如果您想要搭上人工智慧的下一波浪潮,就立刻選擇 Transformer 吧。
Transformer 不是電視上會變形的玩具機器人,也不是電線杆上像垃圾桶的箱子。
那麼,什麼是 Transformer 模型呢?
Transformer 模型是一種神經網路,藉由追蹤序列資料中的關係,學習上下文之間的脈絡及意義,就如同句子中的每一個字。
Transformer 模型是使用一套不斷發展,稱為注意力(attention)或自我注意力(self-attention)的數學技術,它可偵測一個系列中以微妙方式相互影響和相互依賴的資料元素,甚至是模糊的資料元素。
Google 在 2017 年的一篇論文中,首次提到 Transformer 模型是迄今發明出最新且最強大的模型之一。Transformer 模型在推動機器學習不斷進步,有些人稱其為 Transformer 人工智慧。
在 2021 年 8 月的一篇論文中,史丹佛大學的研究人員將 Transformer 模型稱為「基礎模型」,他們認為這些模型推動了人工智慧的典範移轉。他們寫道:「在過去幾年,基礎模型之規模和範圍擴大了我們對可能性的想像。」
Transformer 模型可以做什麼?
Transformer 模型以幾乎即時的方式翻譯文字和語音,讓各種背景的人士及聽障者都能出席會議和上學。
Transformer 模型也可以協助研究人員瞭解 DNA 中的基因鏈和蛋白質中的氨基酸,以加快設計藥物的腳步。
Transformer 模型可以偵測趨勢和異常情況,以防止詐欺活動、簡化製造流程、進行線上推薦或提供更好的醫療服務。
人們在每一次使用 Google 或 Microsoft Bing 進行搜尋時,都會用到 Transformer 模型。
Transformer AI 的良性循環
任何使用序列文字、影像或影片資料的應用程式,都可能會使用到 Transformer 模型。
將能使這些模型在 Transformer AI 中實現良性循環。使用大型資料集建立模型,Transformer 模型可以做出準確的預測,以推動產生更廣泛的使用、產生更多的資料,進而創造出更好的模型。
「Transformer 模型讓我們可以做到自我監督學習,以及快速發展人工智慧。」NVIDIA 創辦人暨執行長黃仁勳在 2022 年舉行的 GTC 大會主題演講中表示。
Transformer 取代 CNN、RNN
在許多情況下,Transformer 模型已開始取代五年前最熱門的深度學習模型,即卷積和遞歸神經網路(CNN 和 RNN)。
事實上在過去兩年,arXiv 網站上發表與人工智慧有關的論文中,70% 都提到了 Transformer 模型。其結果與 2017 年 IEEE 的一項宣稱 RNN 和 CNN 為最熱門之模式辨識模型的研究報告截然不同。
無標籤且效能更高
在 Transformer 問世之前,用戶必須使用加上標籤的大型資料集訓練神經網路,而產生此類資料集的成本很高,且需要耗費許多時間。Transformer 模型是透過數學尋找元素之間的模式,無須使用加上標籤的大型資料集,即可妥善利用網路和企業資料庫中的海量影像及文字資料。
此外,Transformer 模型使用的數學技術適合進行平行運算,使這些模型可以快速運行。
現在,SuperGLUE 等目前熱門的效能排行榜都是由 Transformer 主導,例如 SuperGLUE 是 2019 年針對語言處理系統開發的基準。
Transformer 如何應用注意力(Attention)數學技術
Transformer 模型與大多數神經網路一樣,基本上是處理資料的大型編碼器/解碼器模塊。
在這些模塊中加入小型而具有策略意義的項目(如下圖所示),使 Transformer 模型具有獨特的強大功能。
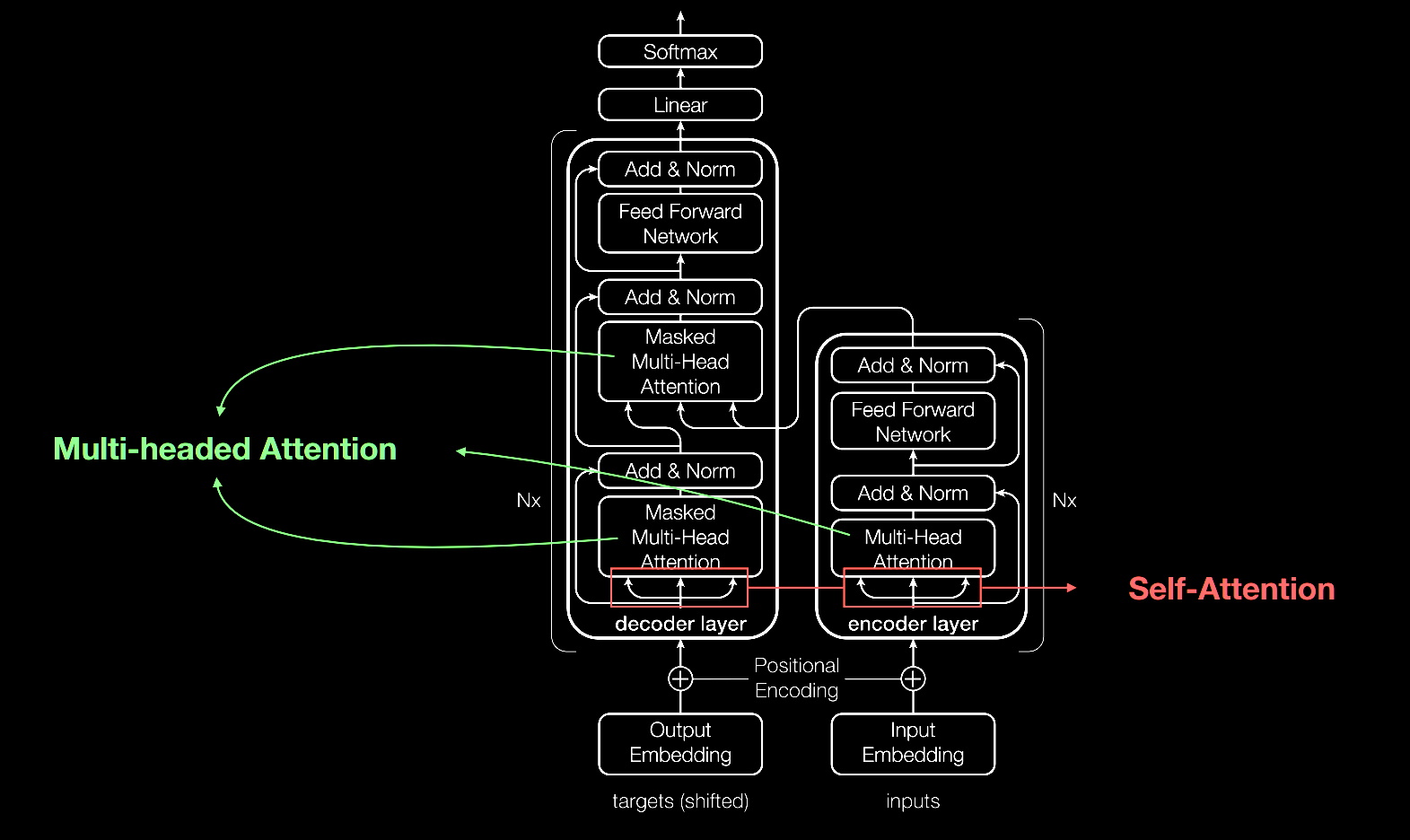
Transformer 模型是使用位置編碼器標記進出網路的資料元素。Attention 單元追蹤這些標籤,計算出一種代數圖,說明各元素之間的關係。
通常是在所謂的多頭注意力(multi-headed attention)中計算一個方程式矩陣,以平行執行 attention 查詢。
電腦使用這些工具,可以看到與人類看到的相同模式。
自我注意力(Self-Attention)發現意義
例如,在這一個句子中:
She poured water from the pitcher to the cup until it was full.(她將水罐中的水倒入杯子,直至它滿了為止。)
我們知道此句中的「it」是指杯子,而在這一個句子中:
She poured water from the pitcher to the cup until it was empty.(她將水罐中的水倒入杯子,直至它空了為止。)
我們知道此句中的「it」是指水罐。
「意義是事物間之關係的結果,而自我注意力(self-attention)是一般學習關係的方式,」Google Brain 前資深研究科學家,帶領進行 2017 年該篇開創性論文的 Ashish Vaswani 表示。
「您需要文字之間的短距離和長距離關係,而機器翻譯是驗證 self-attention 的絕佳工具。」Vaswani 說。
「現在,我們已看到 self-attention 變成一項強大、靈活的學習工具。」他補充道。
Transformer 名稱的由來
Attention 對 Transformer 模型來說十分重要,導致 Google 的研究人員差一點使用這一個字做為 2017 年模型的名字。
「Attention Net 的名字聽起來很無趣。」在 2011 年開始研究神經網路的 Vaswani 說。
團隊中的資深軟體工程師 Jakob Uszkoreit 建議採用 Transformer 做為其名稱。
「我認為我們正在改變一個表現形式,但是只是在玩語義遊戲。」Vaswani 說。
Transformer 的誕生
Google 團隊在 2017 年 NeurIPS 大會上提出的論文中,描述了他們的 Transformer 模型,以及它在機器翻譯方面創造的準確性紀錄。
在多項技術的協助下,他們僅使用 3.5 天即在 8 個 NVIDIA GPU 上訓練出模型,花費的時間和成本還不到先前訓練模型的一小部分。他們使用包含多達 10 億筆單字的資料集訓練模型。
「我們在論文提交日截止之前,緊張地奮鬥了三個月。」2017 年參與此項工作的 Google 實習生 Aidan Gomez 回憶說。
「在提交論文的那一天晚上,Ashish 和我在 Google 加班了一整晚。」他說。「我在一間小會議室中睡了幾個小時,有人提早來上班,打開門撞到了我的頭,我醒來時正好趕上提交的時間。」
它在很多方面都會讓人醒過來。
「那一天晚上,Ashish 告訴我,他相信這將會是一件改變遊戲規則的大事。我不相信,我認為這一次的基準測試結果還好而已,但是,事實證明他是對的。」Gomez 說,他現在是提供以 Transformer 模型為基礎的語言處理服務之新創公司 Cohere 的執行長。
機器學習的重要時刻
Vaswani 回憶,當他看到結果比 Facebook 團隊使用 CNN 發表的類似成果更好時,內心無比激動。
「我可以預見這在機器學習方面,可能是一個重要時刻。」他說。
在一年後,Google 的另一支團隊嘗試使用 Transformer 模型處理正向和反向文字序列。將有助於更深入捕捉文字之間的關係,提高模型理解句子含義的能力。
他們的 Bidirectional Encoder Representations from Transformers(BERT)模型創造了 11 項新紀錄,並成為 Google 搜尋服務背後之演算法的一環。
短短數週內,各地的研究人員已將 BERT 使用在許多語言和產業的使用案例中,「文字是公司最常見的資料類型之一。」從事機器學習研究達 20 年資歷的 Anders Arpteg 表示。
將 Transformer 模型投入使用
很快地,Transformer 模型已開始運用在科學和醫療領域中。
近期,在《自然》雜誌的一篇文章中描述了倫敦的 DeepMind 公司,使用名為 AlphaFold2 的 Transformer 模型,更深入認識組成生命的蛋白質。它使用如同處理文字字串般的方式處理氨基酸鏈,為描述之蛋白質的折疊方式,訂定了新的高度,以使此項工作可以加速藥物發現。
AstraZeneca 與 NVIDIA 合作開發出 MegaMolBART,一款為藥物發現量身打造的 Transformer 模型。它是 AstraZeneca 藥廠旗下名為 MolBART 之 Transformer 模型的一個版本,使用 NVIDIA Megatron 框架建立大規模的 Transformer 模型,使用無標記的大型化合物資料庫進行訓練。
閱讀分子與病歷
「如同人工智慧語言模型學習句子中各單字之間的關係,我們的目標是可以使用分子結構資料訓練出的神經網路,學習實體分子中各原子之間的關係。」AstraZeneca 公司分子人工智慧、發現科學與研發部門負責人 Ola Engkvist,在去年宣布此項成果時表示。
此外,佛羅里達大學的學術健康中心與 NVIDIA 的研究人員合作開發出 GatorTron。此 Transformer 模型可以從大量臨床資料中提取寶貴見解,以加快推動醫學研究的腳步。
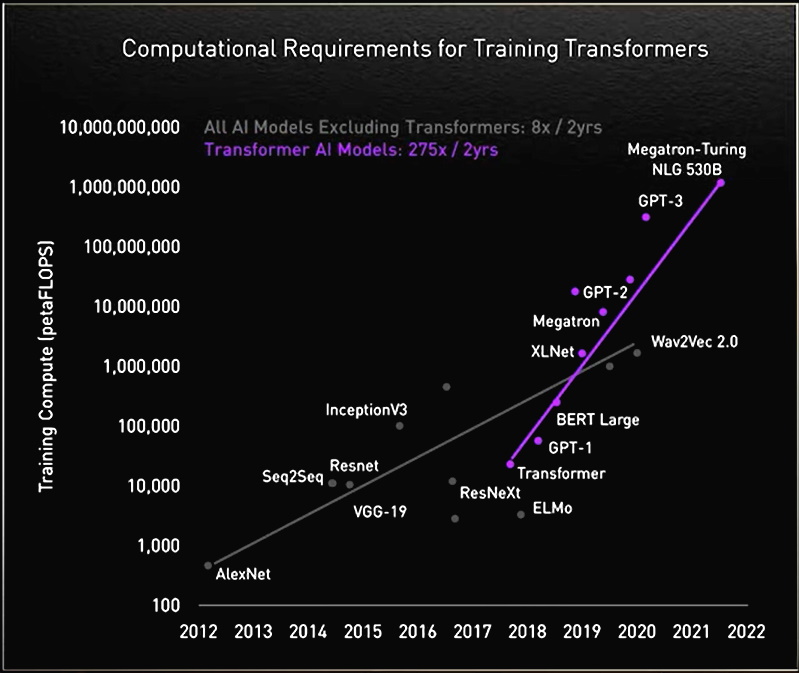
Transformer 模型成長茁壯
在過程中,研究人員發現更大的 Transformer 模型擁有更好的表現。
例如慕尼黑工業大學 Rostlab 的研究人員,協助在跨足人工智慧與生物學之領域中進行開創性的研究工作,使用自然語言處理技術理解蛋白質。他們在 18 個月內,從使用具有 9,000 萬個參數的 RNNs,至使用具有 5.67 億個參數的 Transformer 模型。
OpenAI 實驗室透過 Generative Pretrained Transformer(GPT),表現出愈大愈好的特性。最新版本的 GPT-3 具有 1,750 億個參數,高於 GPT-2 的 15 億個參數。
高出這麼多參數,使 GPT-3 甚至可以回應用戶的查詢,即使是未經過專門訓練的任務也沒問題。目前已有許多公司使用,包括 Cisco、IBM 和 Salesforce。
巨型 Transformer 模型的故事
去年 11 月,NVIDIA 與微軟創下雙方合作的高點,宣布推出具有 5,300 億個參數的 Megatron-Turing 自然語言生成模型(MT-NLG)。此模型與 NVIDIA NeMo Megatron 的全新框架一起亮相,目的是協助任何企業自行建立擁有十億個或上兆個參數的 Transformer 模型,以支援自訂的聊天機器人、個人助理和其他可以理解語言的人工智慧應用程式。
在 NVIDIA 2021年11月的 GTC 大會主題演講中,MT-NLG 便是當中首次公開亮相之 Toy Jensen 的大腦。
「當執行長黃仁勳對外展現我們研究成果的實力時,我們在看到 Toy Jensen 回答問題後,感到激動不已。」率領 NVIDIA 團隊訓練該模型的 Mostofa Patwary 說。

心臟不夠強健的人,絕對不要嘗試建立此類模型。MT-NLG 模型是使用數千億個的資料元素,加上數千顆 GPU 運行數週訓練而成。
「訓練大型 Transformer 模型既耗費成本又耗時,如果第一次或第二次沒有成功,此項目就可能會遭到取消。」Patwary 說。
上兆個參數的 Transformer 模型
今日,許多人工智慧工程師都正在開發具有上兆個參數的 Transformer 模型和應用程式。
「我們一直在探索這些巨大的模型如何提供更好的應用程式。我們同時在調查此類模型無效的方面,以便能建立更好、更大的模型。」Patwary 表示。
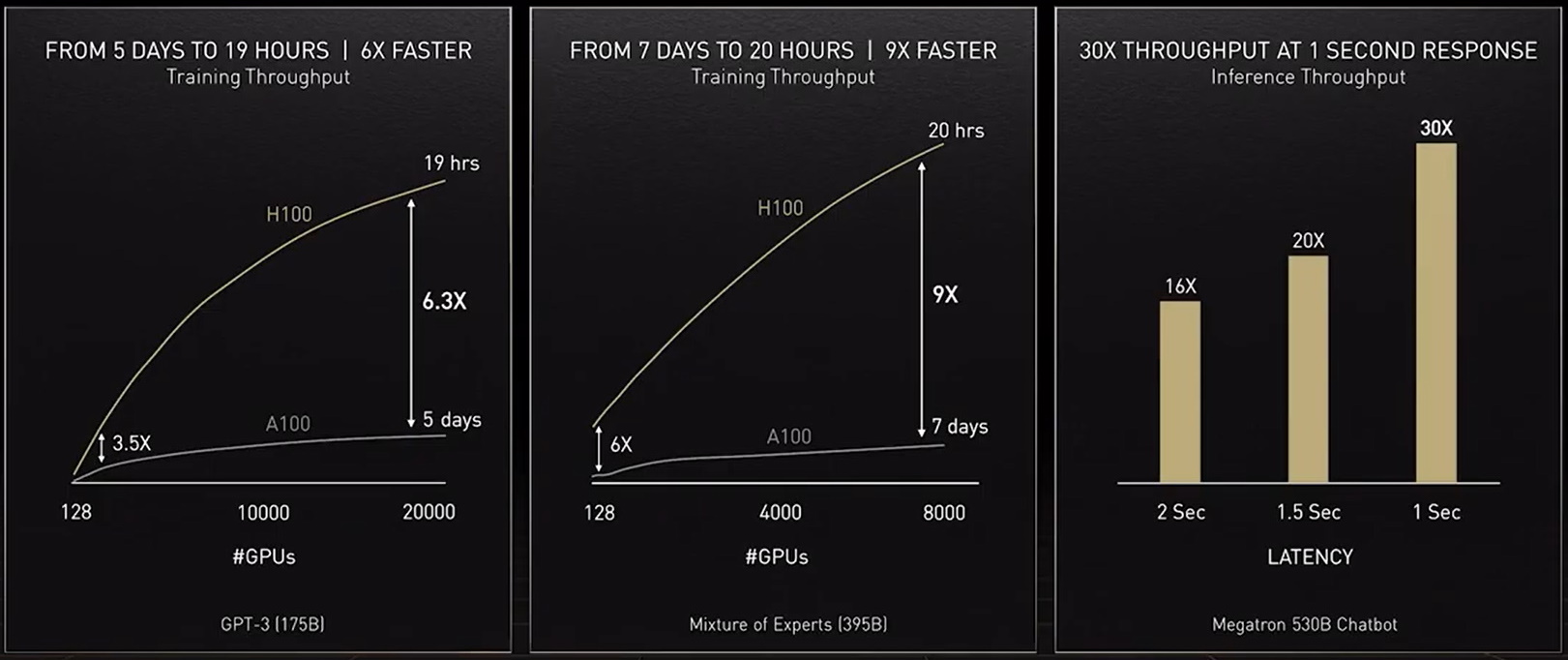
為了提供這些模型需要的運算能力,我們最新的加速器 NVIDIA H100 Tensor 核心 GPU 內含一個 Transformer Engine,並可支援新的 FP8 格式。將能保持精度,同時加快訓練速度。
這些進步加起來,「可以將訓練 Transformer 模型的時間,從數週縮短為數天。」黃仁勳在 GTC 大會上表示。
專家混合系統(MoE)代表 Transformer 模型可以做更多
去年,Google 研究人員推出同樣具有上兆個參數的 Switch Transformer 模型。它使用人工智慧的稀疏性、複雜的專家混合系統(mixture-of experts,MoE)架構以及其他進展,推動提高語言處理的效能,將預先訓練的速度提高 7 倍。
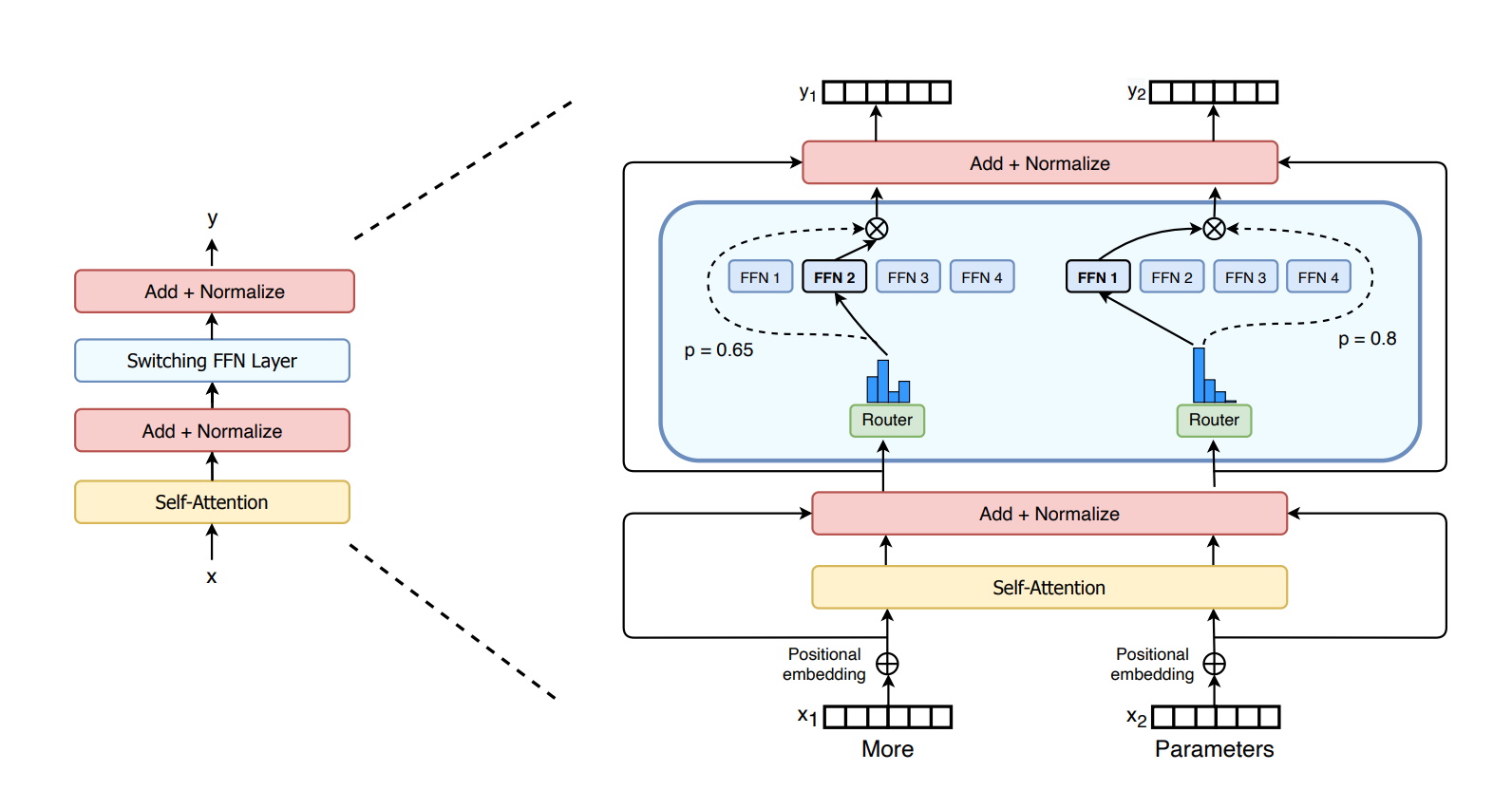
微軟 Azure 與 NVIDIA 合作,為其 Translator 服務實行 MoE Transformer 模型。
解決 Transformer 模型面臨的挑戰
現在,部分研究人員想要開發參數更少、更精簡的 Transformer 模型,以提供與最大模型相似的效能。
「我看到了檢索式模型的前景,且對此非常興奮,因為它們可以彎曲曲線。」Cohere 公司的 Gomez,以 DeepMind 公司的 Retro 模型為例表示。
檢索式模型是透過提交查詢給資料庫以進行學習。他說:「真的超棒,因為可以挑選放在知識庫中的內容。」
最終目標是「僅需要少數資料,即能讓這些模型如同人類般利用現實環境的脈絡背景進行學習。」一間低調人工智慧新創公司的共同創辦人 Vaswani 說。
他預期未來的模型會在前期先進行更多運算工作,所以無須使用大量資料,且可提供更好的使用者回饋方式。
「我們的目標是建立可以在日常生活中協助人們的模型。」他在談論本身的創新公司時表示。
安全負責任的模型
其他研究人員正在研究當模型放大錯誤或有害的語言時,如何消除偏見或有害之處。舉列來說,史丹佛大學成立了基礎模型研究中心探索此類問題。
「這些是在安全部署模型時需要解決的重要問題。」該領域的眾多業內人士之一,NVIDIA 的研究科學家 Shrimai Prabhumoye 說。
「現在,大多數模型都在尋找某些字詞或句子,但是在現實生活中,不一定能察覺到這些問題,所以我們必須考慮整個脈絡。」Prabhumoye 補充道。
「Cohere 同樣特別注意此點。」Gomez 說。「如果這些模型會傷害到人們,將沒有人會使用它們,所以當務之急是製作最安全和最負責任的模型。」
擴大眼界
Vaswani 預想未來發展的自我學習、在 Attention 支援下的 Transformer 模型,會更接近人工智慧的最終目標。
「我們有機會實現人們在創造『通用人工智慧』一詞時談到一些目標,我發現這一顆北極星非常鼓舞人心。」他說。
「在我們如今身處的時代中,神經網路的簡單方法為我們帶來許多新的能力。」