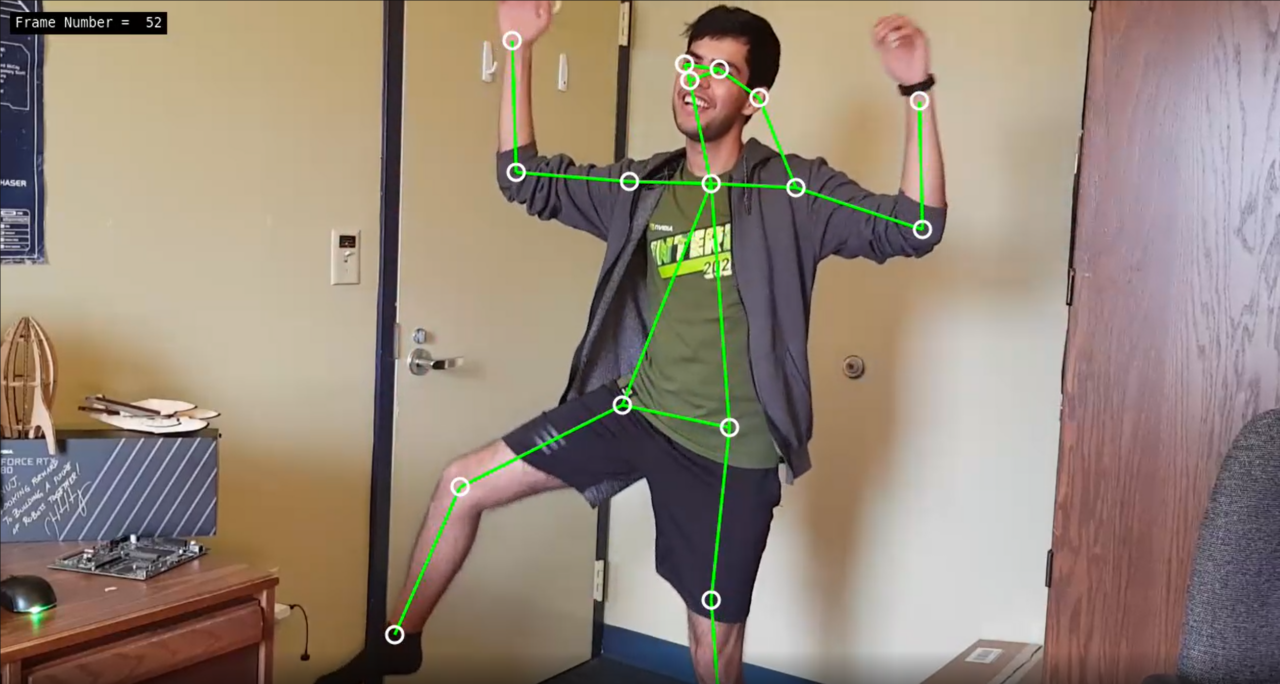
人體姿態估計是將影片或相片中人體關鍵部位定位,以估計人體輪廓(「姿態」)的電腦視覺任務。此「定位」可以預測人是站著、坐著、躺著,或正在進行某些活動,例如跳舞或跳躍。姿態估計可以做下列應用:
- 跌倒偵測-應用程式可以預測人是否跌倒而需要就醫。
- 步態分析-醫療人員評估病況且其如何影響人的行走方式。
- 動作捕捉-使用姿態估計的輸出,為 2D 和 3D 角色製作動畫。
- AR/VR-輸出用於娛樂和遊戲體驗。
您可以借助 NVIDIA DeepStream SDK,使用姿態估計做為偵測影片中之人物姿態的主要模型,然後部署次要分類模型,以偵測場景中的其他物件,進而實現一些創新的新應用。

本文探討如何利用 NVIDIA DeepStream 建立人體姿態估計應用程式。採用 DeepStream SDK 中的一個範例應用程式做為起點,並加入自訂程式碼,以使用各種姿態估計 AI 模型偵測人體姿態。將會展示 TRTPose 模型,一個開放原始碼 NVIDIA 專案,目的是利用 DeepStream,在 NVIDIA 平台和 CMU OpenPose 模型上進行即時姿態估計。
若想要開始此專案,需要 NVIDIA Jetson 平台或搭載 NVIDIA GPU 的 Linux 系統。以下是需要安裝的軟體工具套件:
如果是使用 Jetson 平台,CUDA 和 TensorRT 已做為 JetPack 的一部分預先安裝了。本文假設 $DEEPSTREAM_DIR 已安裝了 DeepStream。實際的安裝目錄可能會不同,視您使用的容器或裸機版 DeepStream 而定。
使用 DeepStream 部署姿態估計模型
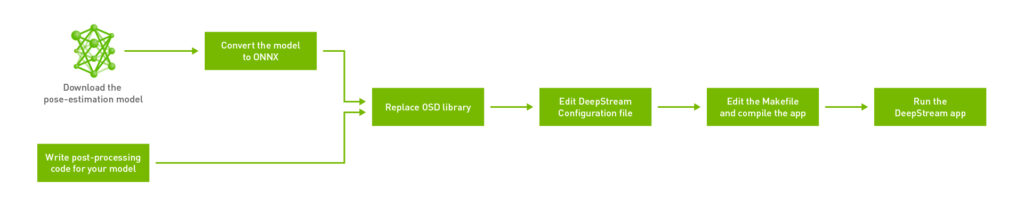
在 $DEEPSTREAM_DIR$/sources/sample_apps 上建構 DeepStream SDK 隨附的範例,以簡化流程。將工作流程分成六個主要步驟:
如果您是初次建構 GStreamer 工作流程,則 GStreamer Foundations 頁面是建構工作流程的最佳對照資源。
首先為姿態估計應用程式建立目錄。您可以在任何位置建立目錄,但是,請在 $DEEPSTREAM_DIR$/sources/apps/sample_apps/ 目錄中建立應用程式。這可確保之後在嘗試使用 makefile 編譯應用程式時,不會出現與 DeepStream 有關的符號連結問題。此示範是在 sample_apps 資料夾中建立稱為 deepstream-pose-estimation 的目錄。
步驟 1:編寫模型需要的後處理程式碼
NVIDIA-AI-IOT/deepstream_pose_estimation GitHub 儲存庫提供了此應用程式的原始碼。範例 C++ 應用程式附帶了以 DeepStream 啟用姿態估計需要的所有支援資料結構和後處理。本文會在稍後逐步說明後處理。
此應用程式的主要進入點為 deepstream_pose_estimation_app.cpp。其包含建構 GStreamer 工作流程、從模型進行推論、在原始影像上繪製輸出,以及最後乾淨地結束工作流程以退出的所有程式碼。
- post_process.cpp 包含姿態估計模型的所有後處理程式碼。
- munkres_algorithm.cpp 具有用於建置圖形配對的演算法。
- cover_table.hpp 和 pair_graph.hpp 是 Munkres 演算法需要的兩個輔助資料結構。
最後,該目錄也包含整個應用程式的 DeepStream 配置檔和 makefile。
步驟 2:下載人體姿態估計模型及轉換成 ONNX
下載 TRTPose 模型的 PyTorch 模型權重。該儲存庫是由兩個模型組成:一個在 ResNet 骨幹上,另一個在較密集的 DenseNet 骨幹上。兩個模型在不同情境下的表現不同,但是使用 DeepStream 應用程式部署兩者的方式沒有差別。
這裡是使用開放神經網路交換(ONNX)格式,以 DeepStream 部署模型。PyTorch 模型是以快速與便利的方式啟用 PyTorch 應用程式,但是通常無法在框架之間移植。請將模型權重轉換成 ONNX,以使應用程式能在 Linux 桌面以及適用於 Jetson 的 L4T 之間跨平台。
TRTPose 儲存庫隨附 Python 公用程式,可以將 PyTorch 權重轉換成 ONNX。如果您已經在系統上安裝 PyTorch,則可使用此公用程式執行轉換,如下所示:
./export_for_isaac.py --input_checkpoint resnet18_baseline_att_224x224_A_epoch_249.pth
此外,您也可以使用適用於 L4T 或 x86 的 NVIDIA NGC PyTorch Docker 容器執行匯出指令碼。首先為平台提取 Docker 容器,如下所示:
如果是 Jetson:
docker pull nvcr.io/nvidia/l4t-pytorch:r32.4.4-pth1.6-py3
如果是 NVIDIA GPU:
docker pull nvcr.io/nvidia/pytorch:20.10-py3
然後,複製 TRTPose 儲存庫,並前往容器內包含匯出指令碼的資料夾。將模型的 PyTorch 權重放入此目錄中,以匯出至 ONNX。
$ git clone https://github.com/NVIDIA-AI-IOT/trt_pose.git $ cd trt_pose/trt_pose/utils/
最後轉換模型,如下所示:
./export_for_isaac.py --input_checkpoint model_weights.pth
公用程式會在同一目錄中產生 ONNX 模型。將此模型複製到包含 DeepStream 應用程式的目錄中。若想要轉換其他模型,則可使用 PyTorch 內建的 ONNX 匯出器。欲瞭解更多與如何使用 PyTorch 在格式之間轉換有關的資訊,請參閱 torch.onnx。
步驟 3:取代 DeepStream 安裝目錄中的 OSD 函式庫
如應用程式的原始碼中所述,已針對螢幕顯示進行了一些變更,以支援此人體姿態估計應用程式。由於模型有時候會輸出視訊緩衝區框架以外的特徵點,因此我們變更了螢幕顯示,以便在繪製時忽略這些無關的值。即可在模型輸出時保持簡潔。
我們已經在儲存庫中進行這些變更,為 Jetson 和 x86 平台提供已編譯 .so 檔案。根據您的平台,將 $DEEPSTREAM_DIR$/lib/ 中的現有 libnvds_osd.so OSD 函式庫更換為儲存庫中的版本。
步驟 4:編輯 DeepStream 配置檔
DeepStream 配置檔為頂層配置檔,可以配置屬性,例如推論精度(FP16 相較於 INT8)、分配給專案的工作空間大小、實際模型位置。
在編譯之前,以參數形式,將 ONNX 檔案的位置提供給配置檔,以使應用程式知道從哪一個模型開始進行推論。
onnx-file=pose_estimation.onnx
在初次執行應用程式時,DeepStream 會產生 TensorRT 引擎檔案,可能需要幾分鐘的時間。在產生引擎檔案之後,即可提供 TensorRT 引擎檔案的路徑,以使 DeepStream 無須在後續執行時重新產生引擎檔案。
model-engine-file=pose_esimation.onnx_b1_gpu0_fp16.engine
您可以根據使用案例,配置所有非執行應用程式之必要參數的其他參數。
步驟 5:編輯 makefile 以加入平台專用的組建旗標
在編譯應用程式時,需要可以匯集所有相依性及編譯應用程式的 g++ makefile。某些相依性的位置是取決於編譯應用程式針對的目標系統。開啟 makefile,確保已正確設定 DeepStream 版本:
NVDS_VERSION:=5.0
確保 makefile 指向正確的 lib 目錄。於此情況下,lib 是位於 $DEEPSTREAM_DIR$/lib/。
LIB_INSTALL_DIR?=/opt/nvidia/deepstream/deepstream-$(NVDS_VERSION)/lib/
相較於 x86 Linux 主機,以 L4T 為基礎之電腦在應用程式中建構 GStreamer 工作流程的方式稍微不同。在 DeepStream 應用程式中導入稱為 PLATFORM_TEGRA 的旗標,並使用簡單的 if 陳述式滿足平台的要求。makefile 在開始編譯流程之前是使用 shell 自動辨識目標平台,如下所示:
TARGET_DEVICE = $(shell gcc -dumpmachine | cut -f1 -d -)
如應用程式所述,我們在 NVIDIA Jetson 工作流程中的 OSD 元素之後,加入了 nvegltransform 元素。x86 系統不需要此元素。makefile 負責啟用或停用 PLATFORM_TEGRA 旗標。
儲存庫中提供與預設 DeepStream 安裝位置對應的完整 makefile。
步驟 6:編譯和執行 DeepStream 應用程式
在正確設定 DeepStream 配置檔和 makefile 之後,即可編譯與測試應用程式。開啟新的終端機,並前往應用程式目錄:
$ cd $DEEPSTREAM_DIR/sources/apps /sample_apps/deepstream_pose_estimation
然後,使用 makefile 編譯應用程式:
$ sudo make
在 NVIDIA Jetson Xavier NX 上,編譯流程大約需要 1 分鐘的時間。
最後執行應用程式,如下所示:
$ sudo ./deepstream_pose_estimation
應用程式的輸出,在 中儲存為 Pose_Estimation.mp4。
如果未從提供給 DeepStream 的 ONNX 模型產生 .trt 引擎,則會在初次執行應用程式時建立引擎。視使用的系統而定,可能需要 4–10 分鐘的時間。TensorRT 引擎檔案是根據系統進行最佳化,且為平台專用。建議不要在系統之間共用此檔案。請讓 DeepStream 針對測試應用程式使用的每一個新系統,產生新的引擎。
人體姿態估計模型的後處理
本節將深入探討如何利用 DeepStream 為姿態估計模型進行後處理,以及建立視覺化成品。建構姿態估計模型的方法有兩種。由上而下的方法,會在畫格中偵測到之所有人類的周圍放置定界框,然後將該定界框中的各個身體部位局部化。由下而上的方法則相反。先偵測畫格中的所有人體部位,然後將屬於特定個人的部位分類。
TRTPose 是採用由下而上的方法進行姿態估計。模型會先偵測畫格中每一個身體部位的關鍵點,然後判斷該畫格中的哪些部位是屬於哪個人。
步驟 1:取得熱圖以從模型產生部位類同區域
這是應用程式的推論步驟。剖析模型輸出需要的參數,是在應用程式的 parse_objects_from_tensor_meta 方法中進行配置。此方法同時負責叫用姿態估計工作流程中的所有其他輔助方法,以及輸出最終結果。
parse_objects_from_tensor_meta (NvDsInferTensorMeta *tensor_meta)
各個畫格的原始張量輸出資料,是以 NvDsInferTensorMeta 資料類型儲存。nvInfer 外掛程式是使用 TensorRT 執行推論,以及產生輸出張量。將此原始張量輸出,並在應用程式中進行後處理,以預測人體姿態。若想要在應用程式中進行後處理時,必須在 DeepStream 配置檔中設定 output-tensor-meta 屬性,以將此外掛程式中繼資料輸出至應用程式。此元素包含重要的中繼資料,例如模型輸出層的形狀和尺寸。之後,可以將這些資料儲存至應用程式的本機資料結構中,如下所示:
void *cmap_data = tensor_meta->out_buf_ptrs_host[0]; NvDsInferDims &cmap_dims = tensor_meta->output_layers_info[0].inferDims; void *paf_data = tensor_meta->out_buf_ptrs_host[1]; NvDsInferDims &paf_dims = tensor_meta->output_layers_info[1].inferDims; parse_objects_from_tensor_meta (NvDsInferTensorMeta *tensor_meta)
模型輸出有兩個步驟。第一個步驟是針對在畫格中預測的各個身體部位,產生置信度圖。這是由下而上的方法,第二個步驟是預測各個身體部位的關聯度,以分配給特定的人。這是以稱為部位類同區域(Part Affinity Field,PAF)的矩陣表示。每一個 PAF 都有 x 方向及 y 方向分量,因此表示向量。
步驟 2:使用非最大值抑制
提供熱圖之原始輸出張量包含許多有用的資料,但是,必須使用熱圖中的最大置信度區域,並忽略所有其他不確定區域,才能從輸出中擷取身體部位。其可以透過使用非最大值抑制,尋找輸出中的所有局部最大值的方式完成。
在 find_peaks 函式中,定義 window_size 的值。 這是表示在尋找最大值或「峰值」時,需要一次考量的像素數量。在找出峰值之後,於內迴圈中使用 is_peak 布林值進行標記,並將該最大值分配給視窗的中心像素。之後重複此操作,直至涵蓋整個畫格。
find_peaks (Vec1D < int >&counts_out, Vec3D < int >&peaks_out, void
*cmap_data, NvDsInferDims & cmap_dims, float threshold, int
window_size, int max_count)
最後,僅保留畫格中的峰值,並抑制所有其他非最大像素。此步驟是以 refine_peaks 方法處理。refine_peaks 方法同時負責考量與各個身體部位有關的置信度分數權重,將較早產生的峰值正規化。此流程之後剩下的唯一值,是表示任一身體部位的最大置信度區域。
Vec3D
refine_peaks (Vec1D < int >&counts, Vec3D < int >&peaks, void *cmap_data,
NvDsInferDims & cmap_dims, int window_size)
步驟 3:建立二部圖以將偵測到的身體部位分配給畫格中的個人
在找出與細化峰值之後,必須將這些最大置信度區域分配給畫格中的個人。此時開始尋找局部化身體部位之間的關聯,以及開始針對各個畫格建構每一個人的骨骼。
在畫格中有多個人的情況下,此步驟格外重要。假設輸入的影片中有兩個人。模型將會偵測兩個右肩候選峰值及兩個右臂候選峰值。之後可針對偵測到的兩個肩部,在偵測到的兩個右臂之間建立連接。建立圖形,使兩個肩部和兩個右臂分別代表圖形中的頂點。從兩個肩部到兩個右臂以及相反方向繪製邊線。

在重複描繪偵測到之每一對可能的候選身體部位後,最後可獲得完整的二部圖。在此圖中找出正確的連接,之後將成為 NP 困難圖形配對問題。
步驟 4:為二部圖中的所有邊線分配權重
若想要在圖中之節點之間找出正確的連接,則必須先為圖中的每一條邊線分配權重。之後,可使用 Munkres 圖形配對方法解決問題。步驟 5 將詳細探討 Munkres 方法。
分配權重是以 paf_score_graph 方法處理。
Vec3D
paf_score_graph (void *paf_data, NvDsInferDims &paf_dims,
Vec2D < int >&topology, Vec1D < int >&counts,
Vec3D < float >&peaks, int num_integral_samples)
此處之分數是指分配給每一條邊線的權重。如果此分數表示部位親和場對已識別候選的影響,將會很方便。線積分正好可以達到此目的。
您可以針對各個候選對,沿著連接該對中兩個候選部位的向量計算線積分。首先,建立與儲存從 i 和 j 方向之兩個峰值點產生的向量。
float pa_i = peaks_a[a][0] * H;
float pa_j = peaks_a[a][1] * W;
for (int b = 0; b < counts_b; b++) {
// Point B
float pb_i = peaks_b[b][0] * H;
float pb_j = peaks_b[b][1] * W;
// Vector from Point A to Point B
float pab_i = pb_i - pa_i;
float pab_j = pb_j - pa_j;
將此向量正規化,如下所示:
// Normalized Vector from Point A to Point B
float pab_norm = sqrtf (pab_i * pab_i + pab_j * pab_j) + EPS;
float uab_i = pab_i / pab_norm;
float uab_j = pab_j / pab_norm;
最後,使用在 X 和 Y 方向計算出之向量的分量,計算 X 和 Y 方向之 PAF 分量點積的線積分。最終計算公式如下。將向量正規化之後,在內迴圈中計算積分。

公式中的點積計算方式,如下所示:
float dot = pt_paf_i * uab_i + pt_paf_j * uab_j;
步驟 5:使用匈牙利演算法解決分配問題
現在已具有表示所有偵測到之身體部位彼此間所有可能之連接的二部圖。接下來則是解決圖形配對問題。目標是將圖形總分最大化。使用新計算的邊線分數,解決此問題。
此種典型的分配問題有許多解決方法。TRTPose 在其建置中選擇的方法是 Munkres 或。
在程式碼中,是由munkres_algorithm 方法負責建立對圖輔助資料結構,以表示問題。
void munkres_algorithm (Vec2D < float >&cost_graph, PairGraph &
star_graph, int nrows,int ncols)
最後,是由assignment 方法負責實際分配偵測到之身體部位之間的連接。在此方法之主要迴圈的最後,將會忽略實際上不成對的連接。僅剩下可以建立有意義之連接的配對候選。
Vec3D
assignment (Vec3D < float >&score_graph,
Vec2D < int >&topology, Vec1D < int >&counts,
Float score_threshold, int max_count)
步驟 6:連接所有身體部位及形成人體骨骼
此時,已偵測到所有的身體部位,以及找出他們之間的關係。之後將所有偵測到的部位連接,並形成 2D 人體姿態。 這是使用 connect_parts 方法完成。
Vec2D
connect_parts (Vec3D < int >&connections, Vec2D < int >&topology,
Vec1D < int >&counts, int max_count)
由於已知兩個元素對之間的關係,因此僅需要在兩對之間找出具有相同身體部位的元素。之後,即可推斷他們是屬於同一個人。重複此程序,直至無任何未分配的身體部位對。
步驟 7:設定 OSD 以繪製輸出
若想要將模型輸出視覺化,請設定 DeepStream 螢幕顯示(on-screen-display,OSD),將找到正規化峰值的區域繪製成圓圈,並繪製已分配身體部位的向量。

若想要在畫面上繪製,則必須先為需要繪製的內容建立中繼資料。利用 NvDsFrameMeta 保存與 DeepStream 接收之目前畫格有關的中繼資料。除現有的中繼資料外,請加入想要在畫面上繪製的圓圈數量。
首先,使用 nvds_acquire_display_meta_from_pool 方法取得目前的中繼資料。然後,使用 nvds_add_display_meta_to_frame 方法加入您的中繼資料。應用程式中的 create_display_meta 方法會示範如何執行此操作。
static void
create_display_meta(Vec2D &objects, Vec3D &normalized_peaks,
NvDsFrameMeta *frame_meta,int frame_width,
int frame_height)
將會針對想要繪製在 OSD 上的每個正規化峰值,產生中繼資料。最後,由OSD 元素負責將最終輸出實際繪製在原始影片上。
結果
我們研究多個以 TensorRT 為基礎的姿態估計模型(例如 ResNet 224×224 和 DenseNet 256×256 模型),以及解析度為 656×368 之 CMU OpenPose 模型之間的效能比較。我們在所有的效能測量中,測量應用程式的完整端對端效能。其中包括開始針對視訊資料流進行擷取和解碼、縮小影像、從模型進行推論、後處理,以及最終在畫面上呈現輸出。輸入是可能來自於即時攝影機或檔案的單一 1080p 視訊資料流,或多個資料流。

OpenPose 的推論傳輸量最低,因為未透過 TensorRT 全面加速。DenseNet 和 ResNet 模型可使用 TensorRT 最佳化,提供明顯較高的單一資料流傳輸量。
DeepStream 能以最少的變更,從單一資料流擴充至多個資料流。我將通道密度定義為每一個裝置可以同時處理的 1080p @ 30fps 資料流數量。 在即時處理方面,每一個通道都必須以 30fps 處理。這裡僅考量兩個 TRTPose 模型,以確保最大通道傳輸量。圖 7 為兩個模型在 Jetson Xavier NX 和 NVIDIA T4 上的最大通道密度。

利用 ResNet TRTPose 模型,在 Jetson Xavier NX 上最多可以達到三個資料流,在 NVIDIA T4 上最多可以達到七個資料流。
總結
利用 DeepStream 部署姿態估計模型,有助於簡化整個工作流程。將 TensorRT 姿態估計模型與 DeepStream 結合,可以實現人體姿態估計的即時多資料流使用案例。無須擔心另外將系統資源最佳化,以進行解碼、推論、在影片上繪製或儲存輸出的問題。僅需要為模型編寫後處理程式碼、指定如何布置 GStreamer 工作流程,以及建立簡單的配置檔。
您可以使用簡單的旗標和 if 陳述式,使應用程式在 x86 與 L4T 裝置之間跨平台,並根據需求及可用平台,調整資料流的數量。將 PyTorch 模型轉換成 ONNX,有助於確保模型在不同深度學習框架之間的可移植性,並由 DeepStream 負責針對目標系統,從 ONNX 模型產生最佳化 TensorRT 推論引擎。
若需要更多資訊,請參閱以下資源: