加快人工智慧在資料中心裡的推論表現
推論係將在強大 GPU 上完成訓練的精密神經網路,用於解決日常用戶問題的一項技術。
多數推論作業著重於「下班後」在大量 CPU 伺服器上完成大批次、高輸送量的作業,只是這個情況已經出現快速變化的局面。
未來推論領域朝向以更複雜的語音辨識、自然語言處理和翻譯模型為基礎,發展出必須有著低延遲性的精密即時服務。
NVIDIA Tesla 平台可大幅提高深度學習最重視,且有著龐大繁雜運算作業的「訓練」和「推論」表現,還能省下不少採購和能源費用。
深度學習的應用範圍不斷擴大,只使用 CPU 的伺服器已無力滿足這項需求。一台搭載 GPU 的伺服器可取代160台搭載 CPU 的伺服器,且能提供更高的低延遲性推論輸送表現,不只能滿足這項趨勢的需求,還能加快產出速度。
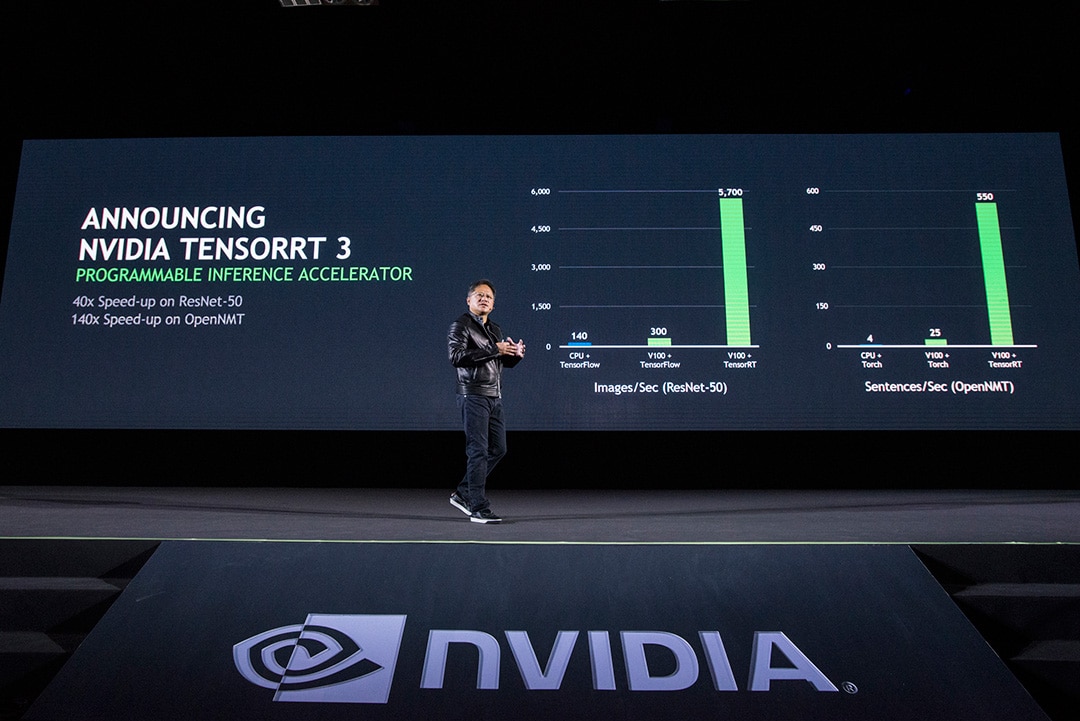
推出 TensorRT 3

推論表現不只跟速度有關,其實在評斷完整的推論表現時,必須考慮四大因素:輸送量、能源使用效率、延遲性和精確度。
我們推出全球首款可程式化的推論加速器 TensorRT 3,以充分發揮 NVIDIA 深度學習平台的推論表現和效率。TensorRT 3 會將經過訓練的神經網路進行壓縮、優化及部署成一個 runtime,以提供高精確度、低延遲性的推論內容,又沒有管理框架的成本。
TensorRT 的特色有:
加權 & 活化精度校準:將經 FP32 全精度訓練的模型量化為 INT8 且將精確度損失程度降至最低,大幅提高推論效能。
階層 & 張量融合:為單一核心執行將相連節點合併為單一節點,提升 GPU 使用率、優化記憶體儲存和頻寬
核心自動調校:為 Jetson、Tesla 或 DRIVE PX GPU 平台這些目標挑選最佳的資料層和最佳的平行演算法,以獲得最佳的執行時間
動態張量記憶體:只在使用期間對各張量配分記憶體,減少記憶體使用數量,提高再使用記憶體的程度
多串流執行:使用相同模型和加權,平行處理多個輸入串流內容

輸送量/延遲性/精確度:即時推論服務必須有著低延遲性,只搭載 CPU 的伺服器無法在7毫秒內提供推論結果,此時的延遲時間為14毫秒。Tesla GPU 將推論表現大幅提升了40倍,在7毫秒內便提供推論結果。TensorRT 3 以近乎零精確度損失的情況,提供優化後 INT8 和 FP16 精度的推論內容
研究團隊日前表示對於語音方面的用途,可接受將高延遲性門檻值調高到200毫秒。OpenNMT 是一套用於處理翻譯的遞歸神經網路(RNN),範例內係將英文翻為德文。

語音輸送量與延遲性:跟單純搭載 CPU 的伺服器相比,NVIDIA 推論平台輸送量為對手的150倍,延遲性還不到對方的一半,在200毫秒的目標延遲性門檻值裡完成這些工作。
為深度學習打造的平台必須具備三項特質,即擁有專為深度學習開發的處理器、軟體可程式化,加上為這套平台優化的產業架構,搭配全球各地可使用且採納的開發者生態體系。
NVIDIA 深度學習平台符合這三項特質,也是唯一一套端對端深度學習平台,從訓練到推論作業,從資料中心到網路邊緣皆可使用。
更多 NVIDIA 推論平台相關資訊。
效能比較係以使用 ImageNet 資料組訓練之 TensorFlow 神經網路消化後產生的 ResNet-50 神經網路為基礎。NVIDIA Tesla V100 GPU 運行 TensorRT 3 RC,對比 Intel Xeon-D 1587 Broadwell-E CPU 運行 Intel DL SDK 的組合。兩倍跑分是 Intel 對在 Skylake 核心配合 AVX512指令集能有兩倍的效能提升之聲明。