
許多資料處理任務具有平行性,GPU 的大規模平行架構理所當然應能平行化並加快 Apache Spark 資料處理查詢,就如同 GPU 加速人工智慧(AI)中的深度學習一般。
NVIDIA 與 Apache Spark 社群合作,透過發布 Spark 3.0 以實現 GPU 加速以及用於 Spark 的新開源 RAPIDS 加速器。在本文中,我們將深入探討用於 Apache Spark 的新開源 RAPIDS 加速器如何利用 GPU:
- 在同一 Spark 叢集上加快端對端資料準備和模型訓練。
- 加快 Spark SQL 和 DataFrame 操作而不需任何程式碼變更。
- 加快節點之間的資料傳輸(Spark Shuffle)效能。
Spark 2.x 上的資料準備和模型訓練
GPU 在過去幾年內促成深度學習和機器學習模型訓練的進步。然而,資料科學家有 80% 的時間是花在資料預處理上。
為機器學習準備資料集必須瞭解資料集、清理和操控資料類型與格式,以及為學習演算法擷取特徵。這些任務統稱為 ETL(extract 擷取、transfer 轉換、load 載入)。ETL 通常是反覆的探索性流程。
隨著機器學習和深度學習逐漸被應用在較大的資料集,Spark 已變成學習階段準備原始輸入資料所需的資料預處理和特徵工程的常用工具。由於 Spark 2.x 不具備 GPU 相關知識,因此資料科學家和工程師在 CPU 上執行 ETL,然後將資料傳送至 GPU 進行模型訓練。這是真正發揮效能之處。隨著資料集增加,此流程的互動性開始減弱。
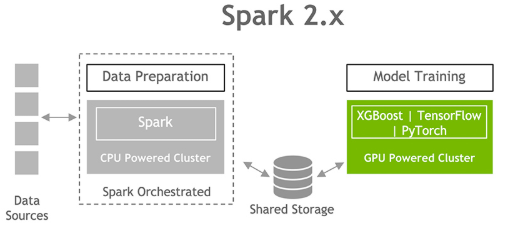
加速端對端資料分析和機器學習工作流程
Apache Spark 社群致力於將此端對端流程的兩個階段結合,讓資料科學家可使用單一Spark叢集,免去在階段之間移動資料的麻煩。
Apache Spark 3.0 象徵重要的里程碑,因為 Spark 現在可以在搭載 GPU 的 Spark 叢集上調度 GPU 加速機器學習和深度學習應用程式,以消除瓶頸、提高效能並簡化叢集。
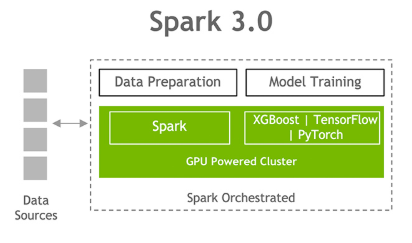
資料準備以至模型訓練的單一工作流程。
圖 3 所示為此加速資料科學的完整堆疊。

圖 4 所示為 Spark 搭配 GPU 的資料預處理時間改善結果。Criteo Terabyte Click Logs 公開資料集是用於推薦任務的最大公開資料集之一,可證明 GPU 最佳化 DLRM 訓練管道的效率。八個 V100 32-GB GPU 加快處理時間,比同等的 Spark-CPU 工作流程快 43 倍。
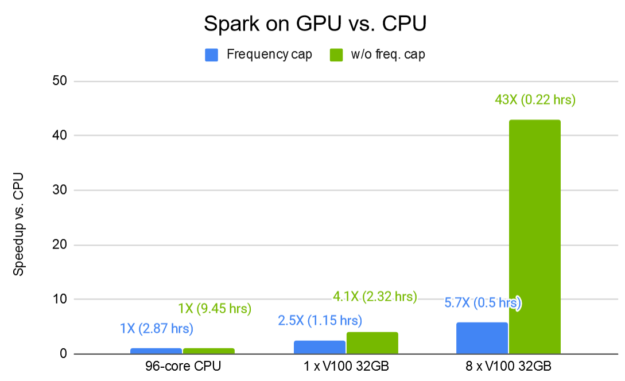
長條表示 GPU 與 CPU 相較之下的加速倍數,越高越好。
接著,我們將探討 Apache Spark 3.0 中促成明顯 GPU 加速的主要關鍵:
- 新的用於 Apache Spark 3.0 的 RAPIDS 加速器
- RAPIDS 加速 Spark SQL/DataFrame 和 shuffle 作業
- Spark 中的 GPU-aware scheduling
用於 Apache Spark 的 RAPIDS 加速器
RAPIDS 是由開放原始碼軟體函式庫和 API 所組成的套件,完全在 GPU 上執行端對端資料科學和分析工作流程,能大幅加速,尤其是大型資料集。用於 Apache Spark 的 RAPIDS 加速器是以 NVIDIA CUDA 和 UCX 為基礎,透過 Spark SQL 和 DataFrame API 及新的 Spark shuffle 建置,讓應用程式能利用 GPU 平行性和高頻寬記憶體速度,且不需要改寫程式碼。
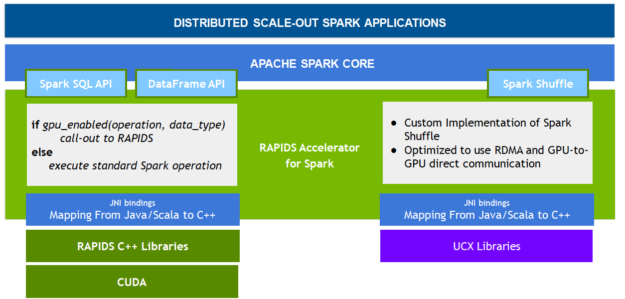
RAPIDS 加速 Spark SQL 和 DataFrame
RAPIDS 提供以 Apache Arrow 資料結構為基礎的強大 GPU DataFrame。Arrow 指定了標準化、不受語言影響的欄式記憶體格式,針對資料局部性而最佳化,以加快現代 CPU 或 GPU 的分析處理效能。透過 GPU DataFrame,來自多個紀錄的欄值批次可利用現代 GPU 設計並加快讀取、查詢和寫入。

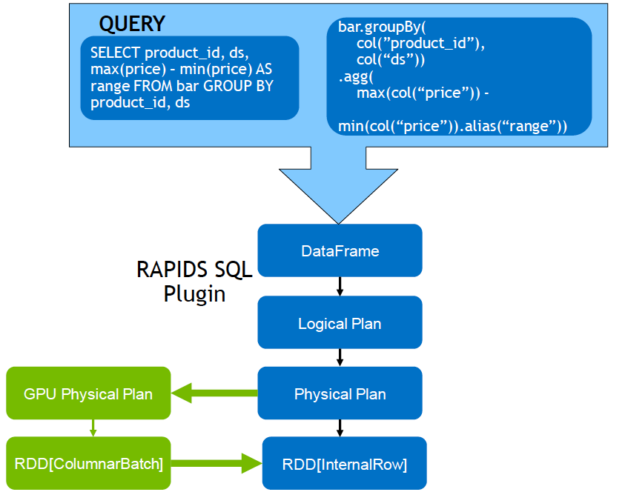
就 Apache Spark 3.0 而言,Spark SQL 和 DataFrames 是使用新的 RAPIDS API 進行 GPU 加速高記憶體效率欄式資料處理和查詢計畫。Spark 查詢執行時會經過下述步驟:
- 建立邏輯計畫
- 透過 Catalyst 查詢最佳化工具將邏輯計畫轉換成實體計畫
- 產生程式碼
- 在叢集上執行任務
透過 RAPIDS 加速器對 Catalyst 查詢最佳化工具進行修改,以識別查詢計畫中可利用 RAPIDS API 加速的 operator,多半是一對一對應。執行查詢計畫時,它也可在 Spark 叢集中的 GPU 上調度這些 operator。
透過 CPU 的實體計畫,DataFrame 資料被轉換成 RDD 列格式,通常一次處理一列。Spark 支援欄式批次,但在 Spark 2.x 中只有 Vectorized Parquet 和 ORC 讀取器才會使用。RAPIDS 外掛程式將 GPU 上的欄式批次處理延伸至大多數 Spark 操作。
RAPIDS 加速 Spark shuffle
根據階段之間的現有 DataFrame 建立新的 DataFrame 時,依值排序、分類或合併資料的 Spark 操作必須透過稱為 shuffle 的流程在分割區之間移動資料。
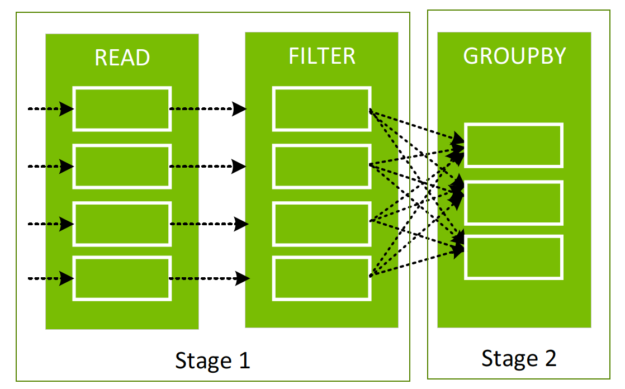
依值分類並在分割區(白色矩形)之間交換資料。
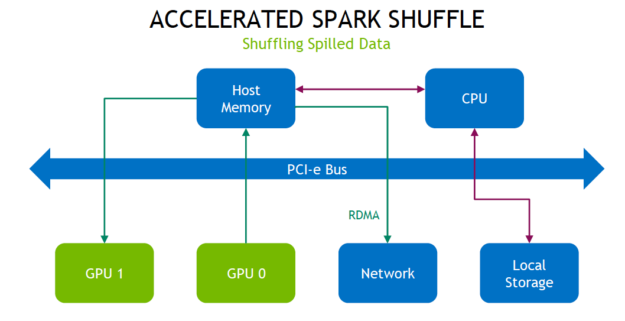
Shuffle 先將資料寫入至本機磁碟,然後透過網路將資料傳輸至其他 CPU 或 GPU 上的分割區。就 CPU、RAM、磁碟、網路和 PCI-e 匯流排流量而言 shuffle 的代價高昂,因為其涉及磁碟 I/O、資料序列化和網路 I/O。
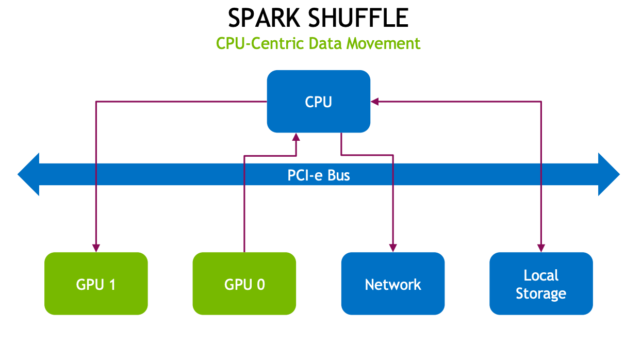
及 PCI-e 匯流排流量和壅塞。
新的 Spark shuffle 建置是以 GPU 加速 Unified Communication X (UCX) 函式庫為基礎,大幅改善了 Spark 流程之間的資料傳輸。UCX 公開了抽象通訊基本集合,其充分利用可用的硬體資源和卸載,包括 RDMA、TCP、GPU、共用記憶體和網路原子操作。
在新的 shuffle 流程中,首先盡可能在 GPU 上快取資料。這表示該 GPU 上的下一個任務不進行資料 shuffle。接著,如果 GPU 在同一節點上並與 NVIDIA NVLink 高速互連連接,則以 300 GB/s 的速度傳輸資料。如果 GPU 在不同節點上,則 RDMA 允許 GPU 以高達 100 Gb/s 的速度跨節點直接與彼此通訊。兩種情況都可避免 PCI-e 匯流排和 CPU 上的流量。
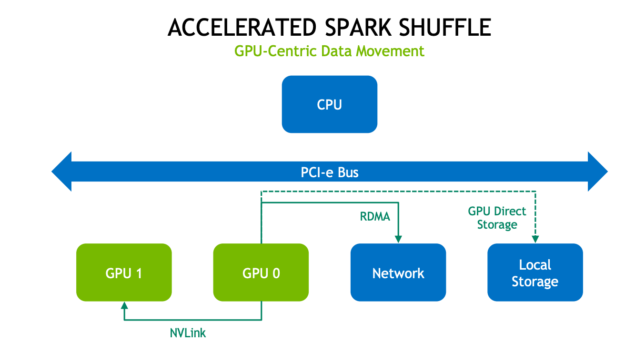
如果 shuffle 資料無法全部在本機快取,則先推送至主機記憶體,耗盡後再溢出至磁碟。從主機記憶體擷取資料可使用 RDMA 傳輸可避免 PCI 匯流排流量。
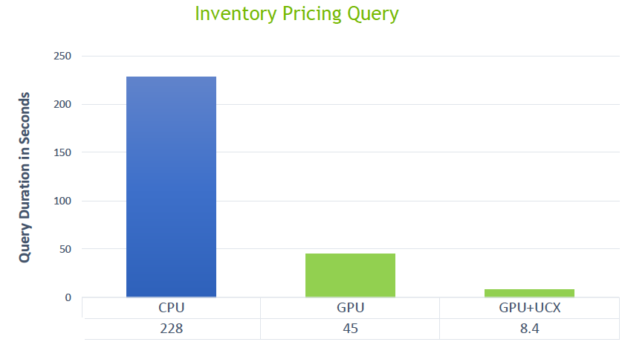
加速 shuffle 結果
圖 12 所示為新的 Spark shuffle 建置執行加速結果,透過 192 個 CPU 核心和 32 個 GPU ,以 10 TB 規模執行庫存定價查詢。標準 Spark-CPU shuffle 花了 228 秒,而使用 GPU 搭配 UCX 的新 shuffle 則是 8.4 秒。
相較之下的加速倍數,越低越好。
圖 13 所示為對溢出至磁碟的 800 GB 資料進行 shuffle 的 ETL 查詢結果。使用 GPU 搭配 UCX 花了 79 秒,而 CPU 則是 1,555 秒。
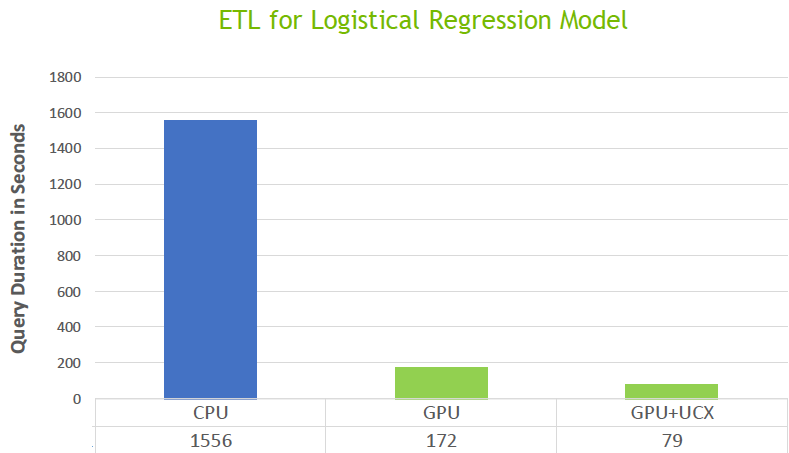
相較之下的加速倍數,越低越好。
Spark 中的 GPU-aware Scheduling
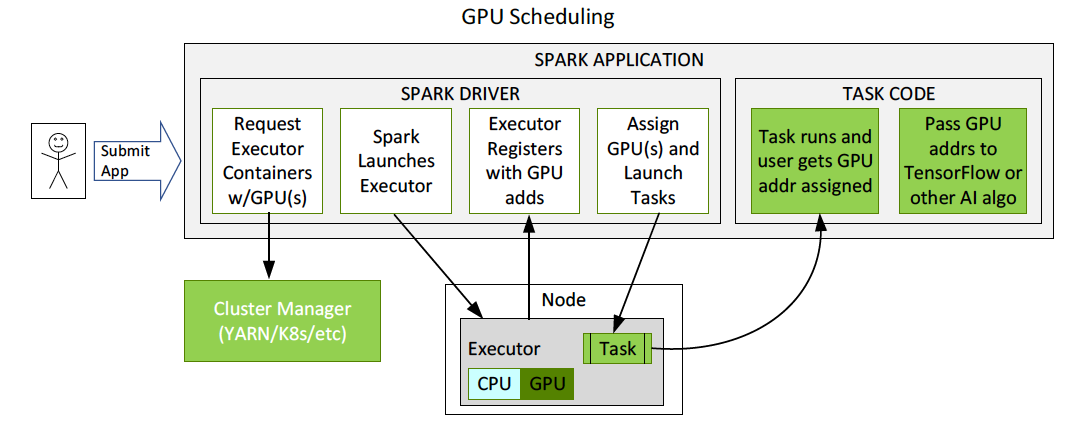
GPU 現已是 Apache Spark 3.0 中的可調度資源。這讓 Spark 可以調度具有指定數量 GPU 的執行程式,且可以指定每項任務需要多少 GPU。Spark 將這些資源要求傳達給基礎叢集管理器、Kubernetes、YARN 或 standalone 模式。也可以配置探索指令碼以偵測叢集管理器分配了哪些 GPU。這大幅簡化了執行需要 GPU 的機器學習應用程式,因為過去必須解決 Spark 應用程式中缺少 GPU 調度的問題。
圖 14 所示為 GPU 調度流程的例子。使用者提交具有 GPU 資源配置探索指令碼的應用程式。Spark 啟動驅動程式,驅動程式使用該配置傳遞給叢集管理器,以要求具有指定數量的資源和 GPU 的容器。叢集管理器回傳容器。Spark 啟動容器。執行程式啟動時會執行探索指令碼。Spark 將該資訊傳回至驅動程式,驅動程式隨後可使用該資訊將任務調度至 GPU。
後續步驟
在本文中,我們探討新的用於 Apache Spark 的 RAPIDS 加速器如何實現端對端資料分析工作流程、Spark SQL 操作和 Spark shuffle 操作的 GPU 加速。
- 如需更多關於利用 GPU 和 RAPIDS 加快 Apache Spark 3.0 的資訊,請觀看 GTC 2020 和 Deep Dive into GPU Support in Apache Spark 3x Spark AI Summit 會議。
- 欲深入探索 Apache Spark 3.0,請下載免費的 Apache Spark 3.0 電子書。
- 欲深入瞭解 Apache Spark 3.0 版本,請造訪 Apache Software Foundation。
- 若要取得 RAPIDS Accelerator for Apache Spark 和入門指南,請造訪 nvidia/spark-rapids GitHub 儲存庫。
若要查看 Databricks Platform 平台上的 CPU 叢集效能與 GPU 叢集效能的並排比較,請觀看 Spark 3 Demo:Comparing Performance of GPUs vs.CPUs 的示範影片。