就像是人們普遍理解的自然經驗定律一樣,例如有上必有下,或者每個動作都有相等和相反的反應,人工智慧(AI)領域長期以來都是由單一想法所定義:更多的運算、更多的訓練資料和更多的參數,就可以產生更好的 AI 模型。
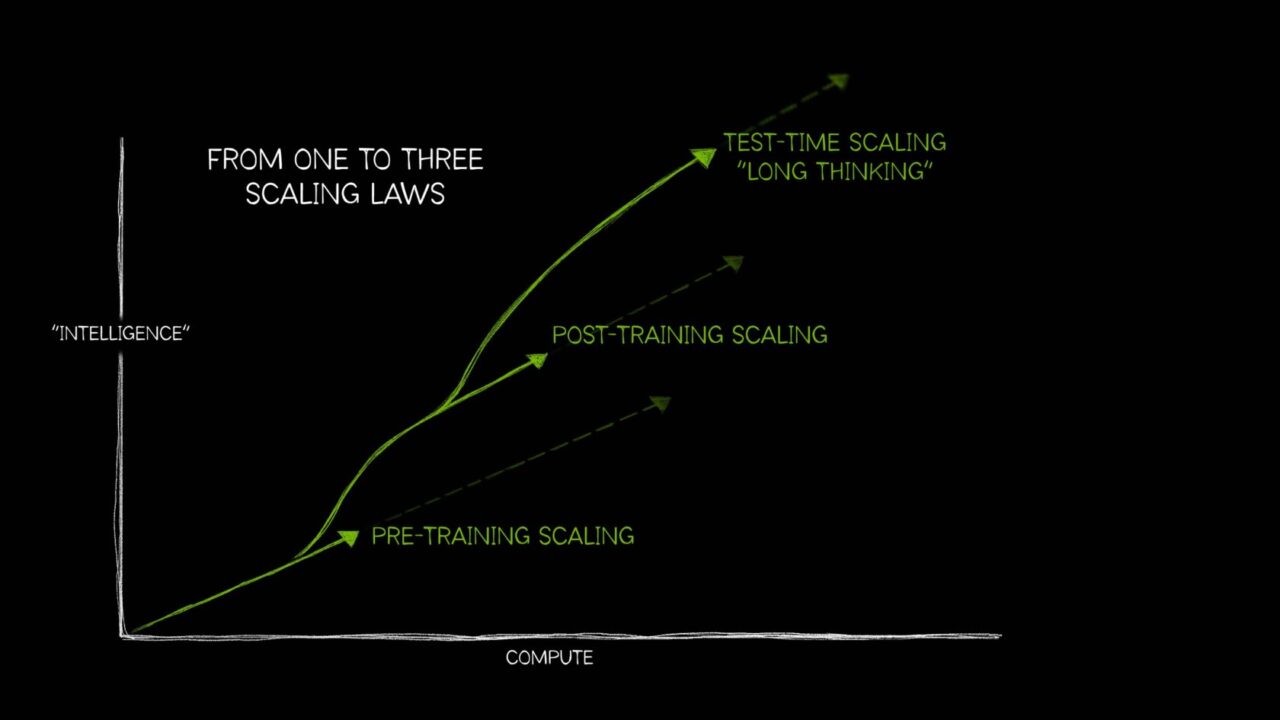
然而,AI 發展至今,需要三個不同的定律來描述不同方式利用運算資源如何影響模型效能。這些 AI 擴展定律合在一起,包含預訓練擴展(pretraining scaling)、訓練後擴展(post-training scaling),以及又稱為長思考(long thinking)的測試階段擴展(test-time scaling),反映出 AI 領域如何在各種日益複雜的 AI 用例中運用額外的運算技術演進發展。
近期興起的測試階段擴展,也就是在推論階段應用更多運算來提高準確度,已經實現 AI 推理模型這類新式的大型語言模型(LLM),以執行多次推論來處理複雜的問題,同時描述解決任務所需的步驟。測試階段擴展需要用到大量運算資源來支援 AI 推理,這將進一步推動對加速運算的需求。
什麼是預訓練擴展?
預訓練擴展是 AI 發展的原始定律。它證明透過增加訓練資料集大小、模型參數數量和運算資源,開發人員可以期望模型智慧和準確度會出現可預期的改善。
資料、模型大小、運算這三個要素中的每一個都息息相關。根據本篇研究論文所概述的預訓練擴展定律,當大型模型獲得更多資料時,模型的整體效能就會提高。為了實現這個目標,開發人員必須擴大運算規模,這就需要強大的加速運算資源來運行那些較大的訓練工作負載。
這種預訓練擴展原則使得大型模型達到突破性的能力。它還激發了模型架構的重大創新,包括有著數十億個和上兆個參數的 transformer 模型、混合專家模型和新式分散式訓練技術的興起,而這一切都需要大量的運算。
而預訓練擴展定律的相關性仍在不斷發展,隨著人類持續產生越來越多的多模態資料,這些文字、影像、音訊、影片和感測器資訊的寶藏庫將會被用來訓練未來強大的 AI 模型。
什麼是訓練後擴展?
預先訓練大型基礎模型並非人人適用,這需要大量投資、熟練的專家和資料集。然而,一旦組織預先訓練好並發布模型,就能讓其他人使用其預先訓練的模型當成基礎,以配合自己的應用,從而降低採用 AI 的門檻。
這種訓練後的流程會推動企業及更廣泛的開發人員社群對加速運算的額外累積需求。受歡迎的開源模型可能有著上百個或上千個在多個領域裡訓練出的衍生模型。
針對各種用例開發衍生模型的生態系,可能需要比預先訓練原始基礎模型多出約 30 倍的運算時間。
訓練後技術可以進一步提升模型的特異性,以及與組織所需用例的相關性。預訓練擴展就像是將 AI 模型送去學校學習基本技能,而訓練後擴展則是增強模型適用於其預期工作的技能。比如一個大型語言模型可以經過訓練後擴展來處理情感分析或翻譯等任務,或是理解醫療保健或法律等特定領域的術語。
訓練後擴展定律假設使用微調、剪枝、量化、蒸餾、強化學習和合成資料增強等技術,可以進一步改善預訓練模型在運算效率、準確性或領域特異性方面的效能。
- 微調(fine-tuning)使用額外的訓練資料,針對特定領域和應用量身打造 AI 模型。這可以使用組織的內部資料集,或是成對的樣本模型輸入和輸出內容來完成。
- 蒸餾(distillation)需要使用一對 AI 模型:一個大型複雜的教師模型和一個輕量級的學生模型。在離線蒸餾這個最常見的蒸餾技術中,學生模型學習模仿預先訓練的教師模型的輸出。
- 強化學習(reinforcement learning,RL)是一種機器學習技術,它使用獎勵模型來訓練代理做出符合特定用例的決定。代理的目標是在與環境互動的過程中,隨著時間的推移做出累積獎勵最大化的決策,例如聊天機器人大型語言模型會受到使用者做出「按讚」反應的正向強化。這種技術稱為基於人類回饋的強化學習(RLHF)。另一種較新的技術是基於 AI 回饋強化學習(RLAIF),它使用 AI 模型的回饋來引導學習過程,簡化訓練後的工作。
- 最佳解搜尋採樣(Best-of-n sampling)會從語言模型產生多個輸出,並根據獎勵模型選擇獎勵分數最高的一個。它通常用來提高 AI 的輸出,而不需要修改模型參數,提供一種使用強化學習進行微調的替代方法。
- 搜尋方法會在選擇最終輸出之前探索一系列潛在的決策路徑。這種訓練後擴展技術可以反覆改善模型的反應。
為了支援訓練後擴展,開發人員可以使用合成資料來增強或補充微調資料集。使用 AI 產生的資料來補充現實世界的資料集,有助於模型改善處理原始訓練資料中代表性不足或遺漏的邊緣案例的能力。

什麼是測試階段擴展?
大型語言模型會對輸入提示做出快速回應。這個過程非常適合用來獲得簡單問題的正確答案,但當使用者提出複雜的詢問,這個流程可能就沒那麼好使用。要回答複雜的問題,大型語言模型必須先對問題進行推理,才能給出答案,而回答複雜的問題是代理型 AI 工作負載的基本能力。
這跟大多數人的思考方式類似,在被問到二加二的答案時,他們會馬上脫口而出,而不需要講解加法或整數的基本原理。可是萬一當場被要求制定一個可以讓公司利潤成長 10% 的商業計畫時,人們可能會透過各種選項進行推理,並且提供一個多步驟的答案。
測試階段擴展也稱為長思考,發生在推論過程中。傳統的 AI 模型會快速針對使用者的提示產生一次性答案,而使用這項技術的模型則會在推論過程中分配額外的運算工作,讓模型在得出最佳答案前先推理出多個可能的回應。
在為開發人員生成複雜的客製化程式碼等工作上,這個 AI 推理過程可能需要幾分鐘,甚至幾小時的時間,而且相較於傳統大型語言模型的單次推論,高難度的查詢可能需要超過 100 倍的運算量,因為傳統大型語言模型不太可能在第一次嘗試時,就能對複雜的問題產生正確的答案。
這種測試階段運算能力可以讓 AI 模型探索問題的不同解決方案,並將複雜的要求拆解成多個步驟,在許多情況下,在推理過程中向使用者展示其工作。研究發現,當給予 AI 模型需要多個推理與規劃步驟的開放式提示時,測試階段擴展可以獲得更高品質的回應。
測試階段運算方法有多種方法,包括:
- 思維鏈(chain-of-thought)提示:把複雜的問題分解成一系列更簡單的步驟。
- 多數決抽樣:針對同一個提示產生多個回應,然後選擇最常出現的答案作為最終輸出。
- 搜尋:探索與評估回覆樹狀結構裡的多個路徑。
類似最佳解搜尋採樣的訓練後擴展方法也可用於推論過程中的長思考,以最佳化符合人類喜好或其他目標的回應。

測試階段擴展如何進行 AI 推理
測試階段運算技術的興起,讓 AI 有能力對使用者所提出複雜、開放式的查詢項目,提供有理有據、有幫助且更加準確的回應。這些能力對於自主代理型 AI 及實體 AI 應用所期待的詳細、多重推理任務來說至關重要。它們可以為各產業的使用者提供能力強大的助理來加速工作,從而提高效率和生產力。
在醫療保健領域,模型可以使用測試階段擴展技術來分析大量資料,推斷疾病的發展情況,以及根據藥物分子的化學結構,預測新療法可能產生的潛在併發症。或者,它可以梳理臨床試驗資料庫,建議符合個人病況的方案,分享其對不同研究利弊的推理過程。
在零售和供應鏈物流領域,長思考有助於解決近期營運挑戰和長期策略目標所需的複雜決策。推理技術可以同時預測與評估多種情境,協助企業降低風險,並因應在擴充方面的難題。這可以實現更精準的需求預測、簡化供應鏈行程路線,以及做出符合組織永續發展計畫的採購決策。
對於全球企業而言,這項技術可應用於草擬詳細的商業計畫、產生複雜的程式碼以對軟體進行除錯,或是最佳化貨車、倉儲機器人和無人駕駛計程車的行駛路線。
AI 推理模型發展迅速。OpenAI o1-mini 和 o3-mini、DeepSeek R1 以及 Google DeepMind 的 Gemini 2.0 Flash Thinking 都是在過去幾週推出,預計不久後還會有更多新的模型問世。
這些模型在推理過程中需要使用大量運算,才能對複雜問題進行推理與產生正確答案,這表示企業需要擴充加速運算資源,以提供能夠解決複雜問題、編寫程式碼和規劃多步驟的下一代AI推理工具。
了解 NVIDIA AI 在加速推論方面的優勢。