- 全域記憶體 – 這是 GPU 和 GPU 中的 DRAM 的畫格緩衝區大小。
NVIDIA CUDA 編譯器能將記憶體資源最佳化,但專業 CUDA 開發人員可選擇有效率的使用此記憶體階層,視需要將 CUDA 程式最佳化。
運算能力
GPU 的運算能力決定其整體規格及 GPU 硬體支援的可用功能。應用程式可在執行階段使用此版本號碼確定目前 GPU 上的可用硬體功能或指令。
每個 GPU 都有以 X.Y 表示的版本號碼;X 為主要版本號碼,Y 則是次要版本號碼。次要版本號碼對應架構的漸進式改善,可能包括新功能。
欲深入瞭解支援 CUDA 裝置的運算能力,請參閱 CUDA 範例程式碼 deviceQuery。此範例列舉存在於系統中的 CUDA 裝置屬性。
總結
CUDA 程式設計模型提供異質環境,主機程式碼在 CPU 上執行 C/C++ 程式,核心則在實體分離的 GPU 裝置上執行。CUDA 程式設計模型也假設主機和裝置維護各自的獨立記憶體空間,分別稱為主機記憶體和裝置記憶體。CUDA 程式碼也能透過 PCIe 匯流排在主機與裝置記憶體之間進行資料傳輸。
CUDA 也公開了許多內建變數,並提供多維索引的靈活性以簡化程式設計。CUDA 也管理不同的記憶體,包括暫存器、共用記憶體、L1 快取、L2 快取及全域記憶體。進階開發人員可有效率的使用這些記憶體將 CUDA 程式最佳化。