
企業若想利用人工智慧(AI)的力量,需根據其特定產業需求客製化模型。
NVIDIA AI Foundry 是一項服務,能夠讓企業利用資料、加速運算及軟體工具來創建和部署能夠增強其生成式 AI 計畫的客製化模型。
就像台積公司製造其他公司設計的晶片一樣,NVIDIA AI Foundry 提供基礎設施和工具,讓其他公司能夠透過使用 DGX Cloud、基礎模型、NVIDIA NeMo 軟體、NVIDIA 專業知識以及生態系工具和支援,開發和客製化 AI 模型。
關鍵差異在於產品:台積公司生產實體的半導體晶片,而 NVIDIA AI Foundry 則協助創建客製化模型。兩者都促進創新,並連結到龐大的的工具和合作夥伴生態系。
企業可以使用 AI Foundry 來客製化 NVIDIA 和開源社群模型,包括全新的 Llama 3.1 系列,以及 NVIDIA Nemotron、Google DeepMind 的 CodeGemma、CodeLlama、Google DeepMind 的 Gemma、Mistral、Mixtral、Phi-3、StarCoder2 等。
產業先驅推動 AI 創新
包括 Amdocs、Capital One、Getty Images、KT、SAP、ServiceNow、Snowflake 和 Together AI 等在內的產業領導者,已率先使用 NVIDIA AI Foundry。這些先驅正為企業軟體、技術、通訊和媒體領域的 AI 驅動創新的新時代奠定基礎。
ServiceNow 的 AI 產品副總裁 Jeremy Barnes 表示:「部署 AI 的組織可以透過整合產業和業務知識的客製化模型取得競爭優勢。ServiceNow 使用 NVIDIA AI Foundry 來微調和部署模型,這些模型能夠輕鬆整合到客戶現有的工作流程中。」
NVIDIA AI Foundry 的支柱
NVIDIA AI Foundry 依靠基礎模型、企業軟體、加速運算、專家支援和廣大的合作夥伴生態系等關鍵支柱運行。
其軟體包括來自 NVIDIA 和 AI 社群的 AI 基礎模型,以及完整的 NVIDIA NeMo 軟體平台,用於快速推進模型開發。
NVIDIA AI Foundry 的運算實力來自 NVIDIA DGX Cloud,這是一個與 Amazon Web Services、Google Cloud 和 Oracle Cloud Infrastructure 等全球領先的公共雲服務提供商共同開發的加速運算資源網路。借助 DGX Cloud,AI Foundry 的客戶可以前所未有的輕鬆和效率開發和微調客製化的生成式 AI 應用,並根據需要擴展其 AI 計劃,而無需在硬體上進行大量的前期投資。這種靈活性對於希望在快速變化的市場中保持敏捷的企業來說至關重要。
如果 AI Foundry 使用者需要協助,NVIDIA AI Enterprise 的專家隨時準備提供幫助。NVIDIA 專家可以指導客戶完成建構、微調和部署模型的每一步,並確保這些模型與其業務需求緊密結合。
NVIDIA AI Foundry 的客戶可以觸及全球合作夥伴生態系,獲得全方位的支持。包括 Accenture、Deloitte、Infosys和 Wipro 在內的 NVIDIA 合作夥伴提供 AI Foundry 諮詢服務,涵蓋設計、建置和管理 AI 驅動的數位轉型專案。Accenture 率先推出 Accenture AI Refinery 框架,一個基於 AI Foundry 的客製化模型開發服務。
此外,Data Monsters、Quantiphi、Slalom 和 SoftServe 等服務提供合作夥伴可協助企業處理將 AI 整合到現有 IT 環境中的複雜性,確保 AI 應用可擴展、安全並符合業務目標。
客戶可以使用 NVIDIA 合作夥伴提供的 AIOps 和 MLOps 平台開發用於生產的 NVIDIA AI Foundry 模型,這些合作夥伴包括 Cleanlab、DataDog、Dataiku、Dataloop、DataRobot、Domino Data Lab、Fiddler AI、New Relic、Scale 以及 Weights & Biases。
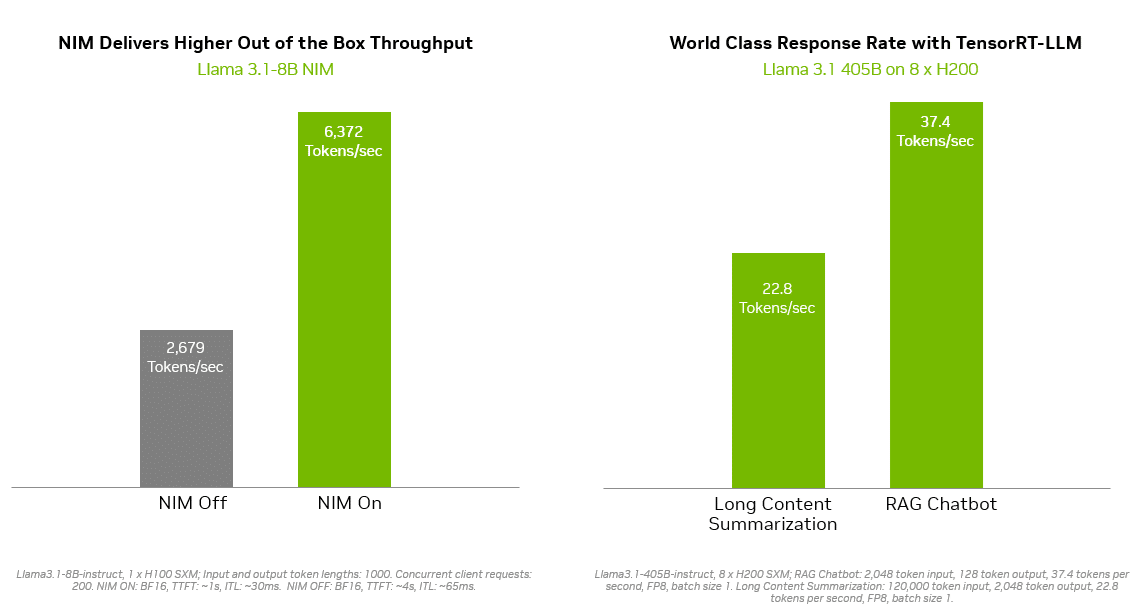
客戶可以將其 AI Foundry 模型輸出為包括客製化模型、最佳化引擎和標準 API 的 NVIDIA NIM 推論微服務,以便在他們首選的加速基礎架構上運行。
NVIDIA TensorRT-LLM 等推論解決方案提高了 Llama 3.1 模型的效率,從而最小化延遲並最大化吞吐量。這使企業能夠更快地產生詞元,同時降低在生產中運行模型的總成本。NVIDIA AI Enterprise 軟體套件提供企業級支援和安全性。
廣泛的部署選項包括來自思科、戴爾科技集團、慧與科技、聯想和美超微等全球伺服器製造夥伴所提供的 NVIDIA 認證系統,以及來自 Amazon Web Services、Google Cloud 和 Oracle Cloud Infrastructure 的雲端執行個體。
此外,業界領先的 AI 加速雲 Together AI 今天宣布,其超過十萬名開發者和企業的生態系能夠使用其 NVIDIA GPU 加速推論堆疊在 DGX Cloud 上部署 Llama 3.1 端點和其他開放式模型。
Together AI 創辦人暨執行長 Vipul Ved Prakash 表示:「每個運行生成式 AI 應用程式的企業都希望獲得更快的使用者體驗、更高的效率和更低的成本。現在使用 Together Inference Engine 的開發人員和企業可以最大化 NVIDIA DGX Cloud 的效能、可擴展性和安全性。」
NVIDIA NeMo 加速並簡化了客製化模型開發
透過將 NVIDIA NeMo 整合到 AI Foundry 中,開發人員可以輕鬆獲得管理資料、客製化基礎模型和評估效能所需的工具。 NeMo 技術包括:
- NeMo Curator 是一個 GPU 加速的資料管理函式庫,它透過準備大規模、高品質的資料集進行預先訓練和微調,從而提高生成式 AI 模型的效能。
- NeMo Customizer 是一種高效能、可擴展的微服務,可簡化針對特定領域用例大型語言模型的微調和調整。
- NeMo Evaluator 可在任何加速雲端或資料中心上跨學術和客製化基準自動評估生成式 AI 模型。
- NeMo Guardrails 協調對話管理,透過大型語言模型支援智慧型應用程式的準確性、適當性和安全性,為生成式 AI 應用提供保障。
使用 NVIDIA AI Foundry 中的 NeMo 平台,企業可以創建精確符合其需求的客製化 AI 模型。這種客製化使得模型更好地與策略目標保持一致,提升決策準確性,並增強營運效率。例如,企業可以開發能夠理解產業特定術語、遵守法規要求並與現有工作流程無縫整合的模型。
SAP 人工智慧長 Philipp Herzig 表示:「作為我們夥伴關係的下一步,SAP 計劃使用 NVIDIA 的 NeMo 平台來幫助企業強化由 SAP Business AI 提供動力的 AI 驅動的生產力。」
企業可以使用 NVIDIA NeMo Retriever NIM 推論微服務在生產中部署客製化 AI 模型。這些可協助開發人員獲取專有資料,透過檢索增強生成(RAG)為其 AI 應用程式產生知識豐富的回應。
Snowflake 人工智慧主管 Baris Gultekin 表示:「對於利用生成式 AI 的企業來說,安全可靠的 AI 是不可妥協的,檢索準確性直接影響 RAG 系統中生成回應的相關性和品質。Snowflake Cortex AI 利用 NVIDIA AI Foundry 的組件 NeMo Retriever,利用其客製化資料進一步為企業提供簡單、高效且可信的答案。」
客製化模型推動競爭優勢
NVIDIA AI Foundry 的主要優勢之一是能夠解決企業在採用 AI 時面臨的獨特挑戰。通用 AI 模型可能無法滿足特定的業務需求和資料安全要求。另一方面,客製化 AI 模型提供卓越的靈活性、適應性和效能,使其成為尋求競爭優勢的企業的理想選擇。
了解更多 NVIDIA AI Foundry 如何協助企業提高生產力和創新。