NVIDIA NeMo 是專為從事自動語音辨識(automatic speech recognition,ASR)、自然語言處理(natural language processing,NLP),以及文字轉語音合成(text-to-speech synthesis,TTS)之研究人員而打造的對話式人工智慧(Conversational AI)工具套件。NeMo 的主要目是協助產業界和學術界研究人員重新使用先前之作品,如程式碼和預先訓練模型,以更容易地建立新的對話式 AI 模型。NeMo 是一個開放原始碼專案,我們歡迎來自研究界的貢獻。
本次發表的 1.0 版本更新帶來重大的架構、程式碼品質和文件改進,以及眾多新的先進神經網路和多種語言的預先訓練檢查點。開始使用 NeMo 的最佳方式,是將其安裝在您常用的 PyTorch 環境中:
pip install nemo_toolkit[all]
NeMo 集合
NeMo 是 PyTorch 生態系統專案,主要仰賴生態系統中的另外兩個專案:PyTorch Lightning 用於訓練和 Hydra 用於配置管理。您也可以在任何 PyTorch 程式碼中使用 NeMo 模型和模組。
NeMo 具有三個主要集合:ASR、NLP、TTS。它們是模型和模組的集合,可以在對話式 AI 實驗中重新使用。最重要的是在大多數模型中,我們提供在各種資料集上使用數萬個 GPU 時數進行預先訓練的權重。
語音辨識
NeMo ASR 集合是最廣泛的集合,適合於各層級的研究人員,從初學者到進階。如果您剛接觸語音辨識深度學習,則建議您從 ASR 和 NeMo 互動式 notebok 概述開始。如果您是希望能建立自訂模型的資深研究人員,將可以找到各種現成的構件:
- 資料層
- 編碼器
- 擴增模組
- 文字正規化和反正規化
- 更進階的解碼器,例如 RNN-T
NeMo ASR 集合提供了各種類型的 ASR 網路:Jasper、QuartzNet、CitriNet、Conformer。在 NeMo 1.0 更新之後,CitriNet 和 Conformer 模型成為下一個旗艦 ASR 模型,提供比 Jasper 和 QuartzNet 更佳的單字錯誤率(word-error-rate,WER)準確性,同時能維持相同或更佳的效率。
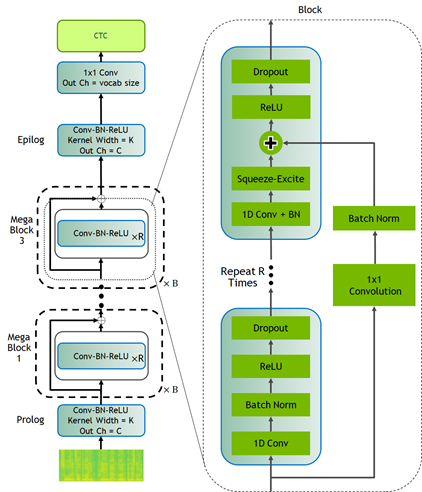
CitriNet
CitriNet 是針對 QuartzNet 改進後的版本,採用最初在 ContextNet 中導入的幾個構想。它是透過單字片段權杖化和 Squeeze-and-Excitation 機制,使用字根編碼取得高度準確的音訊轉錄,同時使用非自迴歸、以 CTC 為基礎的解碼方案進行高效率推論。
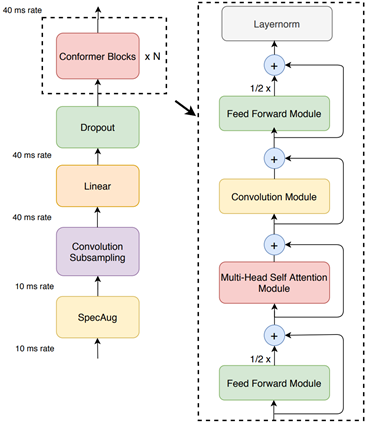
Conformer-CTC
Conformer-CTC 是以 CTC 為基礎的 Conformer 模型變體,是使用 CTC 損失和解碼,而不是 RNN-T 損失,因此是屬於非自迴歸模型。此模型結合了自注意力與卷積模組,而兼具兩者的優點。自注意力模組可以學習全域互動,卷積則能有效率地擷取局部相關性。
此模型可以讓您使用以注意力為基礎的模型進行實驗。由於是透過自注意力和 squeeze-and-excitation 機制取得全域脈絡,因此 Conformer 和 CitriNet 模型在離線情境下具有優異的 WER。
您可以將 Citrinet 和 Conformer 模型與 CTC 以及 RNN-T 解碼器搭配使用。
我們花費數萬個 GPU 時數,訓練各種語言的 ASR 模型。在 NeMo 中,我們免費為社群提供這些檢查點。截至此版本,NeMo 具有英文、西班牙文、中文、加泰隆尼亞文、義大利文、俄文、法文和波蘭文的 ASR 模型。此外,我們與 Mozilla 合作,在 Mozilla Common Voice 專案的輔助下提供更多預先訓練模型。
最後,NeMo 的 ASR 集合包含可以重新使用的構件和用於各種其他重要語音任務的預先訓練模型,例如:語音活動偵測、說話者辨識、分群、語音命令偵測。
自然語言處理
自然語言處理(NLP)對於提供優質的對話式 AI 體驗而言不可或缺。NeMo NLP 集合為典型 NLP 任務提供多種預先訓練模型,例如問題回答、標點符號和大寫、命名實體辨識、神經機器翻譯。
Hugging Face transformer 透過為開發人員和研究人員提供大量的預先訓練模型,以及易於使用的體驗,推動許多 NLP 的最新進步。NeMo 與 transformer 相容,大多數經過預先訓練的 Hugging Face NLP 模型都可以匯入 NeMo。您可以針對常見任務的編碼器,從 transformer 提供經過預先訓練的類 BERT 檢查點。常見任務的語言模型,是預設使用來自 Hugging Face transformer 的預先訓練模型進行初始化。
NeMo 同時與經過 NVIDIA Megatron 訓練的模型整合,讓您可以將以 Megatron 為基礎的編碼器,納入問題回答和神經機器翻譯模型中。NeMo 可以微調以 Megatron 為基礎的模型平行模型。
神經機器翻譯
在現今的全球化世界中,與使用不同語言的人溝通變得很重要。可以將原文轉換成另一種語言的對話式 AI 系統,將是強大的溝通工具。現在 NeMo 1.0 是透過以 transformer 為基礎的模型支援神經機器翻譯(neural machine translation,NMT)任務,讓您能快速地建立端對端語言翻譯工作流程。此版本包含下列語言之雙向翻譯的預先訓練 NMT 模型:
- 英文 <-> 西班牙文
- 英文 <-> 俄文
- 英文 <-> 中文
- 英文 <-> 德文
- 英文 <-> 法文
由於權杖化是 NLP 極重要的部分,因此,NeMo 可以支援最廣泛使用的權杖化工具,例如 HF 權杖化工具、SentencePiece、YouTokenToMe。
語音合成
如果人類可以對電腦說話,則電腦也應能回話。語音合成是輸入文字,並輸出擬人化音訊。通常是透過兩個模型完成:根據文字產生聲譜圖的聲譜圖產生器,以及根據聲譜圖產生音訊的聲碼器。NeMo TTS 集合提供以下模型:
- 預先訓練聲譜圖產生器模型: Tacotron2、GlowTTS、Fastspeech、Fastpitch、Talknet
- 預先訓練聲碼器模型:HiFiGan、MelGan、SqueezeWave、Uniglow、WaveGlow
- 端對端模型:FastPitchHiFiGAN、Fastspeech2 Hifigan
端對端對話式 AI 範例
以下以簡單的範例,示範如何使用 NeMo 製作通用翻譯器應用程式的原型。此應用程式可以接收俄文音訊檔案,並產生英文翻譯音訊。您可以使用 AudioTranslationSample.ipynb notebook 玩玩看。
# Start by importing NeMo and all three collections
import nemo
import nemo.collections.asr as nemo_asr
import nemo.collections.nlp as nemo_nlp
import nemo.collections.tts as nemo_tts
# Next, automatically download pretrained models from the NGC cloud
quartznet = nemo_asr.models.EncDecCTCModel.from_pretrained(model_name="stt_ru_quartznet15x5")
# Neural Machine Translation model
nmt_model = nemo_nlp.models.MTEncDecModel.from_pretrained(model_name='nmt_ru_en_transformer6x6')
# Spectrogram generator that takes text as an input and produces spectrogram
spectrogram_generator = nemo_tts.models.Tacotron2Model.from_pretrained(model_name="tts_en_tacotron2")
# Vocoder model that takes spectrogram and produces actual audio
vocoder = nemo_tts.models.WaveGlowModel.from_pretrained(model_name="tts_waveglow_88m")
# First step is to transcribe, or recognize, what was said in the audio
russian_text = quartznet.transcribe([Audio_sample])
# Then, translate it to English text
english_text = nmt_model.translate(russian_text)
# Finally, convert it into English audio
# A helper function that combines Tacotron2 and WaveGlow to go directly from
# text to audio
def text_to_audio(text):
parsed = spectrogram_generator.parse(text)
spectrogram = spectrogram_generator.generate_spectrogram(tokens=parsed)
audio = vocoder.convert_spectrogram_to_audio(spec=spectrogram)
return audio.to('cpu').numpy()
audio = text_to_audio(english_text[0])
此範例最棒的部分,是可以微調在資料集上使用的所有模型。針對領域微調是提高模型在特定應用方面之效能的絕佳方式。NeMo GitHub 儲存庫提供了許多微調範例。
NeMo 模型具有共同的外觀和風格,無論領域為何。它們的配置、訓練和使用方式相同。
使用 NeMo 進行擴充
進行實驗與快速測試新構想的能力,是研究成功的關鍵。擁有 NeMo,可以使用最新的 NVIDIA Tensor 核心,以及跨多個節點和數百個 GPU 的模型平行訓練功能加快訓練。大部分功能都是在 PyTorch Lightning 訓練器的輔助下提供,其具有直覺化與易於使用的 API。
我們針對語音辨識、建立語言模型和機器翻譯,提供以高效能網路資料集為基礎的資料載入器。這些資料載入器可以擴充至數萬小時的語音資料,進而在具有數千個 GPU 的大規模分散式環境中提供高效能。
使用 NeMo 進行文字處理和資料集建立
適當準備訓練資料以及預處理和後處理,是在所有機器學習工作流程中極重要,卻經常受到忽視的步驟。NeMo 1.0 的新功能,包括資料集建立和語音資料瀏覽器。
NeMo 1.0 包含重要的文字處理功能,例如文字正規化和文字反正規化。文字正規化可以將文字從書面形式轉換成口頭形式。它是訓練 TTS 模型之前的預處理步驟。它也可以針對 ASR 訓練轉錄進行預處理。文字反正規化是反向操作,通常是 ASR 後處理工作流程的一部分。其任務為將 ASR 模型的原始口語輸出轉換成書面形式,以提高文字可讀性。例如,「重 10 kg」的正規化版本,將是「重 10 公斤」。
結論
NeMo 1.0 版本大幅改進了整體的品質和文件。它增加了對新任務的支援,例如神經機器翻譯及許多以不同語言預先訓練的新模型。它是成熟的 ASR 和 TTS 工具,增加了文字正規化和反正規化、以 CTC 分割為基礎的資料集建立、語音資料瀏覽器等新功能。這些更新讓您可以更輕鬆地開發和訓練新的對話式 AI 模型,以造福學術界和產業界的研究人員。
許多 NeMo 模型都可以匯出至 NVIDIA Riva ,以進行生產部署和高效能推論。NVIDIA Riva 是一種加速 SDK,用於建構可以在 GPU 上提供即時效能的多模態對話式 AI 服務。
我們歡迎外部貢獻!您可以在 NVIDIA NeMo GitHub 頁面上試用範例、參與社群討論,並使用 NeMo 和 NVIDIA Riva,將模型從研究推進至生產。