
人們最常使用深度學習神經網路執行許多人工智慧任務。資料科學家使用 TensorFlow 和 PyTorch 等軟體框架,開發和運行深度學習演算法。
目前已有許多介紹深度學習的文章,且可以從不同來源找到更詳細的資訊。人工智慧、機器學習與深度學習間有什麼區別?一文針對深度學習提供了極佳的總結。
在雲端環境中運行這些框架,是一種進入深度學習領域的熱門方式。但是企業在人工智慧專業知識發展及成熟之後,即開始想要在自己的資料中心內運行這些框架,以避免雲端人工智慧的成本和其他困境。
在本文中,我將討論如何挑選深度學習訓練的企業伺服器。我將回顧符合此項獨特工作負載的具體運算要求,然後討論如何挑選最佳組件配置以滿足這些需求。
深度學習訓練的系統需求
深度學習訓練通常是設計成一個資料處理工作流程。原始輸入資料必須依據資料格式、大小及其他因素準備。
資料通常會預先處理,以便使用不同方式呈現同一個輸入模型的內容,主要取決於資料科學家確定將產生更強大的訓練資料集。例如可以隨機旋轉影像,以使模型學會在不考慮方向的情況下辨識物體。之後,將準備的資料輸入深度學習演算法。
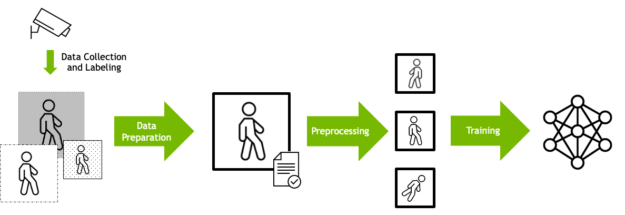
在瞭解深度學習訓練的工作原理之後,以下是使用最快速、最高效方式執行此項任務的具體運算需求。
GPU
深度學習的核心是 GPU。運算網路每一層數值的過程,最終會變成一組巨大的矩陣乘法。通常可以使用各層之間的協調步驟,平行處理每一層的資料。
GPU 是設計為可以大規模平行執行矩陣乘法,且經證明是大幅提升深度學習執行速度的理想選擇。
在進行訓練時,模型大小為驅動因素,因此具有更大、更快記憶體的 GPU時,例如 NVIDIA A100 Tensor 核心 GPU,即能更快地批次處理訓練資料。
CPU
儘管近期的創新技術已在 GPU 上進行深度學習訓練的資料及預先處理運算作業,通常仍會在 CPU 上進行。
使用高效能 CPU 以高速維持這些操作,GPU 才不會因為等待資料而饑腸轆轆。建議使用企業級 CPU,例如 Intel Xeon Scalable 處理器系列或 AMD EPYC 系列,且 CPU 的核心與 GPU 的比例應為適合大小,才能維持工作流程順暢運行。
系統記憶體
尤其是在處理現今最大的模型時,深度學習訓練只有在需要大量輸入資料訓練時才有效。將這些資料從儲存裝置中分批取出,然後在系統記憶體中由 CPU 進行處理,接著送入 GPU。
為了保持此過程可以持續運作,應具有足夠的系統記憶體,CPU 的處理速度才能應對 GPU 處理資料的速度。這可以使用系統記憶體與 GPU 記憶體的比例來表示(在伺服器的所有 GPU)。
不同模型與演算法需要不同的比例,但最好是維持較高的比例,GPU 才無須一直等待資料。
網路介面卡
隨著深度學習模型變得愈來愈大,已經發展出使用多個 GPU 共同運作以進行訓練的技術。當伺服器中安裝了一個以上的 GPU 時,可以藉由 PCIe 匯流排相互傳遞資料,且能使用 NVLink 和 NVSwitch 等更專業的技術,提升至最高效能。
多 GPU 訓練也可以擴大至在跨多個伺服器上執行。於此情形下,網路介面卡成為設計伺服器的個重點部分。在進行多節點深度學習訓練時,必須使用高頻寬的乙太網路或 InfiniBand 網路介面卡,盡可能地減少資料傳輸造成的瓶頸。
深度學習框架是利用 NCCL 類型的函式庫,以高效能之最佳方式協調 GPU 之間的作業。GPUDirect RDMA 等技術,讓資料可以直接從網路傳輸至 GPU,無須通過 CPU,進而能消除造成延遲的來源。
在理想的情況下,系統中的每一個或兩個 GPU 應搭配一張網路介面卡,以便在必須傳輸資料時,盡可能減少爭奪的情況。
儲存裝置
深度學習訓練資料通常是儲存在外部儲存裝置陣列上。伺服器上的 NVMe 驅動器可以提供資料快取服務,大幅加快訓練過程。
深度學習的 I/O 模式通常是由反覆多次讀取訓練資料的方式組成。訓練的第一遍(或稱為 epoch)是讀取啟動訓練模型的資料。若節點上有充分的本地快取空間,則後續在傳遞資料時,即無須從遠端儲存裝置重新讀取資料。
每一個 CPU 應該具有一個 NVMe 驅動器,以避免在從遠端儲存裝置中提取資料時發生爭奪。
PCIe 拓撲
CPU、GPU 與網路之間具有複雜的相互作用,應清楚瞭解必須在設計連線時,減少深度學習訓練工作流程中的任何潛在瓶頸,才能達到最佳效能。
現在大多數企業伺服器都是使用 PCIe,做為在組件之間傳遞資料的方法。PCIe 匯流排上的主要流量是發生在以下路徑上:
- 從系統記憶體到 GPU
- 在進行多 GPU 訓練時,同一台伺服器上的 GPU 之間
- 在進行多節點訓練時,GPU 與網路介面卡之間
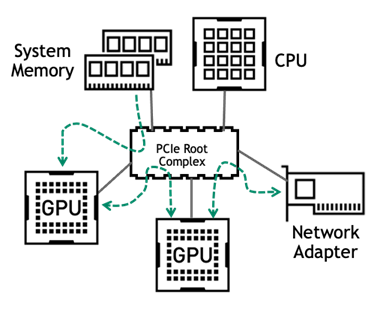
深度學習的伺服器應具有平衡的 PCIe 拓撲結構,GPU 是平均分布在 CPU 插槽與 PCIe 根連接埠上。在所有情況下,每一個 GPU 之 PCIe 通道的數量,應為支援的最大數量。
若有多個 GPU,且來自於 CPU 的 PCIe 通道數量不足以容納所有的 GPU 時,可能需要使用 PCIe 交換器。於此情況下,應將 PCIe 交換器層的數量限制在一到兩層,以儘量減少 PCIe 延遲。
同樣地,網路介面卡和 NVMe 驅動器與 GPU,應在同一個 PCIe 交換器或 PCIe 根複合體下。在使用 PCIe 交換器的伺服器配置中,這些裝置與 GPU 應位於同一個 PCIe 交換器下,以獲得最佳效能。
選擇通過認證的系統來進行深度學習訓練
設計針對深度學習訓練進行最佳化的伺服器,是一件很複雜的事。NVIDIA 依據多年處理這些工作負載,以及與開發人員合作最佳化調整程式碼的經驗,發布了針對各類加速工作負載配置伺服器的指導方針。
NVIDIA 發展出 NVIDIA 認證系統計畫,協助各位更容易上手。系統供應商合作夥伴已使用特定的 NVIDIA GPU 和網路介面卡,配置出多種伺服器機型,且已進行測試,以驗證是否為最佳設計,為您提供最佳效能。
驗證同時包括生產部署的其他重要特色,例如可管理性、安全性和可擴充性。針對各類工作負載,已通過多個類別之系統的認證。合格系統目錄中列載了 NVIDIA 合作夥伴提供的 NVIDIA 認證系統。資料中心類別的伺服器已經通過驗證,可以提供最佳的深度學習訓練效能。
NVIDIA AI Enterprise
除適合的硬體外,企業客戶希望能針對人工智慧工作負載,選擇一套受支援的軟體解決方案。 NVIDIA AI Enterprise 是一套端到端的雲端原生人工智慧和資料分析軟體。它經過最佳化調整,使每一個組織都能妥善使用人工智慧,且經認證,可以部署在從企業資料中心到公共雲的任何地方。AI Enterprise 提供全球企業支援服務,協助人工智慧項目維持正常運作。
在使用最佳配置的伺服器上運行 NVIDIA AI Enterprise 時,各項軟硬體的投資一定能為您帶來最佳效益。
總結
在本文中,我介紹了如何針對具體運算要求,挑選深度學習訓練的企業伺服器。希望各位已經學會如何挑選最佳的組件配置,以滿足相關需求。
更多的相關資訊,請參閱下列資源: