
在現今的人工智慧時代,資料是新的黑金,僅有少數幸運者能夠坐擁這口油井。許多人只好自製便宜又有效的燃料。而它就是所謂的合成資料。
什麼是合成資料?
以電腦模擬或演算法產生出且含有註釋資訊的合成資料,用來取代真實環境資料。
也就是說,是在數位環境中建立合成資料,並非在現實環境中收集或測量的資料。
從數學或統計學上來看,人造的合成資料卻也呈現出真實環境的資料。研究表明在用於訓練人工智慧模型方面,合成資料的表現跟從實際物體、事件或人身上取得的資料一樣好,甚至更好。
從這一點來看,就能明白有愈來愈多深度神經網路的開發者使用合成資料來訓練模型的原因。其實在 2019 年有一份針對該領域進行的調查,稱使用合成資料是「現代深度學習領域中前景大好的通用技術之一,尤其是依賴於圖片和影片等非結構性資料的電腦視覺。」
在這篇由俄羅斯聖彼德堡斯捷克洛夫數學研究所的 Sergey I. Nikolenko 所撰寫,內容多達 156 頁的報告中,引用了 719 篇關於合成資料的論文。Nikolenko 在結論中提到:「合成資料對於進一步發展深度學習來說,是必不可少的一項工具…[而且]還有許多潛在的使用案例有待我們發現。」
正當人工智慧領域的先驅者吳恩達(Andrew Ng)呼籲廣泛改為採用更著重於資料的機器學習方法之際,合成資料出現了。他號召人們支持資料品質的基準或競賽,許多人表示有八成得靠人工智慧才能獲得高品質的資料。
吳恩達在自己的電子報《The Batch》中寫道:「大多數基準提供了一組固定的資料,請研究人員調整程式碼反覆運算這些資料…或許現在該是固定程式碼,請研究人員拿出更好的資料來進行運算的時候了。」
資料增強與匿名 vs 合成資料
大多數開發者很熟悉把新資料加入現有真實環境資料集的資料增強技術。像是他們可能會旋轉現有影像或提高亮度,以建立一個新的影像。
人們擔心隱私外洩,加上政府政策的規定,現在普遍會拿掉資料集裡的個人資訊。這稱為資料匿名化,尤其是在金融和醫療等產業所使用的文字這種結構化資料上,匿名化的情況特別流行。
增強和匿名資料一般不視為合成資料。卻可以使用這兩種技術來建立合成資料。舉例來說,開發者可以混合兩個真實環境的汽車影像,建立一個融合兩部汽車的全新合成影像。
合成資料為何如此重要?
開發人員需要用大量精心標記的資料集來訓練神經網路。訓練資料愈是豐富多元,通常會讓人工智慧模型變得更加準確。
問題就出在收集和標記可能內有數千到數千萬個元素的資料集,是件費時耗財的工作。
按照最早一批專門提供合成資料服務業者之一 AI.Reverie 的共同創辦人 Paul Walborsky 估算,一個原本標記服務要價六美元的影像,在出現合成資料之後,以人工方式製作同樣的影像,現在只要六美分。
節省成本只不過是起點罷了。Walborsky 說:「合成資料是處理隱私問題和減少偏見的關鍵,又能確保擁有代表真實環境的各種資料。」
會自動加上標記的合成資料集,可以刻意加入罕見但關鍵的極端情況,有時候比真實環境的資料更好。
合成資料的發展歷程為何?
合成資料以各種形式存在了幾十年。它存在於飛行模擬器這樣的電腦遊戲,還有從原子到星系的科學模擬中。
哈佛大學統計學教授 Donald B. Rubin 在幫助美國政府各部門解決諸如在人口普查中,特別是對貧困人口數量不足的問題時,突然想到一個辦法。他在1993年的一篇論文中描述了這個辦法,這篇論文經常被稱為合成資料的起源。
「我在那篇論文中使用了合成資料一詞,指的是多個模擬資料集。」Rubin 這麼解釋。
他說:「看起來像是透過跟建立實際資料集一樣的步驟,建立出每一個合成資料,卻又沒有哪一個合成資料集裡透露出任何真實資料 – 這在研究個人機密資料集時,有著莫大的好處。」

在出現人工智慧大爆炸之後,也就是在2012年的那場 ImageNet 比賽中,發現神經網路辨識物體的速度比人類還要更快,研究人員開始認真尋找合成資料。
在這幾年間,「研究人員在實驗中使用渲染出的影像,結果相當好,人們開始投入研發產品和工具,用他們的 3D 引擎及內容管道來產生資料。」NVIDIA 模擬技術與人工智慧部門資深總監 Gavriel State 說。
福特、BMW 等車廠產生合成資料
銀行、汽車製造商、無人機、工廠、醫院、零售商、機器人與科學家,如今都在使用合成資料。
在 NVIDIA 最近某一集的 podcast 節目裡,福特的研究人員介紹了他們怎麼結合遊戲引擎與生成對抗網路(GAN),以建立訓練人工智慧的合成資料。
BMW 使用 NVIDIA Omniverse 來建立一座虛擬工廠,不同公司可以在這個模擬平台使用多種工具進行協同作業,以最佳化調整該公司的車輛製程。BMW 產生出的資料有助於微調裝配工人與機器人之間相互配合的情況,以提高車輛的生產效率。
在醫院、銀行及商店使用合成資料
醫學影像等領域的醫療機構使用合成資料來訓練人工智慧模型,同時保護病患的隱私。像是新創公司 Curai 使用四十萬個模擬病例來訓練一個診斷模型。
Nikolenko 在其 2019 年的調查報告中表示:「以 GAN 為基礎的醫學影像架構,無論是產生合成資料[還是]改編來自其他領域的真實資料…都將在未來幾年內訂定該領域的技術水準。」
金融領域也開始重視 GAN。美國運通研究了如何使用 GAN 來建立合成資料,以改進其用於偵測詐欺活動的人工智慧模型。
新創公司 Caper 等零售業者利用 3D 模擬技術,對一個產品拍攝至少五張照片,並且建立一個內有一千張照片的合成資料集。這樣子的資料集有助於發展出智慧商店,消費者只要拿到他們需要的東西,便能直接出門,無需排隊等待結帳。
如何建立合成資料?
NVIDIA 的 State 表示:「有無數種可以用來產生合成資料的技術」。例如使用變分自編碼器壓縮資料集的大小,接著使用解碼器產生出一個相關的合成資料集。
儘管 GAN 開始受到歡迎,特別是在研究領域,但從兩個原因來看,模擬仍然是一個熱門的選擇。它們支援許多工具來分割及分類靜態和動態影像,產生出完美的標籤。它們還能快速產生出有著不同顏色、照明、材料與姿勢版本的物體和環境。
最後一項能力提供了對域隨機化技術來說極為重要的合成資料,如今使用這項技術來提高人工智慧模型準確性的情況也日漸普遍。
專家提示:使用域隨機化
域隨機化對一個物體及其環境進行千變萬化的調整,人工智慧模型才能更容易地理解一般模式。在以下的影片中介紹了智慧倉庫如何透過域隨機化技術來訓練人工智慧機器人。
域隨機化技術有助於縮小所謂的域差距 – 要是使用在某一天剛好遇到的確切情況來訓練人工智慧模型,它便無法做出完美的預測。這正是 NVIDIA 把合成資料生成工具的域隨機化納入 Omniverse 的原因,日前在 GTC 大會的一場演講中有提到這件事。
這類技術有助於讓電腦視覺應用程式,從原本只能偵測及分類影像中的物體,變成能夠看到和理解影片中的活動。
「市場正朝著這個方向發展,不過技術更加複雜。合成資料在這裡更有價值,它可以讓你在影片的每一個畫面全部加上註釋。」AI.Reverie 的 Walborsky 說。
我在哪裡可以拿到合成資料?
這個業界發展的時間不過幾年,現已有五十多間公司提供合成資料。每一間都有自己的特色,往往鎖定一個特定的垂直市場或技術。
比如有幾間專門服務醫療保健領域。有六間提供開放源碼工具或資料集,當中包括麻省理工學院所開發出的一套函式庫、專案和教學內容 Synthetic Data Vault。
NVIDIA 的目標是跟眾多合成資料及資料標籤服務業者合作。最新的合作夥伴有:
- 紐約的 Reverie 提供帶有可配置感應器的模擬環境,用戶可以收集自己的資料集,該公司已經在農業、智慧城市、安全與製造業等領域開展了大型專案。
- 倫敦的 Sky Engine 開發適用於各市場的電腦視覺應用程式,協助用戶設計自己的資料科學工作流程。
- 以色列的Datagen 從模擬環境中建立適用智慧商店、機器人,還有用於汽車和建築物內裝設計等市場的合成資料。
- CVEDIA的客戶包括 Airbus、Honeywell 及 Siemens,可以使用該公司提供的自訂工具,將合成資料用在電腦視覺上。
使用 Omniverse 開闢市場
NVIDIA 的目標是透過 Omniverse,讓各行各業有興趣在虛擬環境中進行創作或合作的設計師及程式設計師人數不斷增加。產生合成資料是 NVIDIA 預計在 Omniverse 中開展的眾多業務之一。
NVIDIA 為機器人領域在 Omniverse 中發展出 Isaac Sim 這項應用程式。使用者可以在這個虛擬環境中使用合成資料和域隨機化技術來訓練機器人,並且將產生出的軟體部署到在現實環境中的機器人上面。
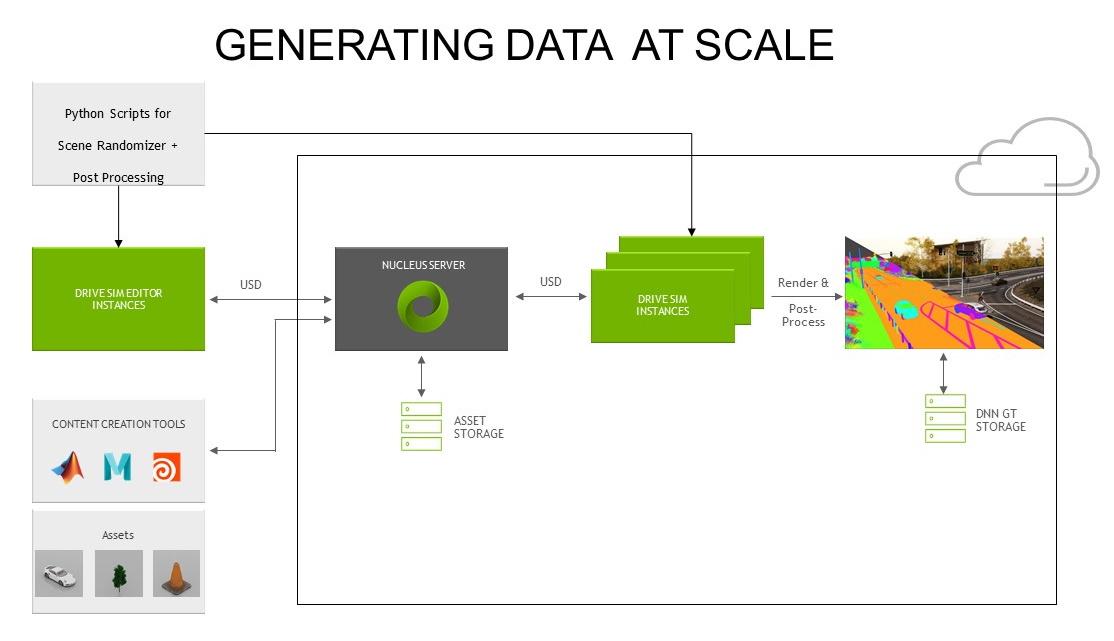
Omniverse 支持垂直市場的多種應用程式,像是用於自動駕駛車的 NVIDIA DRIVE Sim。開發者可以在安全逼真的模擬環境中測試自動駕駛車,就算在疫情期間也能產生出有用的資料集。
透過這些最新的應用範例,可以看到如何在模擬環境中將合成資料用在人工智慧上。
深入瞭解合成資料
以下資源提供更多合成資料相關資訊:
-
- O’Reilly 與 NVIDIA 出版的電子書,介紹如何將合成資料用在人工智慧領域
- GTC 2019 大會一場關於合成資料的演講,主講人為 NVIDIA 模擬技術部門副總裁 Rev Lebaredian(免費,需報名)
- 2021年發表四篇關於合成資料的 NVIDIA 開發者部落格文章
- 加拿大豐業銀行與阿爾伯塔大學在 GTC 2021 大會上發表的一篇關於使用生成模型來建立合成資料的研究報告研究報告(免費,需報名)
- 在 Omniverse 上產生合成資料的範例(附程式碼樣本)