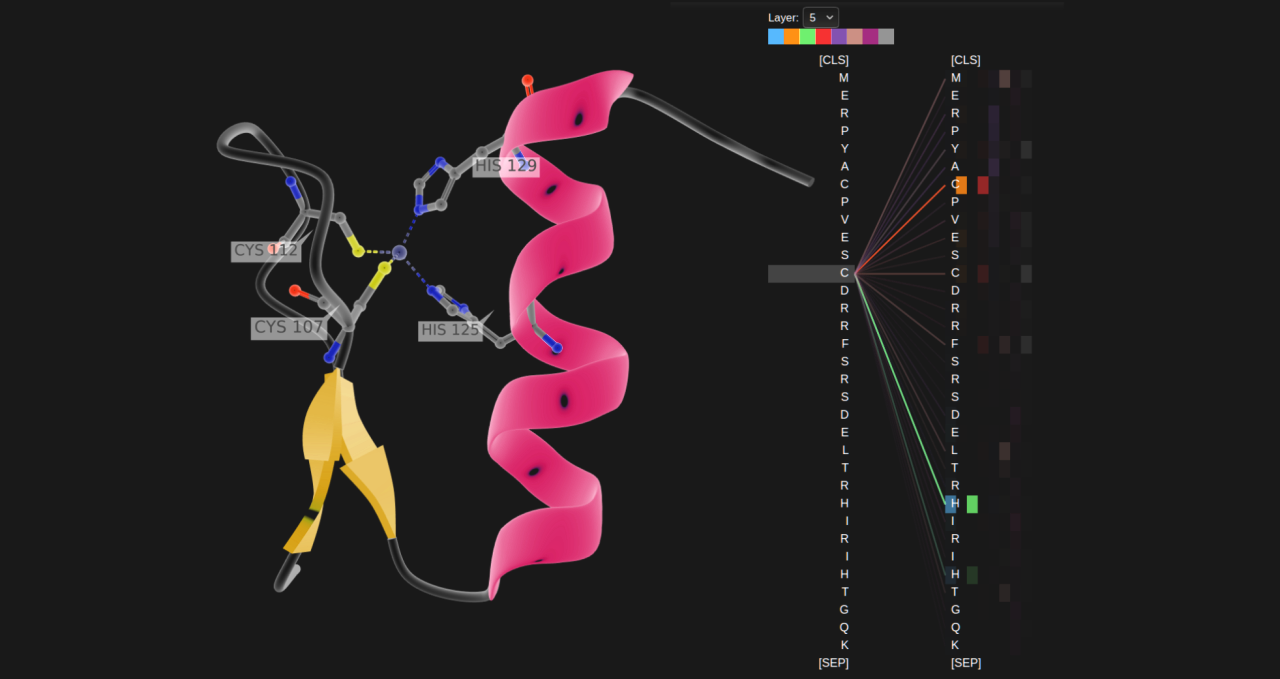
Ahmed Elnaggar 和 Michael Heinzinger 致力於幫助電腦輕鬆地讀取蛋白質,就像此刻你閱讀這句話一樣簡單。
他們將用於理解文本的最新 AI 模型應用於生物資訊領域。此舉有望加速生物體(例如冠狀病毒)表徵相關的研究工作進程。
他們的目標是在年底前建立一個網站。屆時,當研究人員在該網站輸入描述某種蛋白質的胺基酸序列後,幾秒鐘內即可獲取該蛋白質 3D 結構的詳情。這些訊息是了解如何用藥的關鍵。
當下,研究人員通常需要搜索資料庫獲取此類訊息。但隨著被定序蛋白質數量的增加,資料庫日益龐大。因此,採用這種方法搜索耗費的時間要比借助 AI 高出 100 倍之多,具體取決於蛋白質胺基酸序列的大小。
當遇到前所未見的特定蛋白質時,資料庫搜索便無法提供任何有用的結果,但 AI 卻可以。
計算生物學和生物資訊在讀博士生 Heinzinger 表示:“與 COVID-19 相關的 14 種蛋白質中,有 12 種與已知蛋白質相似。其餘兩種我們卻知之甚少。在這種情況下,借助於 AI 的方式就會大大派上用場。”
基於資料庫搜索的方式雖然很耗時,但其準確性比早期採用 AI 的方法高出了 7-8%。如今,採用最新的模型和資料集,可將與資料庫搜索方式間的準確性差距縮小一半,為日後 AI 的應用鋪平了道路。
AI模型和GPU助力深入探究生物學的奧秘
Heinzinger 表示:“在準確度方面, AI 演算法的改進速度非常快,讓我對消弭準確度的差距非常樂觀,同時,在資料集方面,計算生物學領域的增長比其他任何領域都要迅速,因此,我相信我們很快就會迎來新的突破。”
專注於遷移學習領域的 AI 專家 Elnaggar 博士表示:“這項工作在兩年前還是不可能完成的任務。如今,這些成果都要歸功於大量生物資訊資料、全新 AI 演算法、以及 NVIDIA GPU 的算力。”
Elnaggar 和 Heinzinger 都是慕尼黑工業大學Rostlab 實驗室的成員,該實驗室團隊引領了 AI 與生物學的跨學科研究。實驗室負責人 Burkhard Rost 於 1993 年撰寫了一篇具有開創性意義的論文,為研究指明了方向。
蛋白質讀取的語義學
背後的原理很簡單。蛋白質是生命的基本組成部分,由胺基酸序列構成。在讀取蛋白質時,需要按順序對胺基酸序列進行解讀,就像閱讀句子中的單詞一樣。
因此, Rost 等研究人員開始在研究中結合自然語言處理技術,以此了解蛋白質。但是,在九十年代,關於蛋白質的資料很少, AI 模型也遠不夠精細。
科技快速發展至今,已大不同於從前。
如今,定序變得更快速且成本更低,從而產生了海量資料集。同時,得益於現代 GPU ,在某些情況下,諸如 BERT 之類的高級 AI 模型能夠比人類更好地解讀語言。
AI模型複雜性增長6倍
AI 模型在自然語言處理方面的突破令人嘆為觀止。 18 個月前, Elnaggar 和 Heinzinger 發表了一份研究成果,研究中使用了一版包含 9,000 萬參數的循環神經網路模型。本月,他們又在研究中利用了具有 5.67 億參數的 Transformer 模型。
“Transformer 模型對算力的要求極高。因此,為了完成這項研究工作,我們在 Summit 超級電腦上使用了 5,616 個 GPU 。即便如此,部分模型的訓練也耗時兩日之久。” Elnaggar 表示。
而要在數千個 Summit 節點上運行模型,就更具挑戰。
Elnaggar 的這些經歷在超算領域不足為奇。他需要很有耐心,才能同步管理如此大規模的文件、儲存、通信、以及相關的開銷。他從小規模項目著手,基於幾個節點展開工作,一步步前行。

Elnaggar 表示:“好消息是,我們現在可以基於單一 GPU ,使用訓練後的模型,在實驗室中完成推理工作。”
預訓練AI模型現已面世
Elnaggar 和 Heinzinger 最新的論文於7 月發表。該論文描述了在各種工作任務下,應用幾種最新 AI 模型的優缺點。這項研究工作得到了COVID-19 高效能運算聯盟的資助。
他們還發布了首版預訓練模型。 Elnaggar 表示:“鑑於當下疫情,儘管項目仍在進展中,但我們覺得應儘早發布。”
Heinzinger 認為:“我們提出的方法有望改變蛋白質定序的方式。”
這項研究工作本身,可能並不能遏制冠狀病毒,但卻有望建立一個更高效率的全新研究平台,助力未來對抗病毒的工作。
跨學科合作
該專案也展現了科學領域兩條重要的經驗,即需要密切關注最新研究進展,並分享研究成果。
“正所謂擇善而從,適得其所。我們的研究進展正是得益於自然語言處理技術的進步。” Heinzinger 表示。
Elnaggar 對此也表示贊同:“正是通過跨學科合作,我們才能取得成功。”
在線上有更多關於研究人員提昇科學對抗 COVID-19 的故事。
主視覺顯示了經過訓練的語言模型,沒有標記的樣本會拾取DNA結合所需的蛋白質序列信號。