
NVIDIA Ampere 架構使數學運算速度加倍,為各種神經網路處理提升速度。
如果你玩過疊疊樂,那麼就可以把 AI 稀疏性( sparsity )想像成是疊疊樂。
遊戲參與者首先將積木塊交錯堆疊成一座積木塔。然後,每名玩家輪流取出一塊積木,過程中玩家必須小心翼翼的,不能讓積木塔倒塌。
遊戲開始的時候,抽取積木很容易,但越往後進行就會變得越驚險,最後必定會有一名玩家在取出積木時碰倒整個積木塔。
多年來,研究人員們一直在研究如何通過稀疏性加速 AI ,其過程就像是在玩數字版的疊疊樂。他們嘗試著盡可能多地從神經網路中抽出多餘參數,同時又不破壞 AI 的超高精度。
這樣做是為了減少深度學習所需的矩陣乘法堆,進而縮短取得準確結果的時間。但到目前為止,還沒有出現大贏家。
過去,研究人員嘗試了多種技術,抽出部分的權重甚至達到了神經網路的 95%。但是,在整個過程中,他們所花的時間要遠多於他們所節省的時間,而且他們還需要付出巨大的努力來彌補精簡後的模型精度。另外,適用於一種模型的精簡方法往往並不適用於其他模型。
但如今,這一問題得到了解決。
數字稀疏
NVIDIA Ampere 架構 為NVIDIA A100 GPU帶來了第三代 Tensor Core 核心,其可以充分利用網路權值下的細粒度稀疏優勢。相較於稠密數學計算( dense math ),最大吞吐量提高了 2 倍,而且不會犧牲深度學習的矩陣乘法累加任務的精度。
測試顯示,這種稀疏方法在許多 AI 任務,包括圖像分類、目標檢測和語言翻譯中使用,都能保持與使用稠密數學計算相同的精度。該方法還已在卷積神經網路和遞歸神經網路以及基於 attention 的 transformer 上進行了測試。
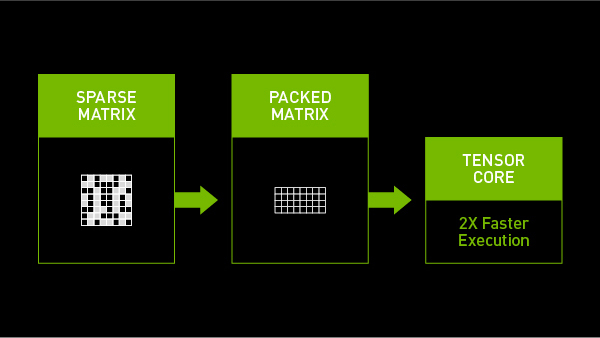
內部數學加速能夠對應用層面產生重大影響。 A100 GPU 可以利用稀疏性運行 BERT ( BERT 是最新的自然語言處理模型),其運行速度比稠密數學計算快 50%。
NVIDIA Ampere 架構利用了神經網路中小值的普遍性,讓盡可能多的 AI 應用受益。具體而言,該架構定義了一種可以減少一半權值( 50%稀疏)來訓練神經網路的方法。
少即是多,但前提是正確
一些研究人員使用粗粒度的剪枝方法從神經網路層中切斷整個通道,這往往會降低網路精度。而 NVIDIA Ampere 架構中的方法採用了結構化稀疏和細粒度修剪技術,因此不會明顯降低精度,用戶可以在重訓練模型時進行驗證。
在將網路修剪到合適狀態後, A100 GPU 將自動完成其餘工作。
A100 GPU 中的 Tensor Core 核心能夠有效地壓縮稀疏矩陣來實現合適的稠密數學計算。跳過矩陣中的實際值為零的位置能夠減少計算量,從而節省功耗和時間。壓縮稀疏矩陣還可以減少佔用寶貴的記憶體和頻寬。
要全面了解稀疏性在我們最新的 GPU 中的作用,請觀看 NVIDIA 創辦人暨執行長黃仁勳的主題演講 。 要了解更多訊息,請註冊有關稀疏性的網路研討會 ,或閱讀詳細介紹NVIDIA Ampere 架構的詳細文章 。
我們對稀疏性的支持是 NVIDIA Ampere 架構中的眾多新功能之一,可將 AI 和 HPC 性能推向新的高度。 有關更多詳細訊息,請訪問以下部落格:
- TensorFloat-32 (TF32)是一種加速格式,可加快 AI 訓練和某些 HPC 作業的速度,最高可達 20 倍。
- 雙精度 Tensor 內核(Double-Precision Tensor Cores),可將 HPC 模擬和 AI 速度提高至 2.5 倍。
- 多執行個體 GPU (MIG),最多可將 GPU 生產率提高 7 倍。
- 或者,請訪問我們的網站,介紹NVIDIA A100 GPU。