
使用當前的運算平台來訓練最大的人工智慧模型,可能要花上數個月的時間。這對企業來說太慢了。
人工智慧、高效能運算與資料分析變得愈來愈複雜,大型語言模型這一類的模型擁有數兆個參數。
從零開始發展的 NVIDIA Hopper 架構,擁有強大的運算能力和高速記憶體,可以提高下一代人工智慧工作負載的執行速度,處理不斷擴大的網路和資料集。
全新 Hopper 架構成員之一的 Transformer Engine,將大幅提高人工智慧的效能和能力,協助在幾天或幾小時內便能完成大型模型的訓練工作。
使用 Transformer 引擎來訓練人工智慧模型
在目前 BERT 和 GPT-3 等許多廣泛使用的語言模型裡,Transformer 模型正是當中的支柱。一開始為自然語言處理用途所開發的 Transformer 模型,具有極佳的百搭性,也逐漸用在電腦視覺、藥物發現等方面。
模型一直在變大,現在已經達到擁有數兆個參數之譜。由於得進行大量計算,造成要花上數個月的時間來進行訓練,這對商業需求來說是不切實際的。
Transformer 引擎使用 16 位元浮點精度和新加入的 8 位元浮點資料格式,結合先進的軟體演算法,將進一步提高人工智慧的效能和能力。
浮點數字是決定人工智慧訓練成效的因素,浮點數有像是 3.14 這樣的小數部分。隨 NVIDIA Ampere 架構引入的 TensorFloat32(TF32)浮點格式,如今在 TensorFlow 和 PyTorch 框架中是預設的32位元格式。
大多數人工智慧浮點數學運算是使用 16 位元「半」精度(FP16)、32 位元「單」精度(FP32),還有用於特殊運算的 64 位元「雙」精度(FP64)。將數學運算減少到 8 位元,Transformer 引擎便能夠在更短時間內訓練更大的神經網路。
H100 加速的伺服器叢集加上 Hopper 架構中的其他新功能,像是直接高速互連節點的 NVLink 交換機系統,將能夠高速訓練巨大的神經網路,而這個速度是過去幾乎不可能達到企業所要求的程度。
更深入認識 Transformer 引擎
Transformer Engine 使用軟體及特別訂製的 NVIDIA Hopper Tensor Core 技術,加快使用熱門人工智慧模型構建模組 transformer 所開發出的模型訓練速度,這些 Tensor Core 可以應用混合的 FP8 和 FP16 格式,顯著提高用 transformer 開發出的人工智慧模型運算速度。FP8 中的 Tensor Core 運算處理量,是16位元運算的兩倍。
模型所面臨的難題是要如何聰明地管理及維持精度,同時獲得更小、速度更快的數字格式的效能。Transformer 引擎使用特別訂製、經 NVIDIA 調整後的啟發式演算法,做到了這一點,這個演算法可以動態選擇使用 FP8 或 FP16 運算,並且自動處理每層中這些精度之間的再次轉換和縮放。
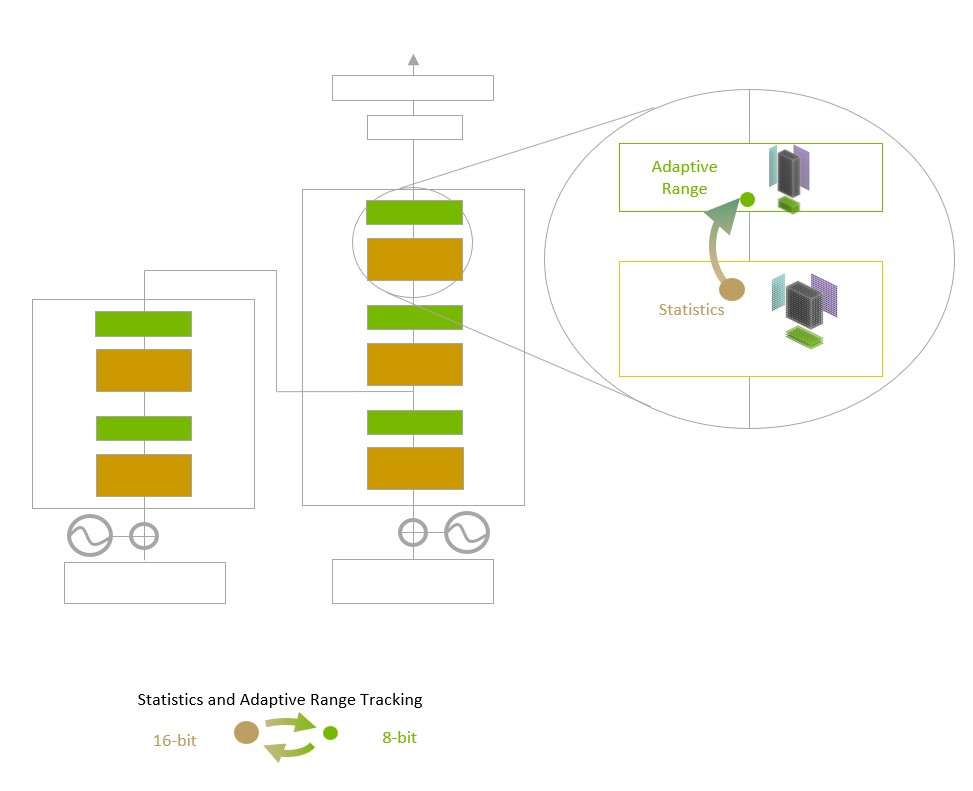
NVIDIA Hopper 架構還推動了第四代 Tensor Core 的發展,與前幾代 TF32、FP64、FP16 和 INT8 精度相比,每秒的浮點運算量增加了三倍。結合 Transformer 引擎和第四代 NVLink,Hopper Tensor Core 能夠將處理高效能運算及人工智慧工作負載的速度,提高一個量級。
加快 Transformer 引擎的速度
許多人工智慧領域的先進發展項目,都跟 Megatron 530B 等大型語言模型有關。下圖顯示了近年來模型規模不斷變大的情況,人們普遍預計這個趨勢會繼續下去。許多研究人員使用的自然語言理解及其他應用領域的模型,當中都有上兆個參數,顯示他們一直在渴求更強大的人工智慧運算能力。
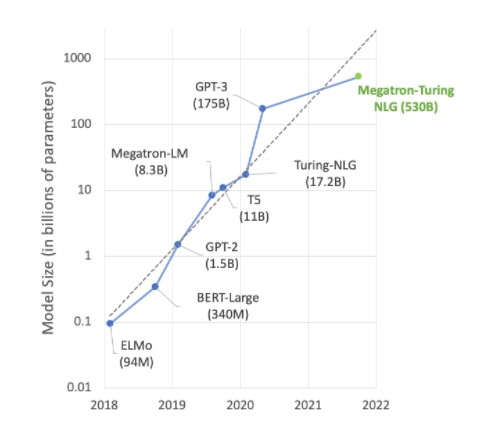
需要結合強大的運算能力與大量的高速記憶體,才能滿足這些模型的需求。NVIDIA H100 Tensor Core GPU 兼具這兩項優點,使用 Transformer 引擎來加快訓練人工智慧的速度,提升到新的水準。
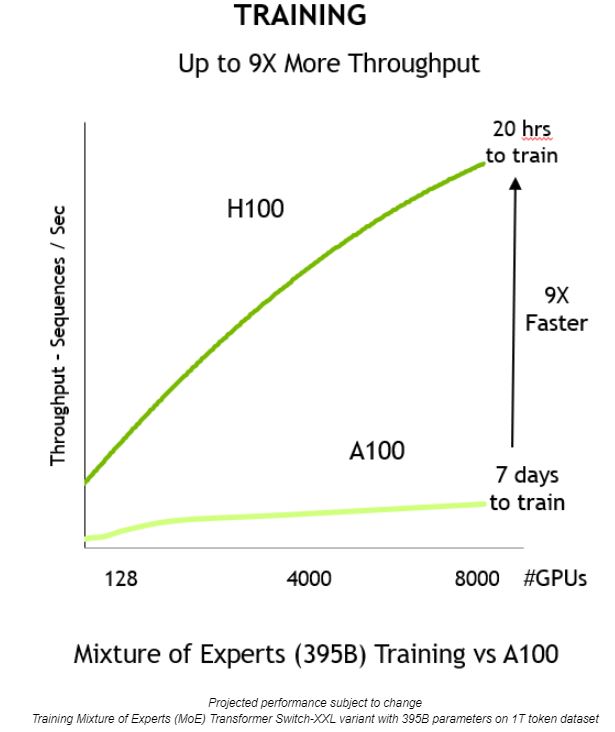
結合這些創新技術,提供更高的處理量,也將訓練時間減少九倍,從以前要數天的時間,現在只要 20 個小時便能完成:
不用轉換任何資料格式,就能將 Transformer 引擎用於推論作業。在此之前,INT8 是獲得最佳推論表現的首選精度。但是在最佳化的過程中,要把訓練好的神經網路換成 INT8 格式,而 NVIDIA TensorRT 推論優化器簡化了這件事。
開發人員使用以 FP8 訓練的模型,便無需進行轉換,並且以相同精度進行推論。就跟 INT8 格式的神經網路一樣,使用 Transformer 引擎進行部署,也使用較少的記憶體。
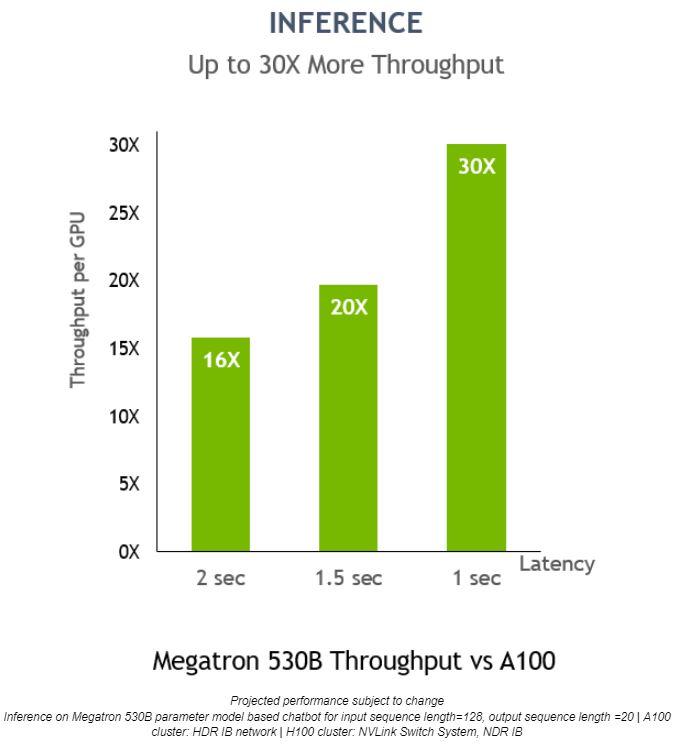
NVIDIA H100 在 Megatron 530B上的每個 GPU 推論處理量,比 NVIDIA A100 高出 30 倍,回應延遲為一秒,顯示它是用來部署人工智慧的最佳平台。
如要獲得更多關於 NVIDIA H100 GPU 與 Hopper 架構的資訊,請閱讀這篇 NVIDIA 技術部落格文章,以及 Hopper 架構白皮書。