
Ada Sedova 在家中工作,有時甚至穿著睡衣,利用世界上功能最強大的超級電腦來尋找一個微小的分子,這種分子可以阻止冠狀病毒,阻止某人感染新冠病毒(COVID-19)。
橡樹嶺國家實驗室(Oak Ridge National Laboratory)的生物物理學研究員 Sedova 表示:“我比以往任何時候都做得更多,由於流感大流行引發的種種憂慮,我將大量的個人時間投入到這項工作中。”
她的努力可以帶來 10 位數字的薪水,特別是在短短 24 小時內執行了 20 億次分子測試。
Sedova 尋求一個配合體,這是一種有機分子,尺寸小於幾十個原子。正確的配合體將自身與冠狀病毒的蛋白質結合,從而阻止其感染健康細胞。
問題在於要檢查的配合體和蛋白質太多,隨著原子力的變化它們的形狀不斷變化。在巨大的數十億種可能的化合物堆疊中,這只是一根小小的針頭。
濕實驗室的專家可能需要很多年才能嘗試每種可能性。即使在 ORNL 的超級電腦 Summit 上的 9,216 個 CPU 上對它們全部進行模擬,也可能需要四年時間。因此 Sedova 和同事們轉而使用 Summit 的 27,648 個 NVIDIA GPU 來加快工作速度。
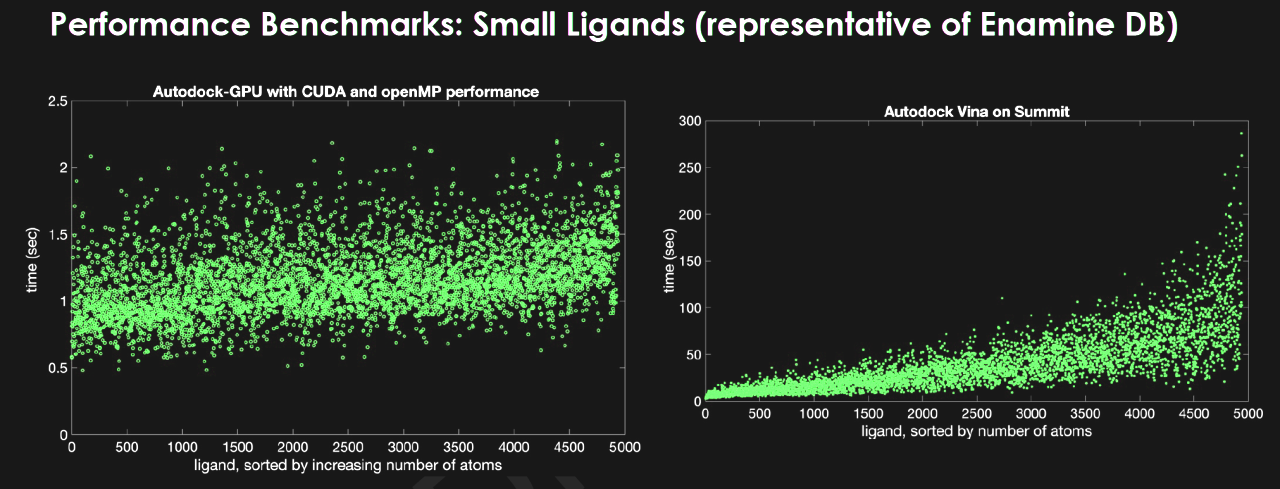
他們從 Scripps Research 找到 AutoDock 的一個版本,這是一個用於模擬蛋白質和配合體如何結合的開源程式。與 CPU 相比,它在 GPU 上使用OpenCL可以將處理速度提高多達 50 倍。
CUDA 切入正題
在 NVIDIA 的幫助下,該團隊將代碼移植到了 CUDA,使其可以在 Summit 上運行,並帶來了另一個 2.8 倍加速的額外好處。Jubilee Development 的另一位研究人員 Aaron Scheinberg 發現使用 OpenMP 可加速向 GPU 提供資料的方法時又將這項工作提高了 3 倍。
在另一項測試中,Sedova 顯示的結果表明,他們可以在短短 12 小時內高精度篩選出 14 億種化合物與蛋白質的資料集。與在 CPU 上運行的程式相比,該速度提高了 33 倍以上。
她說:“ GPU 結合 Summit 的規模和架構,提供了對接數十億種化合物的功能,”
團隊的另一位成員,生物物理學家 Josh Vermaas 向 NVIDIA 的 Scott Le Grand 致敬,後者將 AutoDock 移植到 CUDA。Vermaas 在有關該工作起源的部落格中說:“從過去侷限於 OpenCL 的代碼中,他在改善性能方面提供了驚人的幫助。”
在 24 小時內模擬 20 億種化合物
Sedova 現在認為,通過進一步的改進,該團隊可以創造一種在 24 小時內檢查多達 20 億種化合物的能力。這將代表著該尺寸在高解析度下的首次模擬。
研究人員在實現這一里程碑方面仍然面臨一些挑戰。
蛋白質-配合體對接的標準工作流程使用緩慢的基於文件的過程。它可以在筆記型電腦上測試數百種化合物,但如果是數十萬文件的規模,即使是世界上最大的超級電腦也將陷入困境。
這是為了幫助加速科學發展的開源開發人員的行動呼籲。
Sedova 的團隊正在領導這項工作,組建了一個新的工作流程,該工作流程有望安全地在 Summit 上啟動大量工作。她正在諮詢系統的 I/O 專家,並試圖建立一個資料庫來容納所有配合體。
下一步是在 Summit 的 4,608 個節點中的 108 個節點上啟動約 100 萬種化合物的實驗。她說:“如果行得通,我們將在 Summit 的所有節點上啟動 14 億個化合物的大規模生產。”
縮小對有希望的分子的搜索
如果該團隊成功,他們將向孟菲斯的研究人員發送一份清單,其中列出約 9000 種最有希望的化合物,以便在他們的濕實驗室中對真病毒進行測試。不是大海撈針,而是乾草堆中的針。
這項工作於 1 月份開始,當時 ORNL 的頂級研究人員 Jeremy C. Smith 展示了使用 Summit 超級電腦進行藥物研究以對抗冠狀病毒的第一項研究。這項工作仍處於初期。
展望未來,Sedova 提出在常用方法之外,用其他方法將蛋白質-配合體結合領域橋接到高效能運算中的想法。這樣,她也有足夠的精力去追求它們。
在 NVIDIA 的 COVID-19 頁面上了解有關使用 GPU 對抗冠狀病毒的更多工作。